本文主要是介绍大模型并行训练、推理框架Deepspeed简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 一.简介
- 二.分布式训练方法
- 1.数据并行
- 2.张量并行
- 3.流水线并行
- 三.ZeRO
- 1.模型的显存占用
- 2.ZeRO-1/2/3
- 3.ZeRO-Offload
- 4.ZeRO-Infinity
- 四.总结
- 五.参考
传送门:https://github.com/wzzzd/LLM_Learning_Note/blob/main/Parallel/deepspeed.md
一.简介
Deepspeed是微软推出的一个开源分布式工具,其集合了分布式训练、推断、压缩等高效模块。
该工具旨在提高大规模模型训练的效率和可扩展性。
它通过多种技术手段来加速训练,包括模型并行化、梯度累积、动态精度缩放、本地模式混合精度等。
DeepSpeed还提供了一些辅助工具,如分布式训练管理、内存优化和模型压缩等,以帮助开发者更好地管理和优化大规模深度学习训练任务。
此外,deepspeed基于pytorch构建,只需要简单修改即可迁移。
DeepSpeed已经在许多大规模深度学习项目中得到了应用,包括语言模型、图像分类、目标检测等。

二.分布式训练方法
如今的大模型训练,离不开各种分布式的训练框架,一般来说,并行策略包含:数据并行、模型并行、流水线并行。
1.数据并行
数据并行分为了两种模式:Data Parallel(DP)和 Distributed Data Parallel(DDP)。
Data Parallel(DP)
DP是一种单进程多线程的并行策略,只能在单机上进行训练,步骤如下:
- 单进程控制多GPU,即本质上是单进程多线程;
- 首先将模型加载到主 GPU 上,再复制到各个指定从 GPU;
- 将输入数据按照 Batch 维度进行拆分,各个 GPU 独立进行 forward 计算;
- 将结果同步给主 GPU 完成梯度计算和参数更新,将更新后的参数复制到各个 GPU。
由于其是单进程控制多个GPU,故会存在GPU之间负载不均衡的问题,主GPU负载较大。
Distributed Data Parallel(DDP)
DDP采用 AllReduce 架构,多进程的方式,突破锁的束缚。在单机和多机上都可以使用。
负载分散在每个 GPU 节点上,通信成本(时间)是恒定的,与 GPU 数量无关,等于V/B(参数量/带宽)。
DDP不需要通过主GPU分发全模型的参数到每个GPU上。
使用ring-all-reduce的方式进行通讯,随着 GPU 数量 N 增加,总传输量恒定。也就是理论上,随着GPU数量的增加,ring all-reduce有线性加速能力。
2.张量并行
张量并行的原理是,将张量操作划分到多个设备上,以加速计算或增加模型大小;对模型每一层的层内参数进行切分,即对参数矩阵切片,并将不同切片放到不同GPU上;将原本在单卡中的矩阵乘法,切分到不同卡中进行矩阵乘法。训练过程中,正向和反向传播计算出的数据通过使用 All gather 或者 All reduce 的方法完成整合。
以transformer为例,该策略会把 Masked Multi Self Attention 和 Feed Forward 都进行切分以并行化。利用 Transformers 网络的结构,通过添加一些同步原语来创建一个简单的模型并行实现。
张量并行适用于模型单层网络参数较大的情况。同时缺点也是十分明显:
- 若环境是多机多卡,张量并行所需的all-reduce通信需要跨服务器进行链接,这比单机多GPU服务器内的高带宽通信要慢;
- 高度的模型并行会产生很多小矩阵乘法,这可能会降低GPU的利用率。
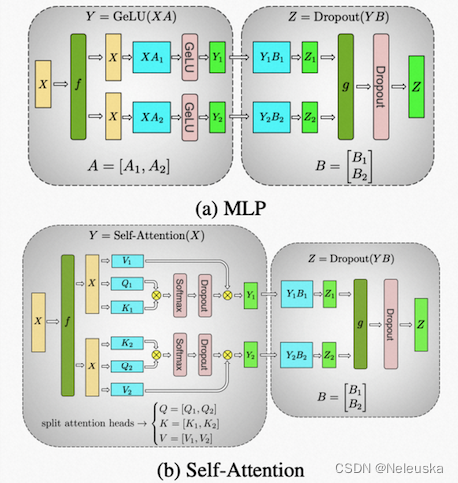
3.流水线并行
流水线原理是将不同的 layer 分配给指定 GPU 进行计算,流水线并行只需其之间点对点地通讯传递部分 activations。
具体步骤包括:
- 在流水线并行之中,一个模型的各层会在多个GPU上做切分。
- 一个批次(batch)被分割成较小的微批(microbatches),并在这些微批上进行流水线式执行。
- 通过流水线并行,一个模型的层被分散到多个设备上。
- 当用于具有相同transformer块重复的模型时,每个设备可以被分配相同数量的transformer层。
- 在流水线模型并行中,训练会在一个设备上执行一组操作,然后将输出传递到流水线中下一个设备,下一个设备将执行另一组不同操作。
流水线并行的方法,解决了超大模型无法在单设备上装下的难题,也解决了机器之间的通信开销的问题,使得每台机器的数据传输量跟总的网络大小、机器总数、并行规模无关。
常用的流水线方法有G-pipe、PipeDream、virtual pipeline等。

