deepspeed专题
k8s volcano + deepspeed多机训练 + RDMA ROCE+ 用户权限安全方案【建议收藏】
前提:nvidia、cuda、nvidia-fabricmanager等相关的组件已经在宿主机正确安装,如果没有安装可以参考我之前发的文章GPU A800 A100系列NVIDIA环境和PyTorch2.0基础环境配置【建议收藏】_a800多卡运行环境配置-CSDN博客文章浏览阅读1.1k次,点赞8次,收藏16次。Ant系列GPU支持 NvLink & NvSwitch,若您使用多GPU卡的机型,

deepspeed win11 安装
目录 git地址: aio报错: 编译 报错 ops已存在: 修改拷贝代码: git地址: Bug Report: Issues Building DeepSpeed on Windows · Issue #5679 · microsoft/DeepSpeed · GitHub aio报错: setup.py 配置变量 os.environ['DISTUTILS_U

MixtralForCausalLM DeepSpeed Inference节约HOST内存【最新的方案】
MixtralForCausalLM DeepSpeed Inference节约HOST内存【最新的方案】 一.效果二.特别说明三.测试步骤1.创建Mixtral-8x7B配置文件(简化了)2.生成随机模型,运行cpu float32推理,输出结果3.加载模型,cuda 单卡推理4.DS 4 TP cuda 推理5.分别保存DS 4TP每个rank上engine.module的权值6.DS
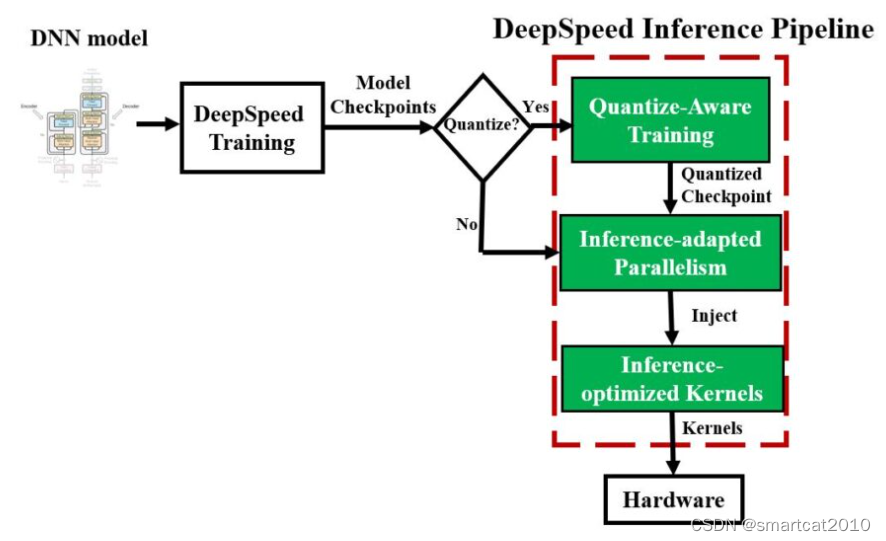
DeepSpeed Mixture-of-Quantization (MoQ)
属于QAT (Quantization-Aware Training)的一种,训练阶段用量化。 特点是: 1. 从16-bit INT开始训练,逐渐减1bit,训练一些steps就减1bit,直至减至8bit INT; 2. (可选,不一定非用)多久减1bit,这个策略,使用模型参数的二阶特征来决定,每层独立的(同一时刻,每层的特征值们大小不一致,也就造成bit减少速度不一致,造成bit数目

DeepSpeed MoE
MoE概念 模型参数增加很多;计算量没有增加(gating+小FNN,比以前的大FNN计算量要小);收敛速度变快; 效果:PR-MoE > 普通MoE > DenseTransformer MoE模型,可视为Sparse Model,因为每次参与计算的是一部分参数; Expert并行,可以和其他并行方式,同时使用: ep_size指定了MoE进程组大小,一个模型replica的所

