scheduler专题

Springboot如何配置Scheduler定时器
《Springboot如何配置Scheduler定时器》:本文主要介绍Springboot如何配置Scheduler定时器问题,具有很好的参考价值,希望对大家有所帮助,如有错误或未考虑完全的地方,... 目录Springboot配置Scheduler定时器1.在启动类上添加 @EnableSchedulin

Kubernetes Scheduler:Pod调度的双步骤—预选(Predicates)和优选(Priorities)
Kubernetes Scheduler:Pod调度的双步骤—预选(Predicates)和优选(Priorities) 1、预选(Predicates)2、优选(Priorities) 💖The Begin💖点点关注,收藏不迷路💖 在Kubernetes中,Pod的调度是由Scheduler负责的。Scheduler通过两个关键步骤——预选(Predicat
什么是Kubernetes Scheduler?
什么是Kubernetes Scheduler? 1、什么是Kubernetes Scheduler?2、Scheduler的作用2.1 承上2.2 启下 3、实现原理 💖The Begin💖点点关注,收藏不迷路💖 在Kubernetes中,每个Pod都需要一个“家”——Node来运行。Kubernetes Scheduler就是那位帮助Pod找到理想归宿的“

日程安排组件DHTMLX Scheduler v7.1 - 支持RFC-5545格式
DHTMLX Scheduler是一个类似于Google日历的JavaScript日程安排控件,日历事件通过Ajax动态加载,支持通过拖放功能调整事件日期和时间,事件可以按天、周、月三个种视图显示。 此版本包括几个备受期待的特性,可以帮助用户增强DHTMLX Scheduler的体验。您可以使用流行的RFC-5545格式在日程安排日历中存储循环事件,同时还扩展了地图视图的功能,从v7.1开始,可

java定时器task:scheduler和quartz
在javaweb项目中,经常用到定时器功能,这里介绍两个我使用过的解决方案,分别是:scheduler 和 quartz。 scheduler: 需要在spring.xml配置文件中添加关于task的配置: <beans xmlns:task="http://www.springframework.org/schema/task" xsi:schemaLocation="

kube-scheduler调度策略之优选算法(四)
一、概述 摘要: 本文我们继续从源码层面分析kube-scheduler调度策略中的优选调度算法,分析优选算法如何对Node节点进行打分的。 二、正文 说明:基于 kubernetes v1.12.0 源码分析 上文我们说的(g *genericScheduler) Schedule()函数调用了PrioritizeNodes()执行优选策略(打分),接下来我们就具体展开分析。 2

kube-scheduler调度策略之预选策略(三)
一、概述 摘要:本文我们继续分析源码,并聚焦在预选策略的调度过程的执行。 二、正文 说明:基于 kubernetes v1.12.0 源码分析 上文我们说的(g *genericScheduler) Schedule()函数调用了findNodesThatFit()执行预选策略。 2.1 findNodesThatFit 先找到改函数对应的源码 // k8s.io/kuber
Spring Boot集成Spring Cloud Scheduler进行任务调度
Spring Boot集成Spring Cloud Scheduler进行任务调度 大家好,我是微赚淘客返利系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿! 任务调度是后端服务中常见的需求,用于执行定时任务或周期性的工作。Spring Cloud Scheduler提供了对Spring Boot应用的任务调度支持,允许开发者以声明式的方式配置和执行任务。 Spring Cloud

kube-scheduler调度任务的执行过程分析与源码解读(二)
概述 摘要: 上文我们对Kube-scheduler的启动流程进行了分析,本文继续探究kube-scheduler执行pod的调度任务的过程。 正文 说明:基于 kubernetes v1.12.0 源码分析 上文讲到kube-scheduler组件通过sched.Run() 启动调度器实例。在sched.Run() 中循环的执行sched.scheduleOne获取一个pod,并执

