本文主要是介绍一文搞懂大模型训练加速框架 DeepSpeed 的使用方法!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集:
《大模型面试宝典》(2024版) 正式发布!
保姆级学习指南:《Pytorch 实战宝典》来了
在AI领域,常见的深度学习框架TensorFlow、PyTorch和Keras无疑是开发者们的得力工具,但随着模型规模的急剧膨胀,这些传统框架在应对大模型时往往会显得力不从心。
比如Pytorch的分布式并行计算框架DDP(Distributed Data Parallel),尽管实现了数据并行,但是当模型大小超过单个GPU显存限制时显得捉襟见肘。此时,开发者往往只能手动进行复杂模型的参数拆分到各个GPU上,这无疑增加了研发的复杂性和门槛。

然而,微软推出的一款框架——DeepSpeed,可解决这一局限。它通过将模型参数拆散分布到各个GPU上,以实现大模型的计算。这也意味着,我们可以利用更少的硬件资源训练更大的模型,不再受限于单个GPU的显存限制。

安装DeepSpeed
pip install deepspeed
此外,还需要下载Pytorch,在官网选择自己对应的系统版本和环境,按照指示安装即可:
https://pytorch.org/get-started/locally/

使用DeepSpeed
载入数据集
# 导入必要的库
import torch
import torchvision
import torchvision.transforms as transforms# 创建训练数据集
trainset = torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform)
# 创建数据加载器,批量加载数据并处理数据加载的并行化
trainloader = torch.utils.data.DataLoader(trainset,# 每个批次包含16张图像batch_size=16,# 在每次迭代开始时随机打乱训练数据的顺序# 有助于模型训练shuffle=True,# 开启2个子进程来并行加载数据,提高效率num_workers=2)
# 创建测试数据集
testset = torchvision.datasets.CIFAR10(root='./data',train=False,download=True,transform=transform)
testloader = torch.utils.data.DataLoader(testset,batch_size=4,#测试数据通常不需要打乱顺序shuffle=False,num_workers=2)
创建模型
# 导入必要的PyTorch模块# 用于构建神经网络模型
import torch.nn as nn
# 提供了各种神经网络层的函数版本,如激活函数、损失函数等
import torch.nn.functional as F# 定义一个名为Net的类,继承自nn.Module
class Net(nn.Module):def __init__(self):super(Net, self).__init__()# 创建卷积层,参数:(输入通道数,输出通道数,卷积核大小)self.conv1 = nn.Conv2d(3, 6, 5)# 创建最大池化层,参数:(池化窗口大小,步长)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)# 创建全连接层(线性层),参数:(输入节点数,输出节点数)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)# 前向传播过程,即输入数据通过网络的流程def forward(self, x):# 使用F.relu应用ReLU激活函数# 使用self.pool进行最大池化x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))# 使用.view方法将池化后的特征图展平为一维向量,以便输入全连接层x = x.view(-1, 16 * 5 * 5)# 应用全连接层和ReLU激活函数,直到最后一层fc3,# 它不使用激活函数,直接输出分类结果x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x
# 实例化网络模型
net = Net()
# 设置损失函数
# 多分类交叉熵损失函数,适用于监督学习中的分类任务
criterion = nn.CrossEntropyLoss()
