f1专题

delphi如何给按钮添加单键快捷键(F1~F12)
用action 讲按钮窗体的Keypreview设为True,然后加如下代码 Delphi/Pascal code ? 1 2 3 4 5 6 procedure TForm1 . FormKeyDown(Sender: TObject; var Key: Word ; Shift: TShiftState); begin i

推荐系统-排序算法:常用评价指标:NDCG、MAP、MRR、HR、ILS、ROC、AUC、F1等
参考资料: 推荐算法常用评价指标:NDCG、MAP、MRR、HR、ILS、ROC、AUC、F1等 搜索评价指标——NDCG

命名实体识别(NER)-模型评估:词级别评估、实体级别评估【Precision、Recall、F1】
一、概述 命名实体识别的评判标准:实体的边界是否正确;实体的类型是否标注正确。主要错误类型包括: 文本正确,类型可能错误;反之,文本边界错误,而其包含的主要实体词和词类标记可能正确。 对于二分类的模型,预测结果与实际结果分别可以取0和1。我们用N和P代替0和1,T和F表示预测正确和错误。将他们两两组合,就形成了下图所示的混淆矩阵(注意:组合结果都是针对预测结果而言的)。 由于1和0是数字

分类问题的评价指标:多分类【Precision、 micro-P、macro-P】、【Recall、micro-R、macro-R】、【F1、 micro-F1、macro-F1】
一、混淆矩阵 对于二分类的模型,预测结果与实际结果分别可以取0和1。我们用N和P代替0和1,T和F表示预测正确和错误。将他们两两组合,就形成了下图所示的混淆矩阵(注意:组合结果都是针对预测结果而言的)。 由于1和0是数字,阅读性不好,所以我们分别用P和N表示1和0两种结果。变换之后为PP,PN,NP,NN,阅读性也很差,我并不能轻易地看出来预测的正确性与否。因此,为了能够更清楚地分辨各种预测情

准确率、精确率、召回率、F1(F-Measure)都是什么?
机器学习ML、自然语言处理NLP、信息检索IR等领域,评估(Evaluation)是一个必要的工作,而其评论价值指标往往有如下几点: 准确率 Accuracy; 精准率 Precision; 召回率 Recal; F1-Measure; TP: True Positive 把正的判断为正的数目True Positive,判断正确,且判为了正,即正的预测为正的; FN:False N
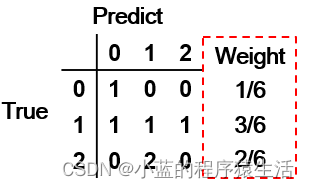
多分类问题中评价指标F1-Score 加权平均权重的计算方法
多分类问题中评价指标F1-Score 加权平均权重的计算方法 众所周知,F1分数(F1-score)是分类问题的一个衡量指标。在分类问题中,常常将F1-score作为评价分类结果好坏的指标。它是精确率和召回率的调和平均数,值域为[0,1]。 F 1 = 2 ∗ P ∗ R P + R F_1=2*\frac{P*R}{P+R} F1=2∗P+RP∗R 其中,P代表着准确率(
sklearn工具包---分类效果评估(acc、recall、F1、ROC、回归、距离)
一、acc、recall、F1、混淆矩阵、分类综合报告 1、准确率 第一种方式:accuracy_score # 准确率import numpy as npfrom sklearn.metrics import accuracy_scorey_pred = [0, 2, 1, 3,9,9,8,5,8]y_true = [0, 1, 2, 3,2,6,3,5,9] #共9个数据,3个相
联想台式机快捷键(F1~F12)取消按Fn,设置为标准功能键
前几天电脑中了病毒,修复之后,发现之前visual studio好端端的F12转到定义,变成了必须加Fn才能转到定义,因为编程时候加Fn太麻烦了。于是试了网上各种方法,想将键盘恢复为标准功能键。包括BIOS设置HotKey,Lenovo Low Profile USB Keyboard的勾选设置,等等。最后我想会不会是病毒导致Lenovo Low Profile USB Keyboard出了问题。
SMS垃圾短信集F1指标分析
一、任务 SMS垃圾短信集是一组为研究SMS垃圾短信而收集数据集合,每条短信有两个信息,分别是标签信息label,其中spam为垃圾短信,ham为正常短信。以及message信息为短信内容。现在有训练集,训练集保存在E:\自然语言处理\train.csv和测试集,测试集保存在E:\自然语言处理\test.csv。现在综合利用所学的文本预处理、特征提取、文本向量化等技术对其进行分析。建立机器学习模
precision_score, recall_score, f1_score的计算
1 使用numpy计算true positives等 [python] view plain copy import numpy as np y_true = np.array([0, 1, 1, 0, 1, 0]) y_pred = np.array([1, 1, 1, 0, 0, 1]) # true positive TP = np.

