本文主要是介绍Deepspeed、ZeRO、FSDP、ZeRO-Offload、all reduce、reduce-scatter,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Transformer为基础的大模型应该如何并行
- 数据并行。但是如果模型太大放不到一块卡上就没用了。为了解决把参数放到一块卡上的问题,演进出了论文Zero的思想,分为Zero-DP和Zero-R两部分。Zero-DP是解决Data parallel的问题,并行过程中内容不够,解决思路也比较简单,模型参数w只存在一台机器上,剩下的部分等用的时候找某台机器通过all-reduce请求就可以了。Zero-R是在每一层输入存不下,解决思想是带宽换内存。由Zero论文演进的Deep-speed框架影响了pytorch分布式计算的接口。
- 模型并行。典型的是按照GPipe的思路,将模型按层切开,这样会实现像CPU流水线一样并行的设计。
- 张量并行。典型的是Megatron LM,其实就是将矩阵乘法切开,参考下图:

DeepSpeed中参数量的估计
-
基本问题:在理解ZeRO前需要先理解一个基本问题,对于一个参数量为 Φ \Phi Φ的模型,使用Adam优化器单卡进行混合精度训练过程中至少占多大显存?结果是16* Φ \Phi Φ,分为以下两个部分:
- 模型参数、模型梯度使用半精度FP16进行保存,模型迭代前向反向过程使用的都是FP16,因此对于模型参数、模型梯度的存储需要2* Φ \Phi Φ+2* Φ \Phi Φ个字节(半精度FP16或者BF16占用两个字节所以*2),也就是下图红框中的2+2
- 在optimizer进行模型参数更新时,由于需要大量的累加和乘运算,半精度在这时经常出现精度溢出的情况,因此这时还是换回用FP32来优化,这也是混合精度计算命名的由来。在Adam更新时,原来FP16保存的模型参数会转换成FP32,占用4个字节。Adam中存在一阶矩和二阶矩两个Optimizer state,各占4个字节,也就是8个字节。因此这部分一共需要12个字节,也就是下图蓝框中的K=12(当然使用不同优化器这部分占用的显存是不一样的,这里就不展开了)。

-
核心想法:ZeRO的贡献分为ZeRO-DP(Data Parallel)和ZeRO-R(Residual State Memory)两部分优化思路:
- ZeRO-DP实际上是利用参数服务器all reduce的思想把数据分到Nd块卡上,减少平均到每一块卡上的显存占用。DeepSpeed在实际使用中需要预先配置使用stage1(只数据并行上述K=12优化器状态部分的显存)或者stage2(数据并行上述K=12优化器状态部分+梯度部分的显存)或者stage3(数据并行上述K=12优化器状态部分+梯度部分+模型参数部分的显存),理解上图就理解了Zero工作的核心思想
- ZeRO-R(Residual State Memory),这里Residual State Memory主要几个trick的叠加:1. 神经网络或者多层Transformers总依赖前一层算完才能再算下一层,保存前一层的结果会也会占用显存,ZeRO-R这里采用的是时间换空间通过合理并行来减少显存的想法;2. Constant Size Buffers,多卡通信中如果数据包太大或者太小都不利于整体效率,作者这里做了合理的tradeoff
-
