factorization专题

翻译论文的关键部分 | Parallel Tiled QR Factorization for Multicore Architectures
SSRFB DTSQT2 DLARFB DGEQT2 1, 对角子矩阵分解 DGEQT2 这个例程被开发出来,用于针对对角Tile子矩阵: ,执行不分块的QR分解。 这个运算产生: 一个上三角矩阵 一个酉下三角矩阵,这个矩阵包含 b 个 Householder 反光面、 一个上三角矩阵 ,在WY技术中,这个矩阵被定义用来累计Householder变换。 和 能够写进 所占据的内存空间,

CV-CNN-2015:GoogleNet-V3【贡献:卷积核分解(Factorization)减少参数量,比如将7x7分解成两个一维的卷积(1x7,7x1)】【避免表达瓶颈,更深】
Inception V3一个最重要的改进是分解(Factorization),将7x7分解成两个一维的卷积(1x7,7x1),3x3也是一样(1x3,3x1),这样的好处,既可以加速计算,又可以将1个卷积拆成2个卷积,使得网络深度进一步增加,增加了网络的非线性(每增加一层都要进行ReLU)。 另外,网络输入从224x224变为了299x299。 参考资料: CNN模型合集 | 7
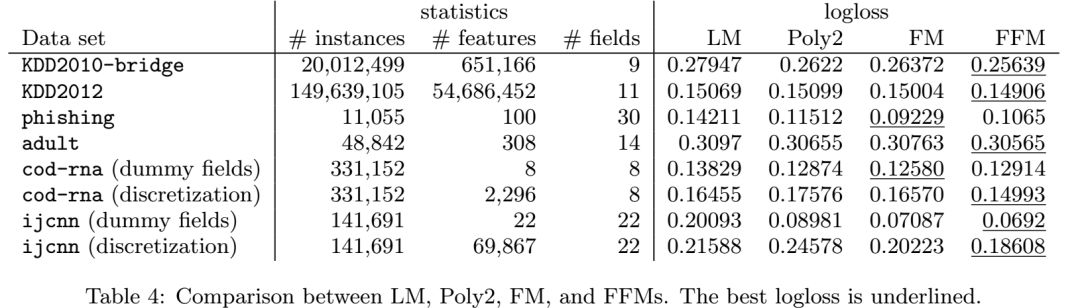
点击率预测《Field-aware Factorization Machines for CTR Prediction》论文精读
请点击上方“AI公园”,关注公众号 上次发的这篇文章,由于排版的问题,导致了部分手机无法正常显示公式,经过几个朋友提醒才发现,今天重新发布一次。 摘要:点击率预测在计算机广告中有着重要的作用。在这个应用中,二阶多项式映射和因子分解模型应用的非常广泛。最近,各种种类的因子分解机(FM),领域因子分解机(FFM)在各个点击率预测的竞赛中表现出了其他模型都好的效果。基于我们获胜的经验,本文我们建立了
推荐系统《Field-aware Factorization Machines for CTR Prediction》 论文精读
之前一篇文中说提到了FFM,那么我们今天就来看看FFM是个什么东西,它和FM又是什么关系。 摘要:点击率预测在计算机广告中有着重要的作用。在这个应用中,二阶多项式映射和因子分解模型应用的非常广泛。最近,各种种类的因子分解机(FM),领域因子分解机(FFM)在各个点击率预测的竞赛中表现出了其他模型都好的效果。基于我们获胜的经验,本文我们建立了对大型的稀疏数据集进行点击率预测的方法FFM。首先,我们
推荐系统之《Factorization Machines》论文精读
本文是AI公园公众号的第一篇,希望从今天开始,AI公园能够陪伴大家一起学习和工作。 本公众号将以原创为主,如果大家喜欢的话,请点击上方“AI公园”并关注。谢谢大家支持! 推荐系统是目前AI应用的非常成熟的领域,而且也取得了非常好的效果,而在很多推荐系统的场景中,我们会非常普遍的用到one-hot编码之类的方法,这就导致了我们的输入特征会变的非常的稀
![NMF(non-negative matrix factorization)相关论文[1]](https://img-blog.csdn.net/20170512153946221?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvdTAxMDEzODA1NQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)
NMF(non-negative matrix factorization)相关论文[1]
部分非负矩阵分解论文的总结,在做相关工作的童鞋的可以互相交流下~! Guan N, Tao D, Luo Z, et al. Online non-negative matrix factorization with robust stochastic approximation[J]. IEEE Transactions on Neural Networks & Learning Syste

联邦学习论文阅读:Secure Federated Matrix Factorization
这是六月刚刚挂上arXiv的文章,杨老师学生的工作 link 代码 摘要 这篇文章提出了联邦化的矩阵分解算法,作者发现传梯度也会泄露信息,所以利用同态加密来进一步保证用户数据的隐私性。 框架 基本框架和federated collaborative filtering那篇文章是一样的:一个标准的横向联邦框架,user vector保留在本地训练,只上传加密后的更新梯度,服务器进行汇总,然
1103 Integer Factorization (30 分) dfs 剪枝
The K−P factorization of a positive integer N is to write N as the sum of the P-th power of K positive integers. You are supposed to write a program to find the K−P factorization of N for any positive