stm32_HAL_RTC_闹钟函数(F1只有一个闹钟)
HAL_RTC_SetAlarm: 功能:设置RTC闹钟。 参数: hrtc:指向RTC句柄结构的指针。sAlarm:指向包含闹钟配置的结构体的指针。Format:指定日期和时间的格式(12小时或24小时制)。返回值:状态(HAL_OK,HAL_ERROR等)。 HAL_RTC_SetAlarm_IT: 功能:与HAL_RTC_SetAlarm相同,但启用中断。 参数:同上。返回值:状态。

xxx is not translated in en (English) or zh (Chinese) less... (Ctrl+F1)
作为跟我一样,看到一大堆warnning和error,就有点强迫症的想干掉,就有2种方式: 1.给resources标签添加一个属性 <resources xmlns:tools="http://schemas.android.com/tools" tools:ignore="MissingTranslation"> 2.也可以添加translatable="false"给个别的

python计算precision@k、recall@k和f1_score@k
sklearn.metrics中的评估函数只能对同一样本的单个预测结果进行评估,如下所示: from sklearn.metrics import classification_reporty_true = [0, 5, 0, 3, 4, 2, 1, 1, 5, 4]y_pred = [0, 2, 4, 5, 2, 3, 1, 1, 4, 2]print(classification_repo
![[机器学习] 第二章 模型评估与选择 1.ROC、AUC、Precision、Recall、F1_score](https://img-blog.csdnimg.cn/20210418025501926.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1RyYW5jZTk1,size_16,color_FFFFFF,t_70)
[机器学习] 第二章 模型评估与选择 1.ROC、AUC、Precision、Recall、F1_score
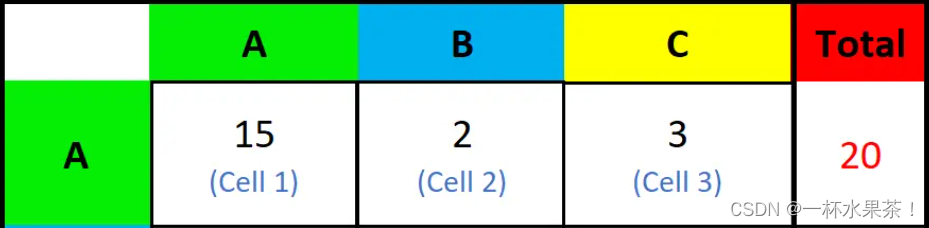
准确率(Accuracy) = (TP + TN) / 总样本 =(40 + 10)/100 = 50%。 定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。 精确率(Precision) = TP / (TP + FP) = 40/60 = 66.67%。它表示:预测为正的样本中有多少是真正的正样本,它是针对我们预测结果而言的。Precision又称为查准率。 召回率
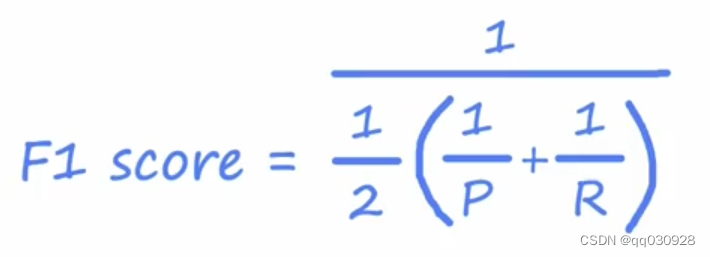
深度学习 Lecture 7 迁移学习、精确率、召回率和F1评分
一、迁移学习(Transfer learning) 用来自不同任务的数据来帮助我解决当前任务。 场景:比如现在我想要识别从0到9度手写数字,但是我没有那么多手写数字的带标签数据。我可以找到一个很大的数据集,比如有一百万张图片的猫、狗、汽车和人等1000个类,那我就可以在这个大型数据集上用这一百万张图片作为输入,训练一个模型来学会识别这1000个不同的类别。 比如我训练出来后,长这样: 这里有
Accuracy准确率,Precision精确率,Recall召回率,F1 score
真正例和真反例是被正确预测的数据,假正例和假反例是被错误预测的数据。然后我们需要理解这四个值的具体含义: TP(True Positive):被正确预测的正例。即该数据的真实值为正例,预测值也为正例的情况; TN(True Negative):被正确预测的反例。即该数据的真实值为反例,预测值也为反例的情况; FP(False Positive):被错误预测的正例。即该数据的真实值为反例,但被错误预