DeepSpeed Profiling
DeepSpeed自带的Profiler -------------------------- DeepSpeed Flops Profiler --------------------------Profile Summary at step 10:Notations:data parallel size (dp_size), model parallel size(mp_size),
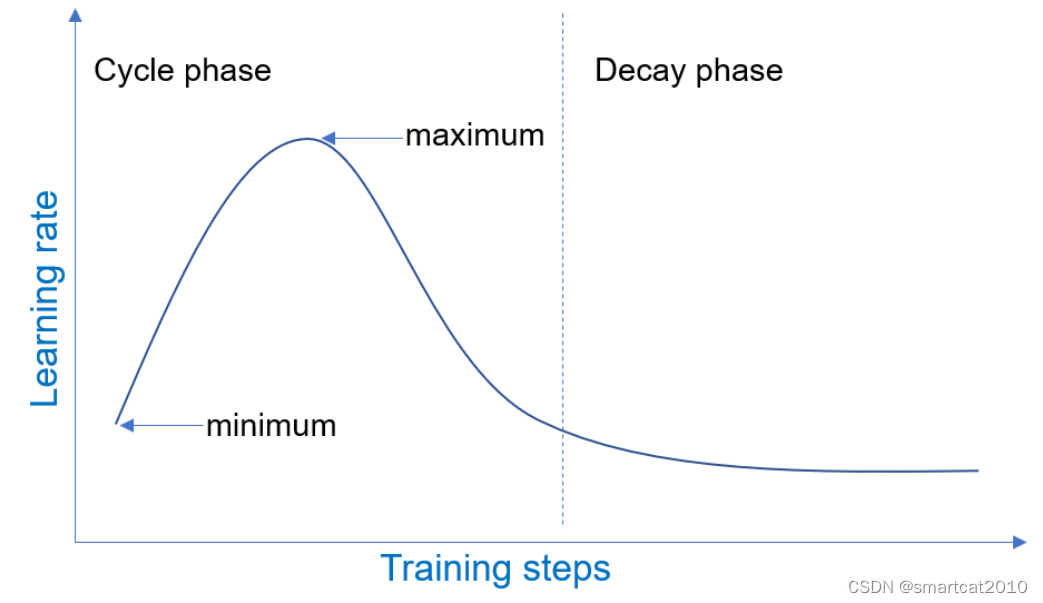
DeepSpeed Learning Rate Scheduler
Learning Rate Range Test (LRRT) 训练试跑,该lr scheduler从小到大增长lr,同时记录下validatin loss;人来观察在训练多少step之后,loss崩掉(diverge)了,进而为真正跑训练,挑选合适的lr区间; "scheduler": {"type": "LRRangeTest","params": {"lr_range_test_min_l
DeepSpeed Huggingface模型的自动Tensor并行
推理阶段。在后台,1. DeepSpeed会把运行高性能kernel(kernel injection),加快推理速度,这些对用户是透明的; 2. DeepSpeed会根据mp_size来将模型放置在多个GPU卡上,自动模型并行; import osimport torchimport transformersimport deepspeedlocal_rank = int(os.get
DeepSpeed Autotuning
AutoTuning 用不同的系统参数试跑用户的模型训练,尝试不同的参数组合,给出每种参数组合的速度,供用户去选择较块的来进行真正的训练。 ZeRO optimization stages;micro-batch sizes;optimizer, scheduler, fp16等; 在DeepSpeed配置文件里,设定: "autotuning": { "enabled": true }
DeepSpeed入门
pip install deepspeed 支持transformers: --deepspeed,以及config文件; model_engine, optimizer, _, _ = deepspeed.initialize(args=cmd_args,model=model,model_parameters=params) 分布式和mixed-precision等,都包含在deep
一文搞懂大模型训练加速框架 DeepSpeed 的使用方法!
