本文主要是介绍推荐两个工具:DeepSpeed-FastGen和DataTrove,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DeepSpeed-FastGen
通过 MII 和 DeepSpeed-Inference 加速LLM生成文本
仓库地址:https://github.com/microsoft/DeepSpeed/tree/master/blogs/deepspeed-fastgen
GPT-4 和 LLaMA 等大型语言模型 (LLM) 已成为服务于各个级别的人工智能应用程序的主要工作负载。从一般聊天模型到文档摘要,从自动驾驶到软件堆栈每一层的副驾驶,大规模部署和服务这些模型的需求猛增。虽然 DeepSpeed、PyTorch 等框架可以在 LLM 训练期间定期实现良好的硬件利用率,但这些应用程序的交互性和开放式文本生成等任务的较差算术强度已成为现有系统中推理吞吐量的瓶颈。
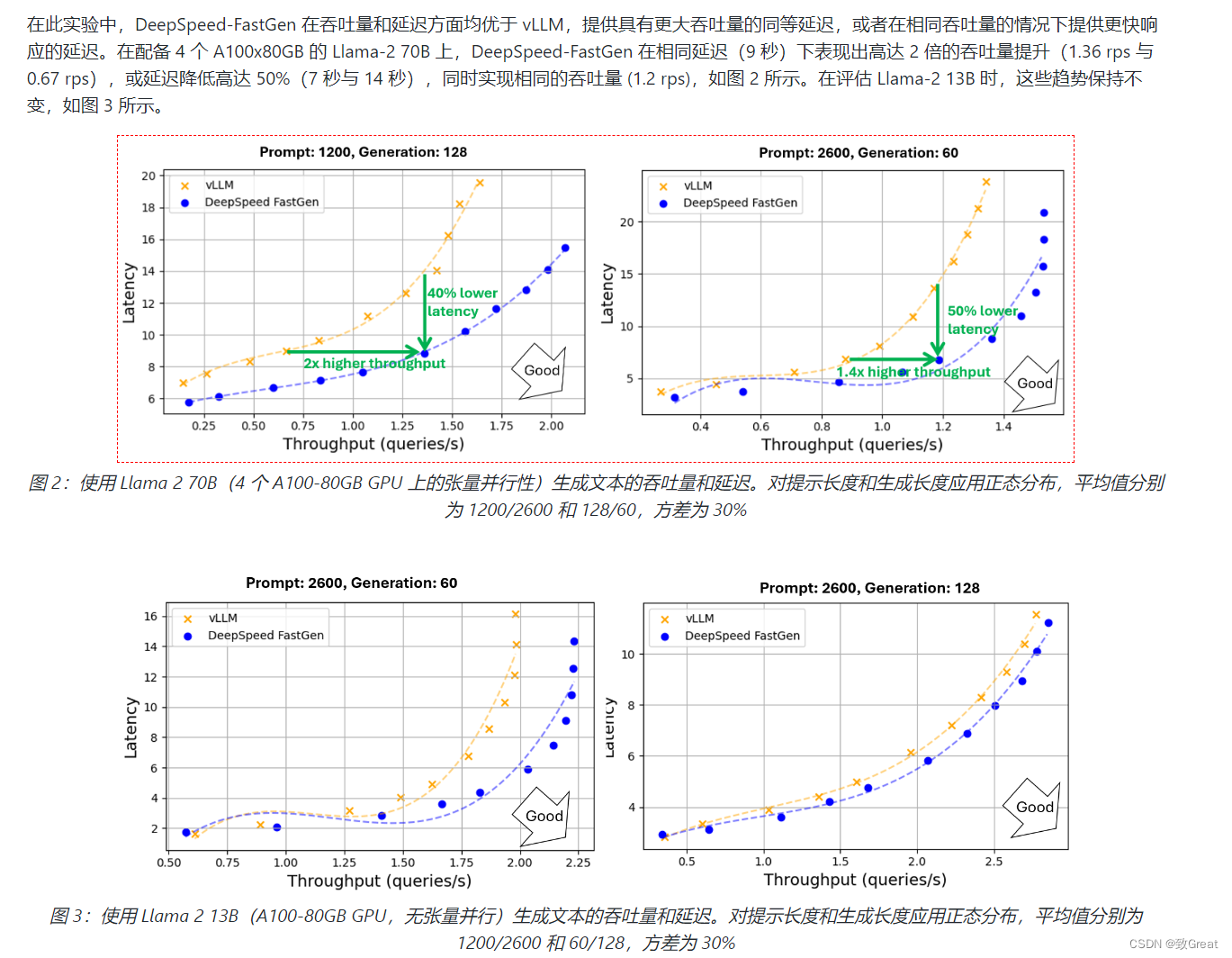
为此,框架如LLM由 PagedAttention 和Orca等研究系统提供支持,显着提高了LLM的推理性能。然而,这些系统仍然难以提供一致的服务质量,特别是对于提示较长的工作负载。随着越来越多的模型(如MPT-StoryWriter)和系统(如DeepSpeed Ulysses)支持扩展到数万个令牌的上下文窗口,这些长提示工作负载变得越来越重要。为了更好地理解问题空间,我们提供了详细的示例,说明LLM文本生成如何在两个不同的阶段(称为提示处理和生成)工作。当系统将它们视为不同的阶段时,生成将被即时处理抢占,这可能会破坏服务级别协议(SLA)。
