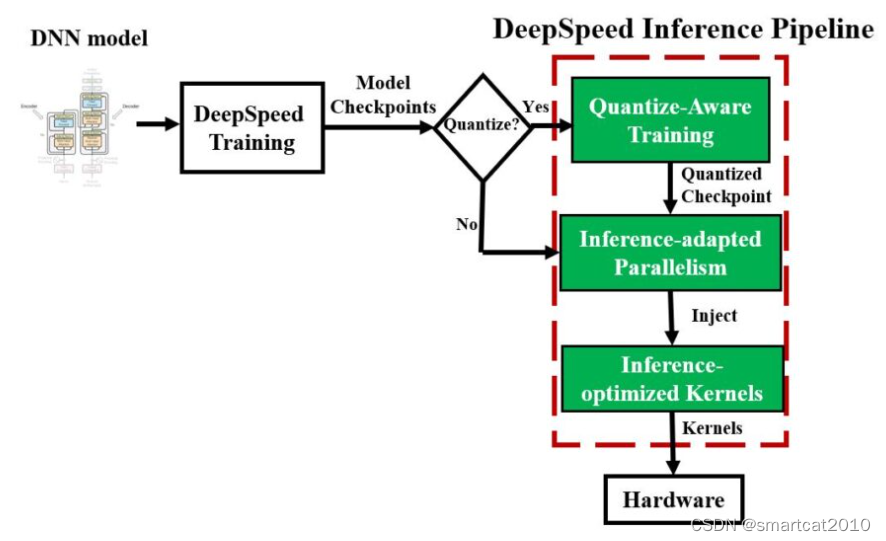
本文主要是介绍DeepSpeed Autotuning,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AutoTuning
用不同的系统参数试跑用户的模型训练,尝试不同的参数组合,给出每种参数组合的速度,供用户去选择较块的来进行真正的训练。
ZeRO optimization stages;micro-batch sizes;optimizer, scheduler, fp16等;
在DeepSpeed配置文件里,设定:
"autotuning": { "enabled": true }
如果想在batch size上进行枚举,设置:
"train_micro_batch_size_per_gpu": "auto"
fast-mode试跑(大概27分钟跑完),结果:(gas是gradient accumulation steps;tmbspg是train micro-batch-size per GPU)
| tuning_space | num_experiments | best_metric_val | best_exp_name |
|---|---|---|---|
| z0 | 4 | 59.0229 | z0_gas1_tmbspg2 |
| z1 | 5 | 87.3017 | z1_gas1_tmbspg3 |
| z2 | 3 | 77.8338 | z2_gas1_tmbspg3 |
| z3 | 1 | 0 | z3_gas1_tmbspg3 |
| global | 13 | 87.3017 | z1_gas1_tmbspg3 |
这篇关于DeepSpeed Autotuning的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!