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。 针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 合集: 《大模型面试宝典》(2024版) 正式发布! 保姆级学习指南:《Pytorch 实战宝典》来了 在AI领域,常见的深度学习框架TensorFlow、PyTo
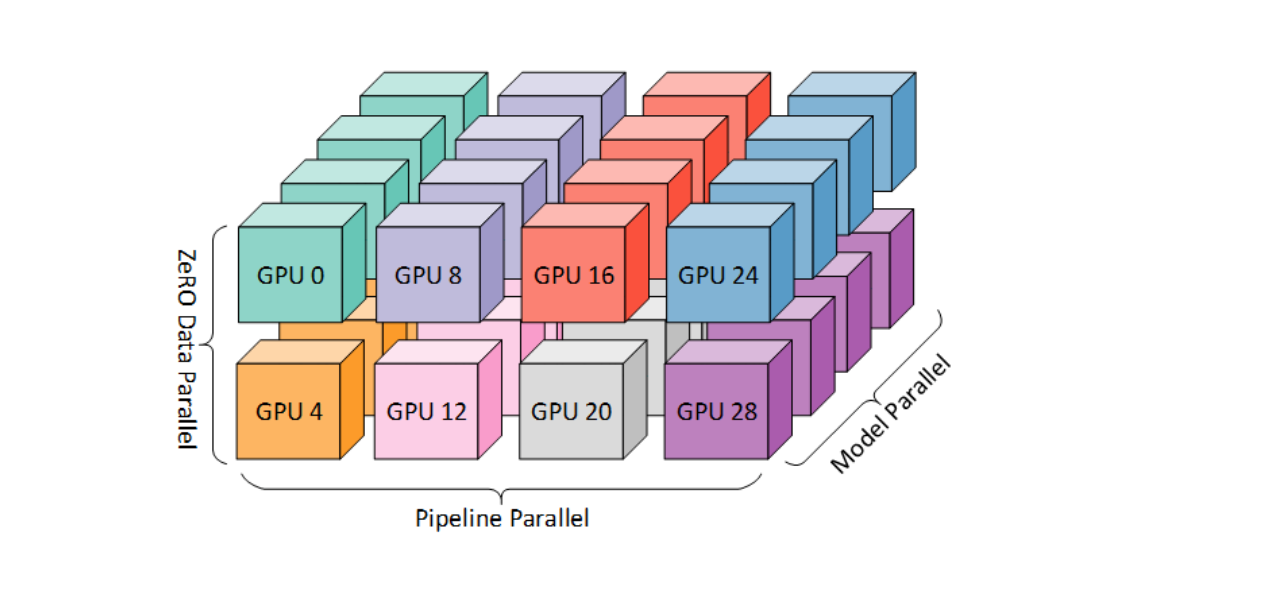
一文读懂deepSpeed:深度学习训练的并行化
引言 在深度学习领域,模型训练的过程不仅资源密集,而且技术复杂。近年来,随着模型规模和数据量的不断增长,深度学习训练面临着越来越多的挑战。这些挑战主要体现在计算资源的需求、训练效率、模型复杂度以及内存管理等多个方面。而DeepSpeed库的出现,正是为了解决这些问题,它提供了一整套优化工具和策略,极大地提升了深度学习训练的效率和可扩展性。 目录 引言 1. DeepSpeed简介

超大模型分布式训练DeepSpeed教程
DeepSpeed教程 项目链接 简介 deep speed是微软的新大规模模型分布式训练的工具。专门为训练超大模型而生。号称可以训练10B参数的模型。比目前最好的模型大10倍,训练速度块10倍。兼容pytorch的模型,可以改动最少代码。下图是展示训练bert需要的时间,基本同gpu的数量成线性相关。 安装 下载code(0.3.0) git clone https://githu
[ deepSpeed ] 单机单卡本地运行 Docker运行
本文笔者基于官方示例DeepSpeedExamples/training/cifar/cifar10_deepspeed.py进行本地构建和Docker构建运行示例(下列代码中均是踩坑后可执行的代码,尤其是Docker部分), 全部code可以看笔者的github: cifiar10_ds_train.py 1 环境配置 1.1 cuda 相关配置 wget https://develope
deepspeed+transformers模型微调