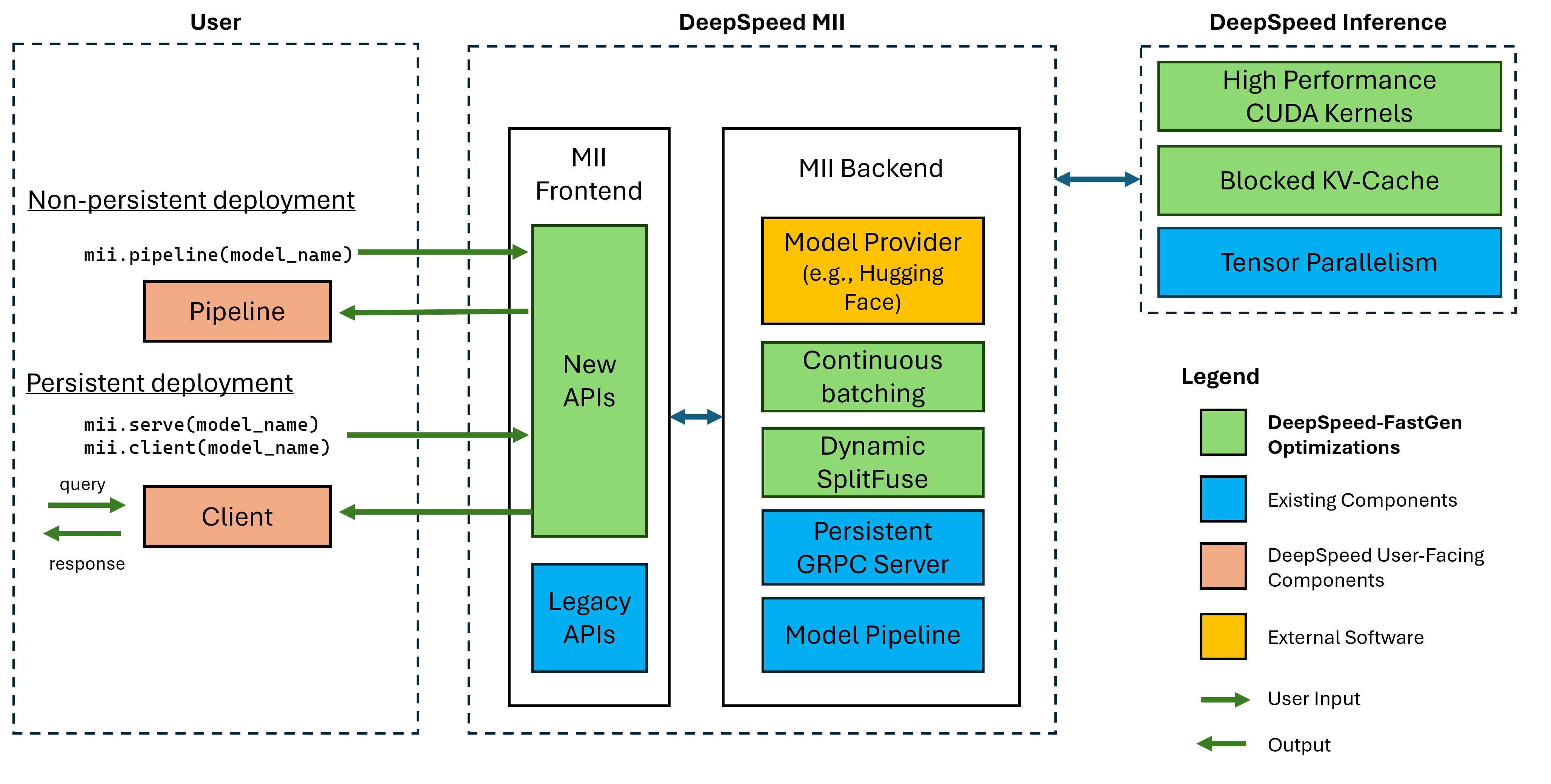
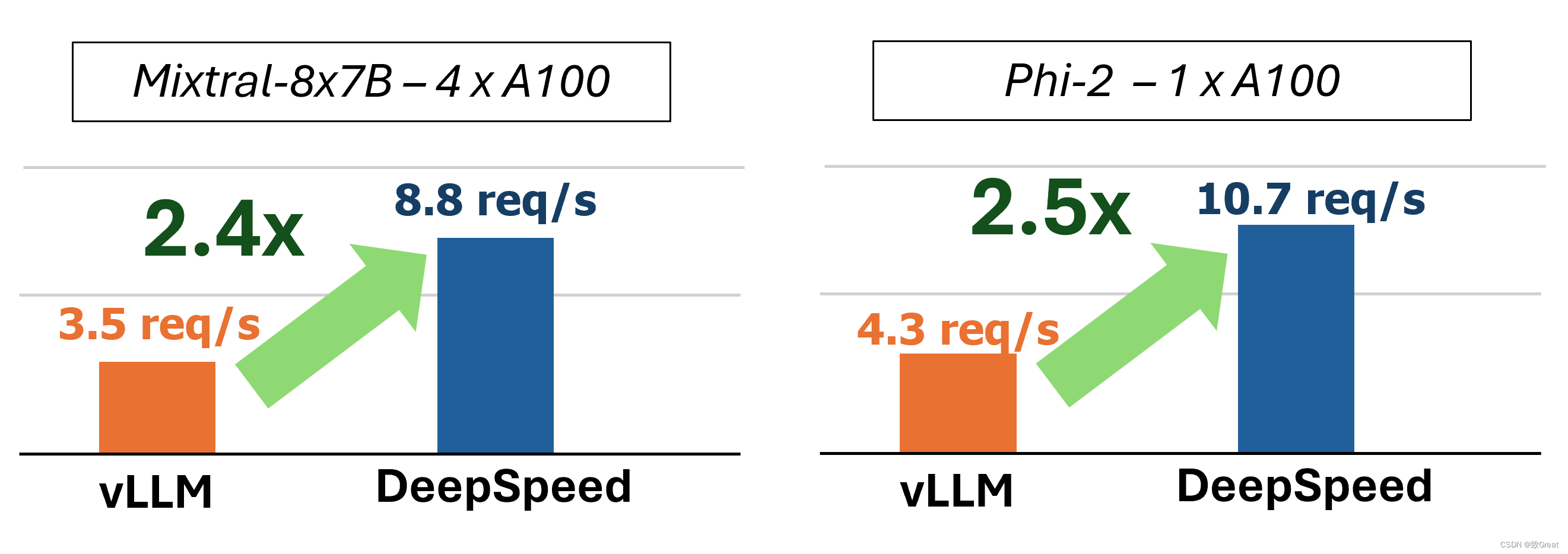
DeepSpeed官方推出 DeepSpeed-FastGen,该系统通过利用所提出的动态 SplitFuse 技术克服了这些限制,与 vLLM 等最先进的系统相比,有效吞吐量提高了 2.3 倍。DeepSpeed-FastGen 利用 DeepSpeed-MII 和 DeepSpeed-Inference 的组合来提供易于使用的服务系统。
使用很方面:
from mii import pipeline
pipe = pipeline("mistralai/Mistral-7B-v0.1")
output = pipe(["Hello, my name is", "DeepSpeed is"], max_new_tokens=128)