初始化Deepspeed
DeepSpeed通过输入参数来启动训练,因此需要使用argparse解析参数。
import argparsedef add_argument():# 创建一个ArgumentParser对象,设置描述为"CIFAR"parser = argparse.ArgumentParser(description='CIFAR')# 设置训练时的批大小,默认值为32parser.add_argument('-b','--batch_size',default=32,type=int,help='mini-batch size (default: 32)')# 设置总的训练轮数,默认值为30parser.add_argument('-e','--epochs',default=30,type=int,help='number of total epochs (default: 30)')# 传递分布式训练中的排名,默认值为-1,表示未使用分布式训练parser.add_argument('--local_rank',type=int,default=-1,help='local rank passed from distributed launcher')# 设置输出日志信息的间隔,默认值为2000,即每2000次迭代打印一次日志parser.add_argument('--log-interval',type=int,default=2000,help="output logging information at a given interval")# 添加与DeepSpeed相关的配置参数parser = deepspeed.add_config_arguments(parser)# 解析命令行参数,返回一个Namespace对象,其中包含了所有定义的参数及其对应的值args = parser.parse_args()# 返回解析后的参数对象args,供后续的训练脚本使用return args
此外,模型初始化的时候除了参数,还需要model及其parameters,还有训练集:
# 启动DeepSpeed训练# 调用之前定义的add_argument函数,解析命令行参数,并将结果存储在args变量中
args = add_argument()
# 创建Net类的实例
net = Net()
# 筛选出模型中需要梯度计算的参数
parameters = filter(lambda p: p.requires_grad, net.parameters())
# 使用deepspeed.initialize初始化模型引擎、优化器、数据加载器以及其他可能的组件
model_engine, optimizer, trainloader, __ = deepspeed.initialize(args=args, model=net, model_parameters=parameters, training_data=trainset)训练
注意local_rank是不需要管的参数,在后面启动模型训练的时候,DeepSpeed会自动给这个参数赋值。
# 定义进行2个epoch的训练
for epoch in range(2):running_loss = 0.0# 对于每个epoch,遍历训练数据加载器trainloader中的每一个小批量数据# 同时提供索引i和数据datafor i, data in enumerate(trainloader):# 将输入数据inputs和标签labels移动到当前GPU设备上,# 具体是哪个GPU由model_engine.local_rank决定,# 这对于分布式训练非常重要,确保数据被正确地分配到各个参与训练的GPU上inputs, labels = data[0].to(model_engine.local_rank), data[1].to(model_engine.local_rank)# 通过model_engine执行前向传播,计算模型预测输出outputs = model_engine(inputs)# 计算预测输出outputs与真实标签labels之间的损失loss = criterion(outputs, labels)# 反向传播计算梯度model_engine.backward(loss)# 更新模型参数model_engine.step()# 计算并累加每个小批量的损失值# 当达到args.log_interval指定的迭代次数时,打印平均损失值,# 然后重置running_loss为0,以便计算下一个区间的平均损失running_loss += loss.item()if i % args.log_interval == (args.log_interval - 1):print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / args.log_interval))running_loss = 0.0