一、目录 代码讲解 二、实现。 1、代码讲解,trainer 实现。 transformers通过trainer 集成deepspeed功能,所以中需要进行文件配置,即可实现deepspeed的训练。 微调代码: 参数定义—>数据处理---->模型创建/评估方式---->trainer 框架训练 注意: V100 显卡,不包括float16 精度训练。 import deepspeedd
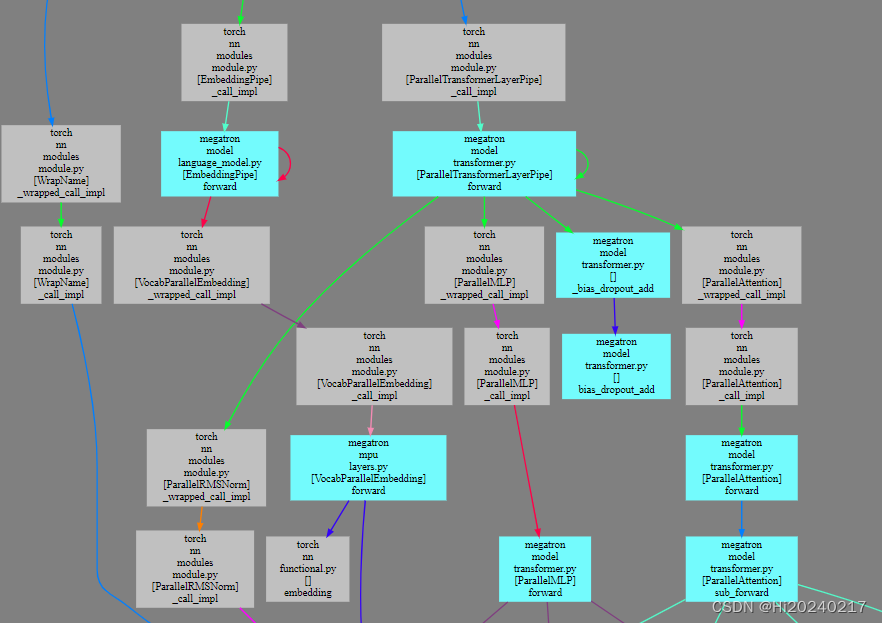
基于torch_dispatch机制生成Megatron-DeepSpeed调用关系图
基于torch_dispatch机制生成Megatron-DeepSpeed调用关系图 一.局部效果图二.运行训练过程,拦截算子,生成调用关系信息三.可视化,生成SVG图像 想知道Megatron-DeepSpeed训练过程中各模块之间的调用关系。torch_dispatch机制可以拦截算子,inspect又能获取到调用栈(文件,类名,函数,行号).基于这些信息可以生成调用关系,最
大模型训练框架DeepSpeed使用入门(1): 训练设置
文章目录 一、安装二、训练设置Step1 第一步参数解析Step2 初始化后端Step3 训练初始化 三、训练代码展示 官方文档直接抄过来,留个笔记。 https://deepspeed.readthedocs.io/en/latest/initialize.html 使用案例来自: https://github.com/OvJat/DeepSpeedTutorial

linux下安装deepspeed
安装步骤 一开始安装deepspeed不可以使用pip直接进行安装。 这时我们需要利用git进行clone下载到本地: git clone https://github.com/microsoft/DeepSpeed.git 进入到deepspeed的安装目录下 cd /home/bingxing2/ailab/group/ai4agr/wzf/Tools/DeepSpeed 激活你的
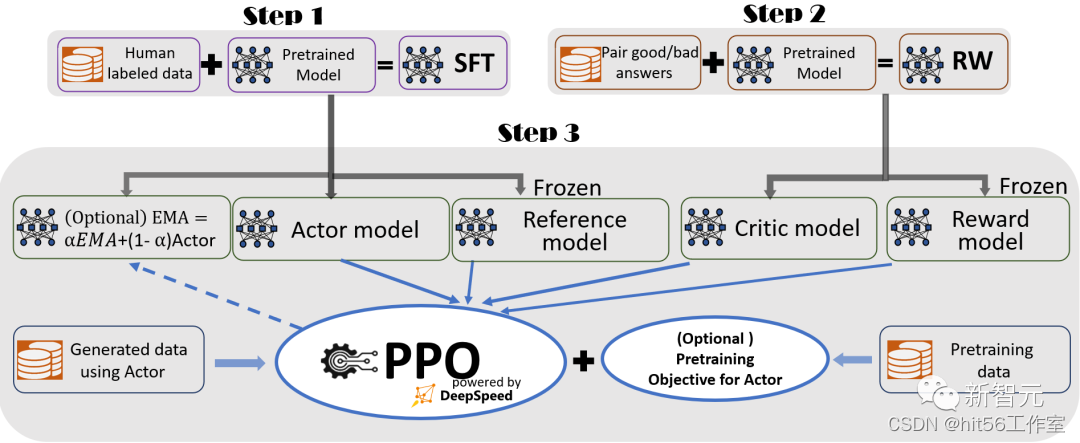