三.ZeRO
ZeRO(Zero Redundancy Optimizer)是一种去除冗余的并行方案,来自微软在SC 20 上发表的论文ZeRO: Memory Optimizations Toward Training Trillion Parameter Models.而Deepspeed库最初的就是关于ZeRO的官方实现。也是Deepspeed实现3D并行(数据、模型、流水线)的主要模块。
1.模型的显存占用
让我们来看看,当使用GPU训练模型的时候,显存中都被哪些东西占用。
从下图可以看到,GPU需要存储优化器状态(Optimizer States)、模型参数(Model Parameters)、激活值(Activations)、梯度(Gradients)、临时缓存(Temporary Buffers)等。
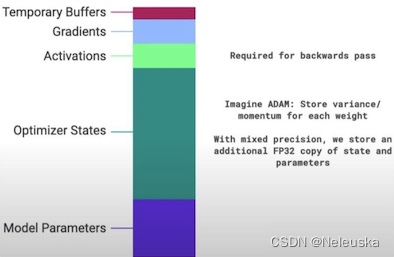
模型参数只是占用其中的一部分,当使用混合精度进行训练时,模型状态(Model Parameters+Optimizer States+Gradients)会站到一大半以上。
模型参数(Model Parameters)、梯度(Gradients)会使用FP16精度进行存储。优化器状态(Optimizer States)是进行梯度更新时用到的数据,例如使用Adam优化器时,除了需要保存以FP32精度存储的模型参数外,还需要以FP32的精度存储Variance和Momentum的参数值。
2.ZeRO-1/2/3
微软提出的ZeRO针对并行训练的场景,对模型状态(Model Parameters+Optimizer States+Gradients)提出了3种不同程度的分割。目的在于将数据、以及模型本身的参数、优化器的状态、激活函数的输出值、梯度等切分并放在不同的GPU上,以此实现并行训练。
ZeRO包含3种级别:
- ZeRO-1 : Optimizer States Partitioning(P_os)
- ZeRO-2 : Optimizer States & Gradients Partitioning(P_os+g)
- ZeRO-3 : Optimizer States & Gradients Partitioning & Parameters Partitioning(P_os+g+p)
(1)ZeRO-1
- 原理
- 只对优化器Optimizer进行分片(与DDP过程相似)
- 每个rank(gpu)单独负责 forward和backward过程,在完成backward后,梯度通过AllReduce来同步。
- 每个rank只负责更新当前优化器分片的部分,由于每个rank只有部分分片的优化器state,所以当前rank会忽略其余的state。
- 在更新优化器state后,通过广播或者AllGather的方式,确保所有的rank都收到最新更新过后的模型参数。
- 优点
- 适合使用类似Adam进行优化的模型训练
- 因为Adam拥有额外的参数m(momentum)与v(variance),特别是FP16混合精度训练。
- 减少了4倍显存,通信容量与数据并行相同
- 适合使用类似Adam进行优化的模型训练
- 缺点
- 不适合使用SGD类似的优化器进行模型训练
- 因为SGD只有较少的参数内存,并且由于需要更新模型参数,导致额外的通讯成本。
- 只是解决了Optimizer state的冗余。
- 不适合使用SGD类似的优化器进行模型训练
(2)ZeRO-2
- 原理
- 对优化器Optimizer、gradients进行分片
- Optimizer参数被分片,并安排在不同的rank上
- 在backward过程中,gradients在不同的rank上独自进行reduce操作(取代了all-reduce,以此减少了通讯开销),每个rank独自更新各自负责的参数。
- 在更新操作之后,广播或AllGather,保证所有的ranks接受到更新后的参数。
- 优点
- 减少了8倍显存,通信容量与数据并行相同
(3)ZeRO-3
- 原理
- 对优化器Optimizer、gradients、model parameter进行分片
- AllReduce操作可以被拆分为Reduce与allgather操作的结合。
- 模型的每一层拥有该层的完整参数,并且整个层能够直接被一个GPU装下。所以计算前向的时候,除了当前rank需要的层之外,其余的层的参数可以抛弃。
- 每个rank计算forward过程
- 使用AllGather获取模型该层所需的前置的层的参数。
- 结束后释放掉不属于该rank分片的层的参数。
- 每个rank计算backward过程
- 使用AllGather获取该层所需要的层之前过程的参数。
- 结束后释放掉不属于该rank分片的层的参数。
- 使用Reduce对当前分片的参数的梯度进行累加。
- 让每个rank根据聚合的梯度,独立更新参数。
- 对优化器Optimizer、gradients、model parameter进行分片
- 优点
- 内存减少与数据并行度和复杂度成线性关系。