NLP09_机器学习、监督学习、模型搭建流程、朴素贝叶斯、系统评估、准确率,精确率召回率,F1-Measure
基于概率的系统 给定数据集,X代表特征信息,y代表标签 最终学习到x到y的映射关系f 模型f可以表示线性回归、逻辑回归、神经网络 nlp依赖于机器学习 机器学习 算法分类 监督学习,给定标签。无监督学习只有特征,没有标签 朴素贝叶斯:用于文本分类(垃圾邮件过滤,情感分析)上 逻辑回归: CRF: HMM:常用于语言识别 LDA:抽取文本主题 GMM:高斯回归模型 监督学习
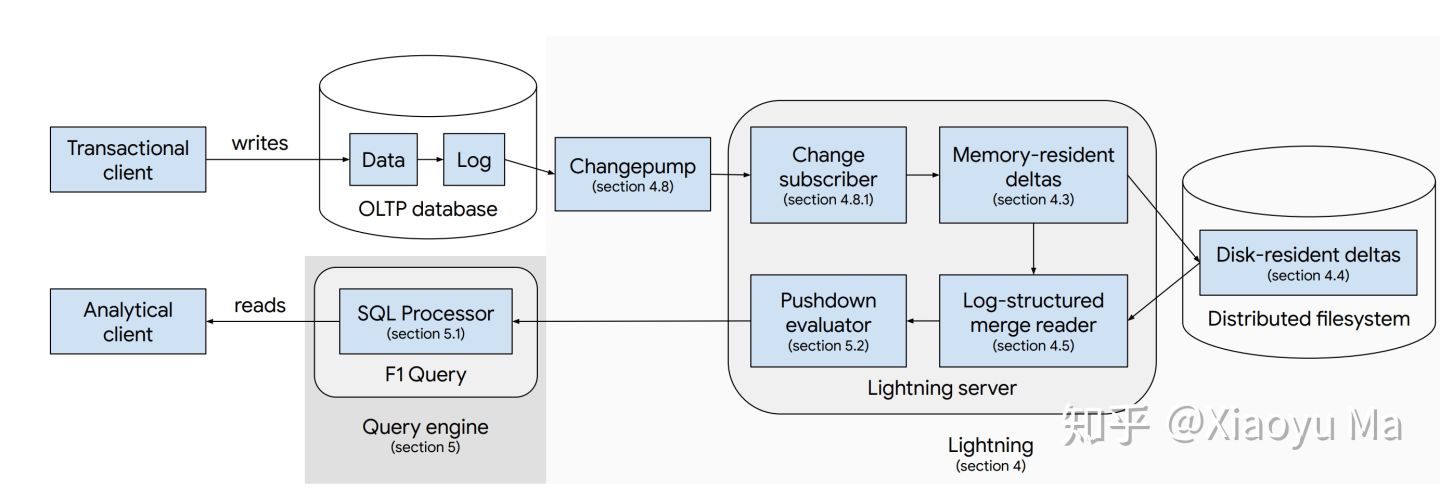
读论文 - F1 Lightning: HTAP as a Service
作者:马晓宇 论文发布之后已经有一段时间了,之前提到的这篇文章由于种种原因也是欠了有些日子,抱歉了大家。 上次说过,这次 VLDB 有好些篇都是 HTAP(Hybrid Transactional / Analytical Processing)主题。自打 2014 年 Gartner 提出这个说法,由于针对交易数据的实时分析需求越来越多,这些年来 HTAP 已经变成一个热词。除了 Pi
笔记本F1-F12功能
F1:如果你处在一个选定的程序中而需要帮助,那么请按下F1。如果现在不是处在任何程序中,而是处在资源管理器或桌面,那么按下F1就会出现Windows的帮助程序。如果你正在对某个程序进行操作,而想得到Windows帮助,则需要按下Win+F1。按下Shift+F1,会出现"What's This?"的帮助信息。 F2:如果在资源管理器中选定了一个文件或文件夹,按下F2则会对这个选定的文件