deepspeed笔记
文章目录 一、deepspeed是什么?二、能训多大的模型,耗时如何?三、RLHF训练流程四、通信策略 一、deepspeed是什么? 传统的深度学习,模型训练并行,是将模型参数复制多份到多张GPU上,只将数据拆分(如,torch的Dataparallel),这样就会有大量的显存冗余浪费。而ZeRO就是为了消除这种冗余,提高对memory的利用率。注意,这里的“memory”不仅

Deepspeed、ZeRO、FSDP、ZeRO-Offload、all reduce、reduce-scatter
Transformer为基础的大模型应该如何并行 数据并行。但是如果模型太大放不到一块卡上就没用了。为了解决把参数放到一块卡上的问题,演进出了论文Zero的思想,分为Zero-DP和Zero-R两部分。Zero-DP是解决Data parallel的问题,并行过程中内容不够,解决思路也比较简单,模型参数w只存在一台机器上,剩下的部分等用的时候找某台机器通过all-reduce请求就可以了。Zer
LLM分布式训练第五课-Deepspeed_Zero
首先需要明确的是Deepspeed本身是一种数据并行的优化,它也可以和其他的PP,TP,一起结合使用。 Deepspeed最有名的feature就是大名鼎鼎的Zero,我们之前讲过,在训练的过程中占用显存的数据主要分两类: 一类是模型本身的占用显存,如果用一个正常的混合精度训练的话,那么需要16byte,也就是2字节的模型参数,2字节的模型梯度,如果是以Adam来做

大模型并行训练、推理框架Deepspeed简介
目录 一.简介二.分布式训练方法 1.数据并行2.张量并行3.流水线并行 三.ZeRO 1.模型的显存占用2.ZeRO-1/2/33.ZeRO-Offload4.ZeRO-Infinity 四.总结五.参考 传送门:https://github.com/wzzzd/LLM_Learning_Note/blob/main/Parallel/deepspeed.md 一.简介 Deepspee
DeepSpeed在windows下构建失败的问题