3.ZeRO-Offload
Offload是一种通过将数据和计算从 GPU 卸载到 CPU,以此减少训练期间 GPU 内存占用的方法。该方法提供了更高的训练吞吐量,并避免了移动数据和在 CPU 上执行计算导致的减速问题。
在单张V100 GPU的情况下,用PyTorch能训练1.4B的模型,吞吐量是30TFLOPS,有了ZeRO-Offload加持,可以训练10B的模型,并且吞吐量40TFLOPS。
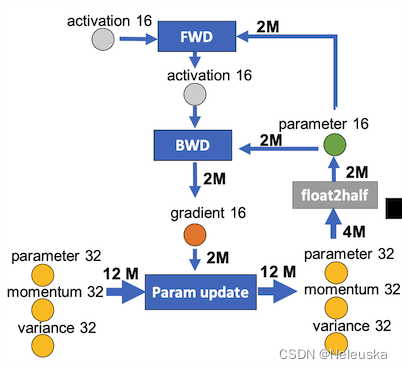
切分思路
下图中左图是一个使用混合精度的模型训练和参数更新过程。包含了4类节点:FWD、BWD、Param update、float2half。M表示模型的参数量,2M表示使用FP16(FP16 =2 Byte),4M表示FP32,12M表示3xFP32。
右图是使用Offload的流程,前后向(FWD/BWD) 这两个计算资源消耗较大的过程放到GPU上执行,参数更新和精度转换放在CPU上执行,也就是将Adam过程放在CPU上。

计算思路
CPU
- ① 保存着优化器状态
- ④ CPU中的每个数据并行线程,进行优化器状态分割的更新(p update)
- ⑤ 将参数分割移回GPU
GPU
- ② forward和backward过程都在GPU上进行
- ③ backward利用reduce-scatter计算求和均值,然后按照数据并行线程,将分割的梯度平均值卸载到CPU内存中(g offload)
- ⑥ 执行all-gather操作,收集所有更新后的参数(g swap)

在使用带有单张英伟达 V100 GPU 的机器时,可以在不耗尽显存的情况下,运行多达130亿个参数的模型,模型规模扩展至现有方法的10倍,保持有竞争力的吞吐量。

4.ZeRO-Infinity
模型参数量增长的速度,远快于GPU的喜爱内存增长速度,则存在内存墙问题。例如GPT1到GPT3,两年时间参数量从0.1B增长到了175B,而同期,NIVIDIA则只是从V100 32GB更新到A100 80GB。
ZeRO-infinity在ZeRO-Offload的基础上进一步优化,除了利用GPU显存和CPU内存外,还利用了NVMe磁盘空间。用了这些异构存储器,ZeRO-infinity突破了GPU内存壁垒。
infinity卸载引擎通过使用CPU和NVMe内存增加了可用于存储模型参数和激活的内存量;与前几代ZeRO不同,infinity引擎可以将整个模型卸载到这些位置。
以内存为中心的平铺是另一项新技术,它通过将大的模型层分解成较小的 "平铺 "来减少对内存的占用,这些平铺可以按顺序执行;这允许在不需要模型并行的情况下训练大型模型。
为了处理带宽问题,ZeRO-Infinity引入了以带宽为中心的分区,将模型参数划分到多个数据并行进程中,还有一个重叠引擎,同时执行NVM到CPU、CPU到GPU以及GPU到GPU的通信。
下图比较了 3D 并行和 ZeRO-Infinity 所能达到的最大模型规模,其支持每个 NVIDIA V100 DGX-2 节点 1 万亿个参数,相比 3D 并行增加了 50 倍。

四.总结
随着时间推移,模型会走向两个极端,一方面会越来越大,往世界模型的方向发展;另外一方面会相对变小,能够落地到具体的业务场景中应用。
不管站在哪一个角度,硬件和软件架构都是模型性能的瓶颈。期待更多像Deepspeed这类能提升大模型效率的工具在未来能够继续发展。
五.参考
- Microsoft/DeepSpeed
- ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
- ZeRO-Offload: Democratizing Billion-Scale Model Training
- ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
- 大语言模型(LLM)分布式训练框架总结
- DeepSpeed之ZeRO系列:将显存优化进行到底
- 数据并行Deep-dive: 从DP 到 Fully Sharded Data Parallel (FSDP)完全分片数据并行
这篇关于大模型并行训练、推理框架Deepspeed简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