Spark源码分析之-scheduler模块
原文链接:http://jerryshao.me/architecture/2013/04/21/Spark%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%E4%B9%8B-scheduler%E6%A8%A1%E5%9D%97/ Background Spark在资源管理和调度方式上采用了类似于Hadoop YARN的方式,最上层是资源调度器,它负责分配资
Documentation_scheduler_sched-rt-group.txt
如果想评论或更新本文的内容,请直接联系原文档的维护者。 如果你使用英文交流有困难的话,也可以向中文版维护者求助。 如果本翻译更新不及时或者翻译存在问题,请联系中文版维护者。 中文版维护者: 陶莹莉 tyl18768122426@163.com 中文版翻译者: 陶莹莉 tyl18768122426@163.com 中文版校译者: 陶莹莉 tyl18768122426@163.co
Documentation_scheduler_sched-nice-design
Chinese translated version of Documentation/scheduler/sched-nice-design Documentation/scheduler/sched-nice-design 的中文翻译 If you have any comment or update to the content, please contact the original
oracle SCHEDULER
从Oracle 10g开始,推荐使用DBMS_SCHEDULER包,因为它提供了更强大的功能和灵活性,包括更复杂的调度规则、依赖管理和事件驱动等 1. 用法 DBMS_SCHEDULER.CREATE_JOB (job_name IN VARCHAR2,job_type IN VARCHAR2,job_action IN
Task Scheduler问题及解法
问题描述: Given a char array representing tasks CPU need to do. It contains capital letters A to Z where different letters represent different tasks.Tasks could be done without original order. Each ta