测试
模型测试和模型训练的逻辑类似:
# 初始化计数器
# correct用于记录分类正确的样本数量
# total用于记录评估的总样本数
correct = 0
total = 0
# 上下文管理器,关闭梯度计算,
# 因为在验证阶段我们不需要计算梯度,这可以提高计算效率
with torch.no_grad():# 遍历测试数据加载器testloader中的每个小批量数据for data in testloader:# 获取当前小批量数据的图像和标签images, labels = data# 在当前GPU上执行模型的前向传播# 这里将图像数据移动到与模型相同的GPU上,然后通过模型得到预测输出outputs = net(images.to(model_engine.local_rank))# 找到每个样本的最大概率对应的类别_, predicted = torch.max(outputs.data, 1)# 增加总样本数,同时计算分类正确的样本数。# 注意,这里将标签也移动到与模型相同的GPU上进行比较total += labels.size(0)correct += (predicted == labels.to(model_engine.local_rank)).sum().item()
# 遍历完整个测试集后,计算并打印模型在测试集上的准确率
print('Accuracy of the network on the 10000 test images: %d %%' %(100 * correct / total))
编写模型参数
当前目录下新建一个config.json,写入调优器、训练batch等参数。
{// 每个GPU的训练批次大小"train_batch_size": 4,// 每隔多少步打印一次训练状态,这里是2000步"steps_per_print": 2000,//优化器的配置"optimizer": {//优化器类型"type": "Adam",//Adam优化器的参数"params": {//学习率"lr": 0.001,// Adam的第一和第二动量参数"betas": [0.8,0.999],//优化器的稳定常数,防止除以零,这里是1e-8"eps": 1e-8,//权重衰减(L2正则化)"weight_decay": 3e-7}},// 学习率调度器的配置"scheduler": {//调度器类型"type": "WarmupLR","params": {//预热阶段的最小学习率,这里是0"warmup_min_lr": 0,// 预热阶段的最大学习率,这里是0.001"warmup_max_lr": 0.001,//预热阶段的步数,这里是1000"warmup_num_steps": 1000}},//是否开启时间分解功能,用于分析训练过程中的时间消耗。//这里是false,表示不开启"wall_clock_breakdown": false
}
以上即为利用DeepSpeed开发模型的过程,由此可见,和Pytorch开发模型的过程大同小异,就是在初始化的时候使用了DeepSpeed,并以输入参数的形式初始化。
测试代码
首先,使用环境变量控制GPU,例如机器有10张GPU,但是只使用6, 7, 8, 9号GPU,输入命令:
export CUDA_VISIBLE_DEVICES="6,7,8,9"
然后开始运行代码:
deepspeed test.py --deepspeed_config config.json
如下图所示即为开始运行。
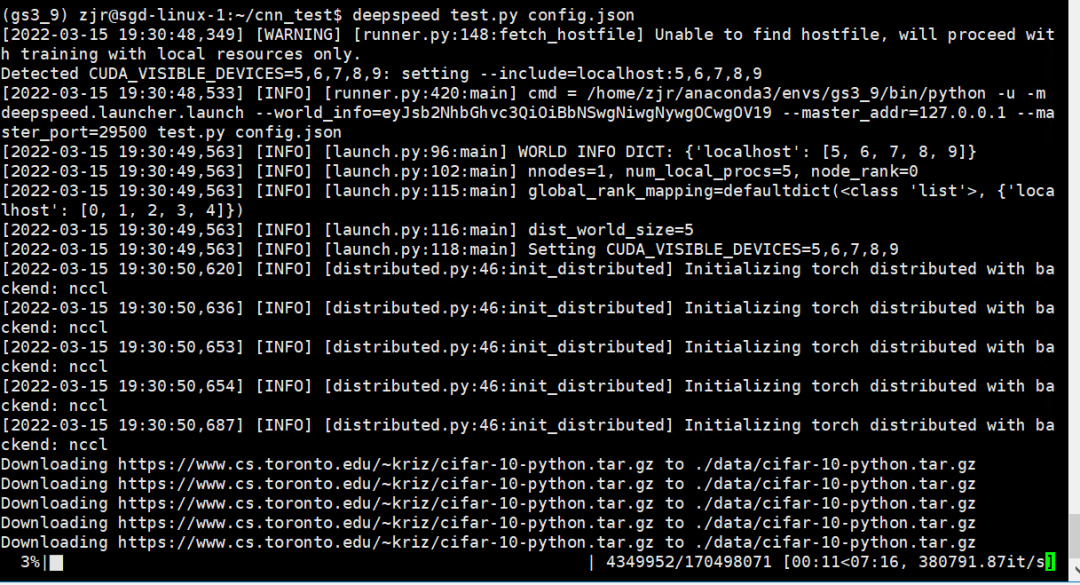
开始训练的时候DeepSpeed通常会打印更多的训练细节供用户监控,包括训练设置、性能统计和损失趋势,效果类似于:
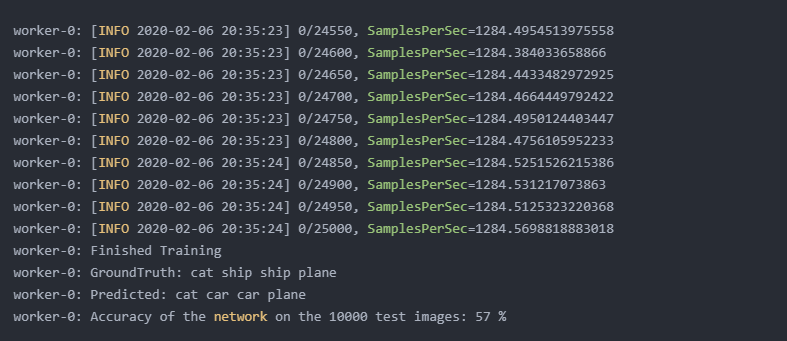
这也说明第一个Deepspeed模型已完成,下来可以开始大规模训练之路了!
这篇关于一文搞懂大模型训练加速框架 DeepSpeed 的使用方法!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