使用pip install deepspeed无法安装,看教程说是可以自己安装。 ## Windows Windows support is partially supported with DeepSpeed. On Windows you can build wheel with following steps, currently only inference mode is suppor
DeepSpeed-Chat RLHF 阶段代码解读(0) —— 原始 PPO 代码解读
为了理解 DeepSpeed-Chat RLHF 的 RLHF 全部过程,这个系列会分三篇文章分别介绍: 原始 PPO 代码解读RLHF 奖励函数代码解读RLHF PPO 代码解读 这是系列的第一篇文章,我们来一步一步的看 PPO 算法的代码实现,对于 PPO 算法原理不太了解的同学,可以参考之前的文章: 深度强化学习(DRL)算法 2 —— PPO 之 Clipped Surrogate Obj
vscode调试deepspeed代码
下面展示一个例子: {"version": "0.2.0","configurations": [{"name": "Python: Debug DeepSpeed","type": "python","request": "launch","program": "/home/upa1/.conda/envs/dsmoe/bin/deepspeed","justMyCode": true,"co
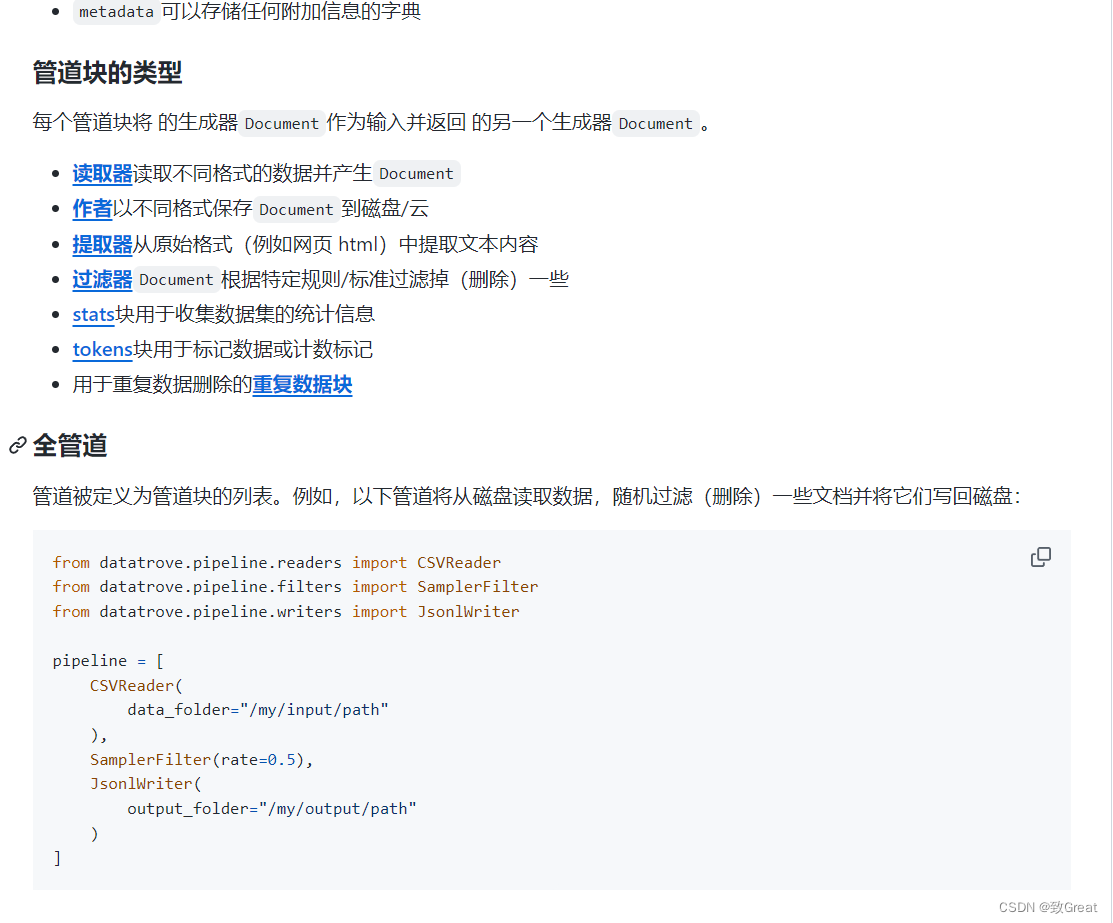
推荐两个工具:DeepSpeed-FastGen和DataTrove
DeepSpeed-FastGen 通过 MII 和 DeepSpeed-Inference 加速LLM生成文本 仓库地址:https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-fastgen GPT-4 和 LLaMA 等大型语言模型 (LLM) 已成为服务于各个级别的人工智能应用程序的主要工作负