RT-Thread内核源码分析-rt_system_scheduler_start与rt_schedule区别
rt_system_scheduler_start 与 rt_schedule的区别 rt_system_scheduler_start:用于启动RT-Thread内核调度器,该函数是不会返回的, 在该函数调用之前创建的线程是不会被调度的。 rt_schedule: 触发内核调度操作, 用于从一个线程切换到另一个线程。
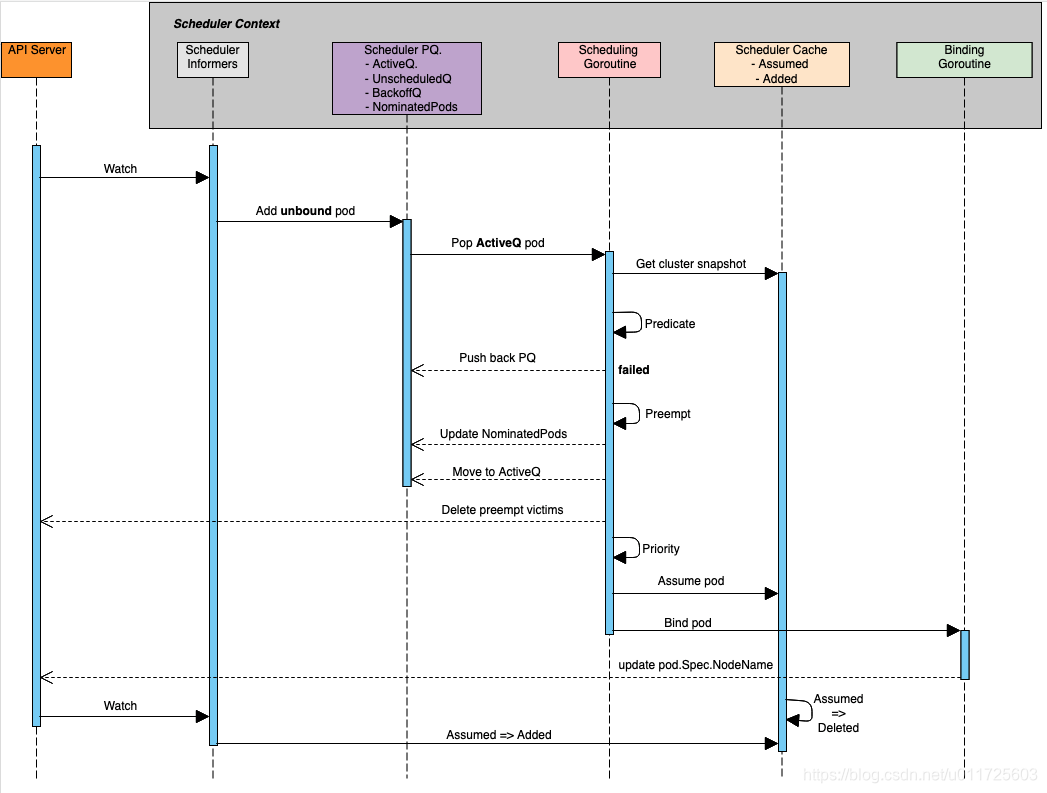
一文读懂Kubernetes Scheduler扩展功能
前言 Scheduler是Kubernetes组件中功能&逻辑相对单一&简单的模块,它主要的作用是:watch kube-apiserver,监听PodSpec.NodeName为空的pod,并利用预选和优选算法为该pod选择一个最佳的调度节点,最终将pod与该节点进行绑定,使pod调度在该节点上运行 展开上述调用流程中的scheduler部分,内部细节调用(参考Kubernetes Sc
深挖Openstack Nova - Scheduler调度策略(2)
当OpenStack自带的调度算法无法满足自己的业务需求时,这时我们可以增加自定义调度器。 现在有如下需求: 需求1. 同一项目的多个实例分散到不同的计算节点上; 需求2. 机柜感知 - 同一项目的多个实例分散到不同的机柜上; 需求3. 要求实例B不放在与实例A相同的节点上。 思路: 需求1: (1)自带的ServerGroupAntiAffinityFilter过滤器可解决
深挖Openstack Nova - Scheduler调度策略(1)
一. Scheduler的作用就是在创建实例(instance)时,为实例选择出合适的主机(host)。这个过程分两步:过滤(Fliter)和计算权值(Weight) 1. 过滤: 过滤掉不符合我们的要求,或镜像要求(比如物理节点不支持64bit,物理节点不支持Vmware EXi等)的主机,留下符合过滤算法的主机集合。 2. 计算权值 通过指定的权值计算算法,计算在某物理节点上申请这个