PAT A1103 Integer Factorization ——如果你愿意一层一层一层的剥开我的心~
PAT A1103 Integer Factorization 此题简单的描述不禁使我浮想联翩,质因数分解啦,几次方再求和怎么处理啦,遍历的范围和定位啦。。。最后终于步入正轨,应该先把N范围以内的K次方先放到数组里边备选,于是就变成了从一个有序数组中挑选M个数字使之总和=N(不是连续子序列有点可惜)。开始想用hash数组定位K次方数,从N开始倒着循环,搞到一半发现每个数都是可以取多次的,我这一个
xtu oj 1377 Factorization
Factorization 题目描述 根据质因子唯一分解定理可知n=pk11pk22…pkmm,其中pi都是质数。我们定义f(n)=m, 求g(a,b)=∑bi=af(i)。 输入 第一行是一个整数T(1≤T≤1000),表示样例的个数。 以后每个样例占一行,为两个整数 a(2≤a≤b≤106)。 输出 依次每行输出一个样例的结果,为一个整数。 样例输入 2 2 2 2 10 样例输出 1
1103. Integer Factorization (30)[递归遍历+剪枝]
1. 原题: https://www.patest.cn/contests/pat-a-practise/1103 2. 思路: 题意: 判断一个数能否分解成N个因子的p次方的和。 若是,求出最大的N个因子和。 有多个相同最大和,输出较大的那个序列。比如 1) 1, 2, 3, 5 2) 1, 2, 4, 4 则输出第二种。 递归剪枝题。 思路: 题意并不算多难,但是如何转
【论文阅读】MATRIX FACTORIZATION TECHNIQUES FOR RECOMMENDER SYSTEMS
目录 论文 背景 1.RECOMMENDER SYSTEM STRATEGIES(推荐系统策略) 1.1内容过滤 1.2协同过滤(Collaborative filtering) 2.MATRIX FACTORIZATION METHODS(矩阵分解方法) 3.A BASIC MATRIX FACTORZATION MODEL(一个基本的矩阵分解模型) 4.LEARNING ALG

推荐算法-矩阵分解(Matrix Factorization,MF)
常用的推荐算法 基于协同过滤的推荐算法是主流思想之一; 基于模型与基于领域的推荐算法之间的区别为:基于领域的协同过滤是将用户的数据读入到内存中进行运算,也称为基于内存的协同过滤(Memory-based)。数据量少的情况下,可以在线实时推荐;基于模型的推荐(Model-based),采用机器学习的方式,分成训练集和测试集。离线训练时间比较长,但训练完成后,推荐过程比较快。 隐语义模型是指通过挖

推荐算法模型 ----- Attentional Factorization Machines 论文阅读笔记
论文名字:Attentional Factorization Machines:Learning the Weight of Feature Interactions via Attention Network 论文地址:http://staff.ustc.edu.cn/~hexn/papers/ijcai17-afm.pdf 若有错误或不足,烦请各位dalao指教 AFM模型提出的目的和

【推荐系统论文精读系列】(十三)--Attentional Factorization Machines Learning the Weight of Feature Interactions
文章目录 一、摘要二、介绍三、Attentional Factorization Machines3.1 模型3.1.1 Pair-wise Interaction Layer3.1.2 Attention-based Pooling Layer 3.2 学习3.2.1 防止过拟合 References 论文名称:Attentional Factorization Machi
04 MIT线性代数-矩阵的LU分解 Factorization into A=LU
目的: 从矩阵的角度理解高斯消元法, 完成LU分解得到A=LU 1.矩阵乘积的逆矩阵 Inverse of a product 2.矩阵乘积的转置 Transpose of a product 3.转置矩阵的逆矩阵 Inverse of a transpose 4.矩阵的LU分解 U为上三角阵(Upper triangular matrix), L为下三角阵(Lo

个人练习-PAT甲级-1103 Integer Factorization
题目链接https://pintia.cn/problem-sets/994805342720868352/problems/994805364711604224 题目大意:给出三个整数N,K,P,要求将N分解成K个整数的P次方之和。如果分解不唯一,取这K个数之和最大的序列;如果还不唯一,则取大的序列(从大到小排序,a[i]=b[i]但a[i+1]>b[i+1],则a[]更大) 这种题型碰到的
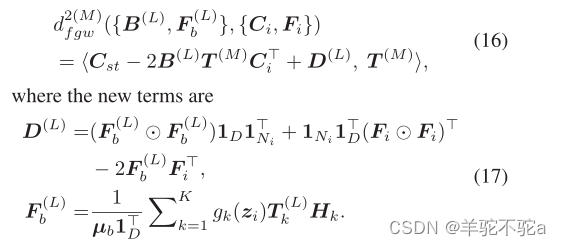
【最优传输论文十九】2020 AAAI - Gromov-wasserstein factorization models for graph clustering
1. motivation 作为机器学习的一种重要方法,因式分解模型明确地探索了高维观测的内在结构,已被广泛应用于数据聚类、降维、推荐系统等学习任务。特别是,因式分解模型将高维观测分解成特定标准下的一组原子,并相应地获得它们的潜在表示。对于每个观测值,其潜在表示对应于与原子相关的系数。 然而,大多数现有的分解模型,如主成分分析(PCA)、非负矩阵分解(NMF) 和字典学习,都是为具有相同维度的

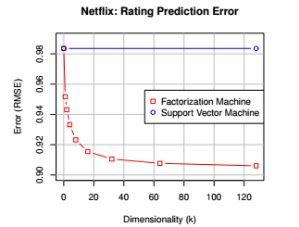
Netflix Prize 矩阵分解(Matrix factorization)预测用户评分
Python实现 Netflix Prize 矩阵分解(Matrix factorization)预测用户评分 笔者使用Python实现用于 Netflix Prize的矩阵分解预测模型, Github链接:https://github.com/SJTUzhou/NetflixPrizeMatrixFactorization 参考文献:https://datajobs.com/data-scie