【5G 接口协议】CU与DU之间的F1协议介绍
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持! 博主链接 本人就职于国际知名终端厂商,负责modem芯片研发。 在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。 博客内容主要围绕: 5G/6G协议讲解 算力网络讲解(云计算,边缘计算,端计算) 高级C语言讲解 Rust语言讲解
分类任务中的评估指标:Accuracy、Precision、Recall、F1
概念理解 T P TP TP、 T N TN TN、 F P FP FP、 F N FN FN精度/正确率( A c c u r a c y Accuracy Accuracy) 二分类查准率 P r e c i s i o n Precision Precision,查全率 R e c a l l Recall Recall 和 F 1 − s c o r e F1-score
100天精通风控建模(原理+Python实现)——第20天:风控建模中的F1值是什么?怎么实现?
在当今风险多变的环境下,风控建模已经成为金融机构、企业等组织的核心工作之一。在各大银行和公司都实际运用于业务,用于营销和风险控制等。本文以视频的形式阐述风控建模中的召回率是什么,怎么实现。并提供风控建模原理和Python实现文章清单。 之前已经阐述了100天精通风控建模(原理+Python实现)——第1天:什么是风控建模? 100天精通风控建模(原理+Python实现)——第2天:风控

WA、UAR、F1和sklearn自带的函数
多分类问题中常用的评价指标。 目录 1.WA(weighted accuracy)加权准确率 2.UAR(unweighted average recall)未加权平均召回率 3.F1分数 4.使用sklearn进行计算 5.适用场景 6.其他 1.WA(weighted accuracy)加权准确率 在多分类问题中,加权准确率(Weighted Accuracy)是一种

mmdetection如何计算准确率、召回率、F1值
1、训练 python tools/train.py configs/fcos/fcosrdweed3.py 2、测试 这一步要加–out=result.pkl,才能计算准确率和召回率 python tools/test.py configs/fcos/fcosrddweed3.py work_dirs/fcosrddweed3/epoch_300.pth --out=resultfc

复制android studio ctrl+F1警告提示内容
有几种方案: 1,选中这些提示,然后ctrl+c,新版本的android studio已经不允许了 2,点中你有提示的那段代码,编译器最底部有提示信息,右键copy,不过 只能显 示一行 3,android studio 本质上是intellij idea改编过来的,大部分intellij有的快捷, 它都有,你可以鼠标左键点到你的提示信息,然后按住alt键,再鼠标左键点中 信 息,然