cocos-lua 延时执行 和 scheduler
1.开始 [plain] view plain copy local scheduler = cc.Director:getInstance():getScheduler() local schedulerID = nil schedulerID = scheduler:scheduleScriptFunc(function() print("He
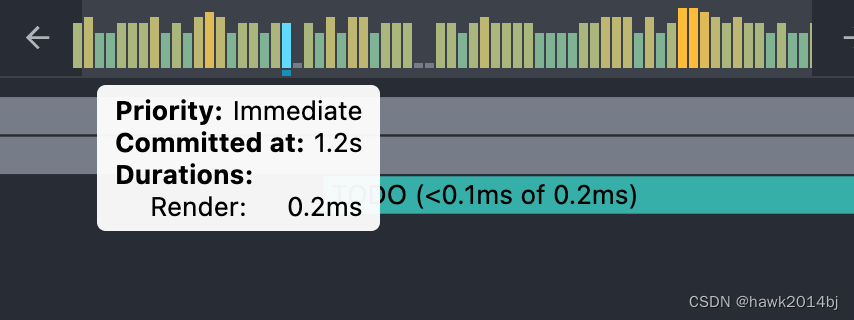
React中的 Scheduler
为什么需要调度 在 React 中,组件最终体现为 Fiber,并形成 FiberTree,Fiber 的目的是提高渲染性能,将原先的 React 渲染任务拆分为多个小的微任务,这样做的目的是可以灵活的让出主线程,可以随时打断渲染,后面再继续执行。由于需要让出主线程,需要将任务保存起来,一个个排队执行,需要的时候进行切换,为了实现排队、切换,就需要实现一个调度引擎,哪个任务先执行,哪个任务后执行
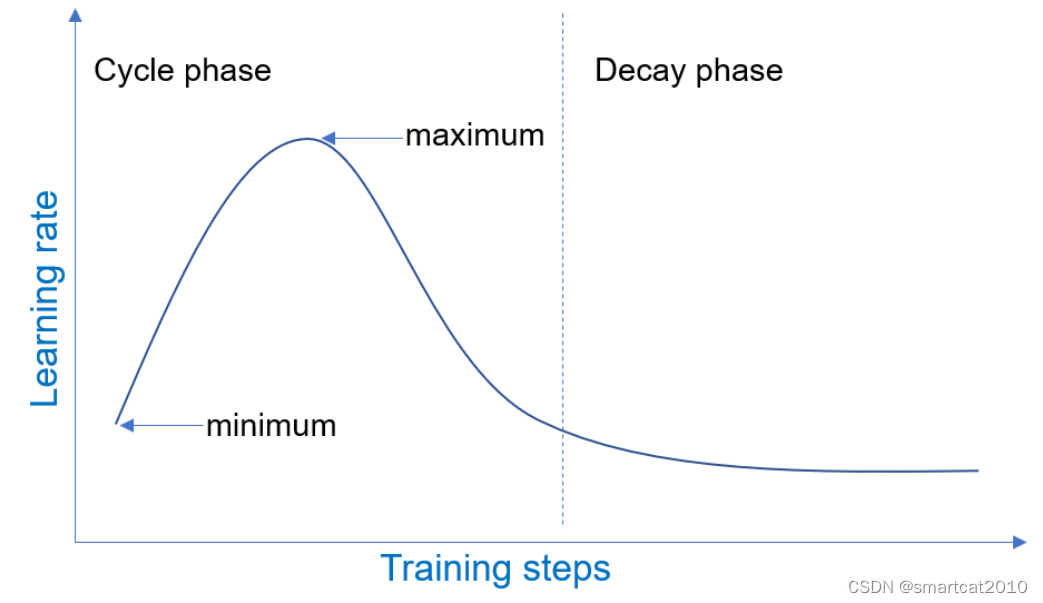
DeepSpeed Learning Rate Scheduler
Learning Rate Range Test (LRRT) 训练试跑,该lr scheduler从小到大增长lr,同时记录下validatin loss;人来观察在训练多少step之后,loss崩掉(diverge)了,进而为真正跑训练,挑选合适的lr区间; "scheduler": {"type": "LRRangeTest","params": {"lr_range_test_min_l
Oracle作业调度器Job Scheduler
Oracle数据库调度器 (Oracle Database Scheduler) 在数据库管理系统中,数据库调度器负责调度和执行数据库中的存储过程、触发器、事件等。它可以确保这些操作在正确的时间和条件下得到执行,以满足业务需求。 1、授权用户权限 -- 创建目录对象 tmp_dir CREATE OR REPLACE DIRECTORY tmp_dir AS '/tmp';-- 授予用户
关于scheduler相关的概念
Scheduler 中的Program对象并不是常规意义上的"程序"或"应用",而就是一个"对象",由 DBA定义的,具有执行某项功能的特殊对象。Program中实际执行的操作可以分为下列三种类 型: 1.PL/SQL BLOCK :标准的pl/sql 代码块; 2.STORED PROCEDURE :编译好的PL/SQL 存储过程,或者Java 存储过程,以及外部的c 子 程序; 3
The Scheduler supports types
文档地址:http://docs.oracle.com/cd/B19306_01/server.102/b14220/mgmt_db.htm#sthref2285 Schedule JobExecution The most basic capability of a job scheduler is to schedule theexecution of a job. The Sc
scheduler 怎样得到 next task_struct
/**/ __schedule 调用函数pick_next_task从rq中得到一个task /* * Pick up the highest-prio task: */ static inline struct task_struct * pick_next_task(struct rq *rq) { const struct sched_class *
Spring Boot集成Spring Task Scheduler快速入门demo
1.Spring Task Scheduler介绍 Spring Scheduler里有两个概念:任务(Task)和运行任务的框架(TaskExecutor/TaskScheduler)。TaskExecutor顾名思义,是任务的执行器,允许我们异步执行多个任务。TaskScheduler是任务调度器,来运行未来的定时任务。触发器Trigger可以决定定时任务是否该运行了,最常用的触发器是Cro