本文主要是介绍DeepSpeed Learning Rate Scheduler,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Learning Rate Range Test (LRRT)
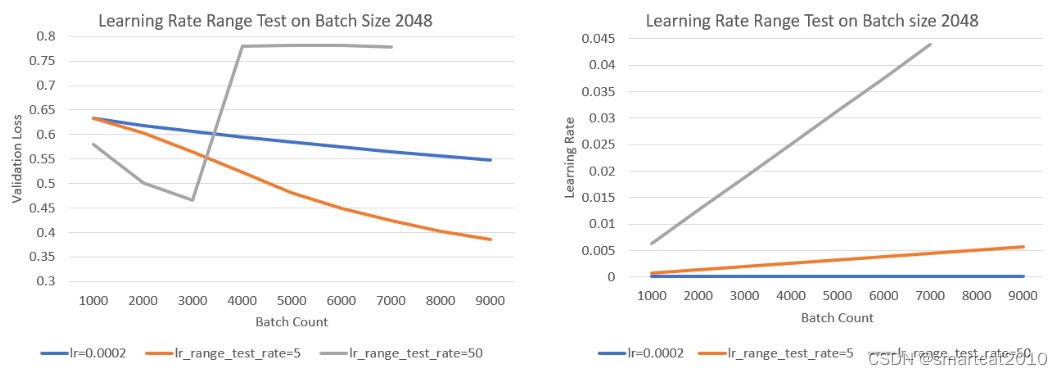
训练试跑,该lr scheduler从小到大增长lr,同时记录下validatin loss;人来观察在训练多少step之后,loss崩掉(diverge)了,进而为真正跑训练,挑选合适的lr区间;
"scheduler": {"type": "LRRangeTest","params": {"lr_range_test_min_lr": 0.0001,"lr_range_test_step_size": 200,"lr_range_test_step_rate": 5,"lr_range_test_staircase": false} }试3种不同的lr:
如上图,灰线lr增长的块,前面学得更快,某一时刻就diverge了;
橙线lr增长慢,但最终val-loss要比灰线的最低点要低;
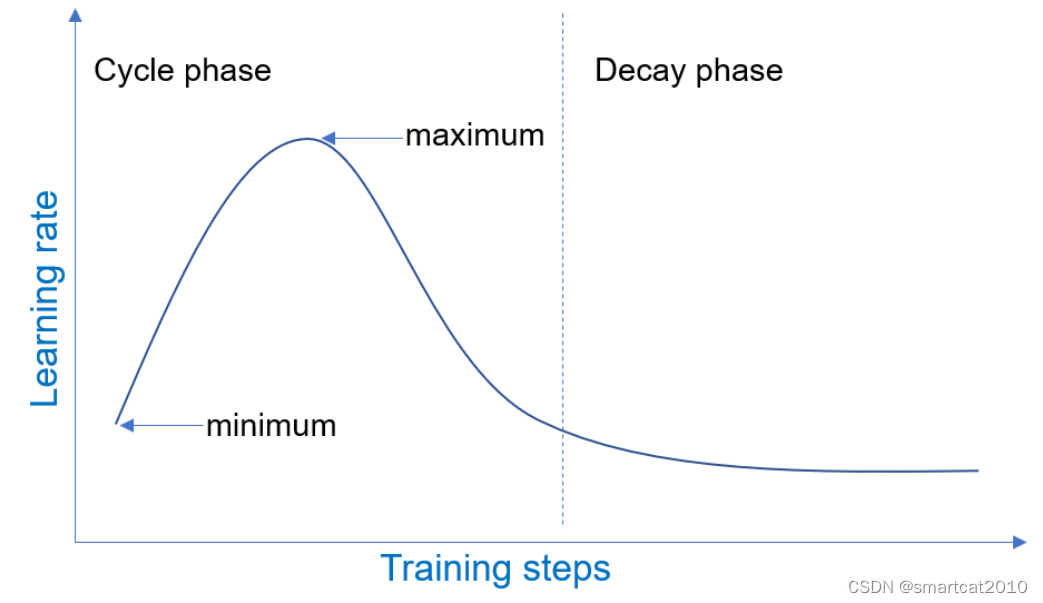
1-Cycle
解决痛点:多GPU训练时,batch-size较大,收敛非常慢;
Cycle阶段,先上升,再下降回到起始点;Decay阶段,缓慢下降;
这篇关于DeepSpeed Learning Rate Scheduler的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