print(output)
DataTrove
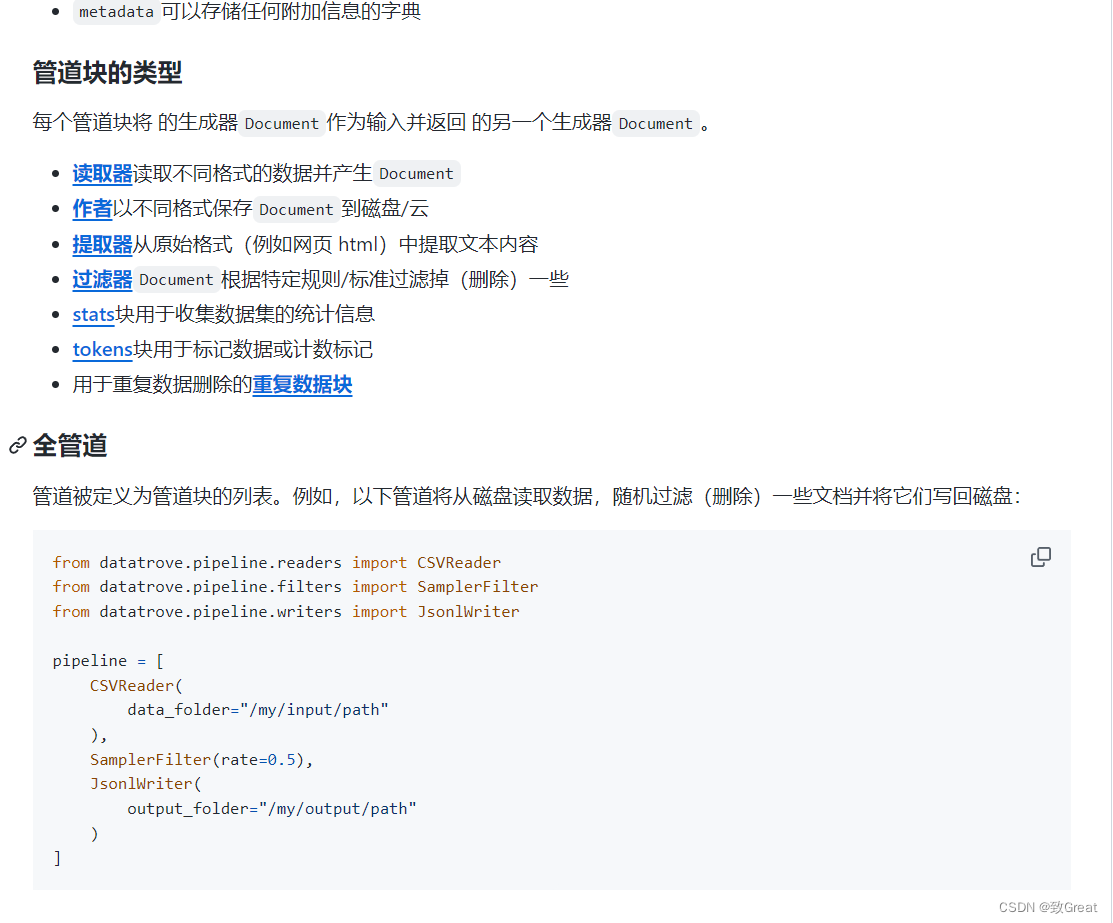
DataTrove 是一个用于大规模处理、过滤和删除重复文本数据的库。它提供了一组预构建的常用处理块以及一个框架,可以轻松添加自定义功能。
DataTrove 处理管道与平台无关,可以在本地或 slurm 集群上开箱即用。其(相对)较低的内存使用率和多步骤设计使其非常适合大型工作负载,例如处理大模型的训练数据。
https://github.com/huggingface/datatrove
这篇关于推荐两个工具:DeepSpeed-FastGen和DataTrove的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