实际操作:由HuggingFace出的accelerate(https://huggingface.co/docs/accelerate/usage_guides/deepspeed)本身可以简化DeepSpeed的配置。DeepSpeed的配置项非常多,手动配置较容易出错,建议使用accelerate config完成初始配置后直接用accelerate launch不带其他accelerate参数启动code
-
视频讲解: 来自李沐老师对这篇文章的精读(https://www.bilibili.com/video/BV1tY411g7ZT?vd_source=e260233b721e72ff23328d5f4188b304)强烈推荐,文章本身写的啰里啰嗦的
-
论文地址: https://arxiv.org/pdf/1910.02054.pdf
Fully Sharded Data Parallel (FSDP)
FSDP来自facebook,对标微软在DeepSpeed中提出的Zero。FSDP可以看成PyTorch中的DDP优化版本,本身也是数据并行,但是和DDP不同的是,FSDP采用了parameter sharding,所谓的parameter sharding就是将模型参数也切分到各个GPUs上,而DDP每个GPU都要保存一份parameter,FSDP可以实现更好的训练效率(速度和显存使用),FSDP其实是和ZeRO-3更加接近
all-reduce=reduce-scatter+all-gather
在DDP中的操作是all-reduce,但是在FSDP中换成了reduce-scatter和all-gather,如下图
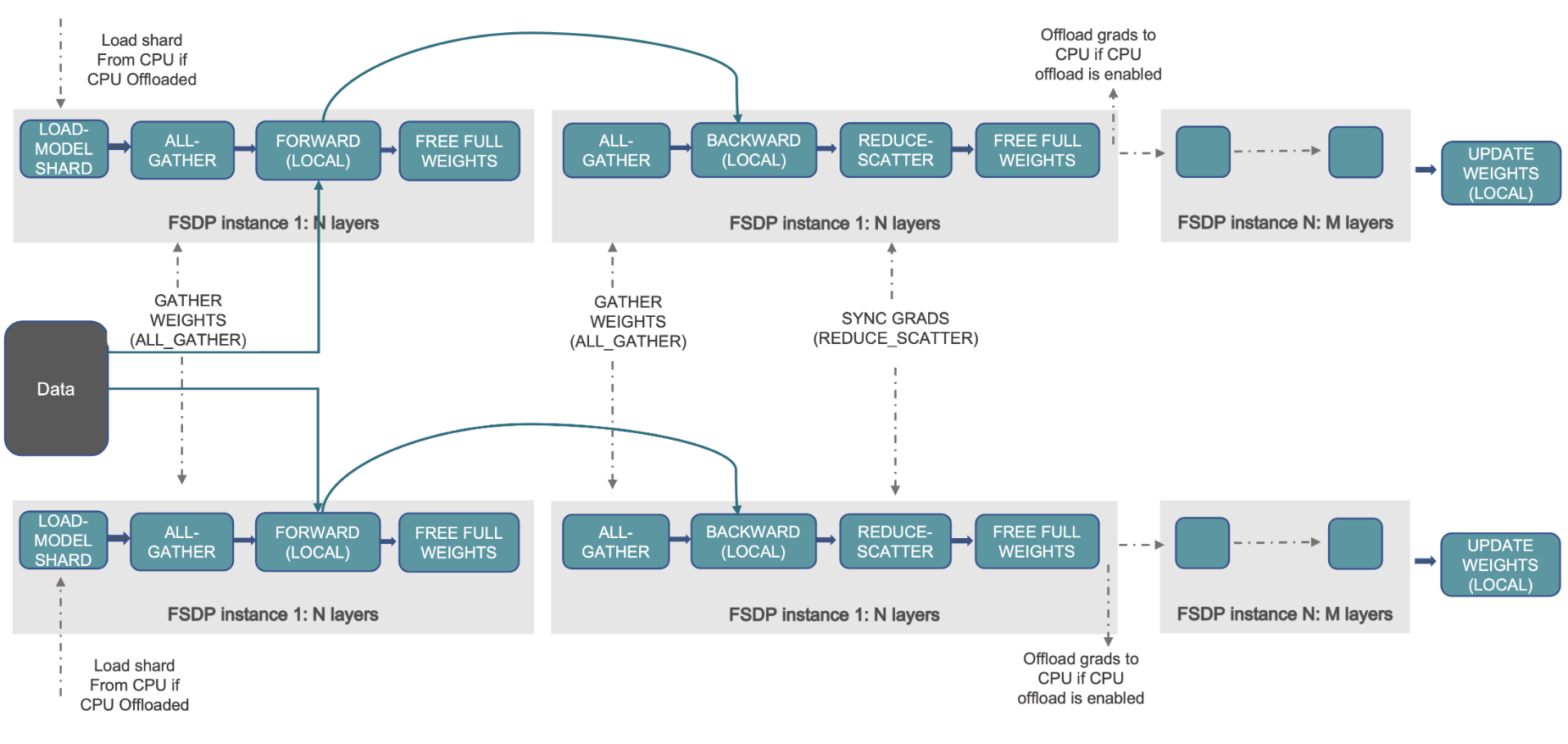
关于为什么all-reduce=reduce-scatter+all-gather?其实下面一张图解释的很清楚,引用https://engineering.fb.com/2021/07/15/open-source/fsdp/attachment/fsdp-graph-2a/的文字来说就是“All-reduce as a combination of reduce-scatter and all-gather. The standard all-reduce operation to aggregate gradients can be decomposed into two separate phases: reduce-scatter and all-gather. During the reduce-scatter phase, the gradients are summed in equal blocks among ranks on each GPU based on their rank index. During the all-gather phase, the sharded portion of aggregated gradients available on each GPU are made available to all GPUs (see here for details on those operators).” 简单来说就是把All Reduce这一步给打碎(scatter掉),如果直接all reduce,会存在广播的问题,带来的问题是带宽是瓶颈
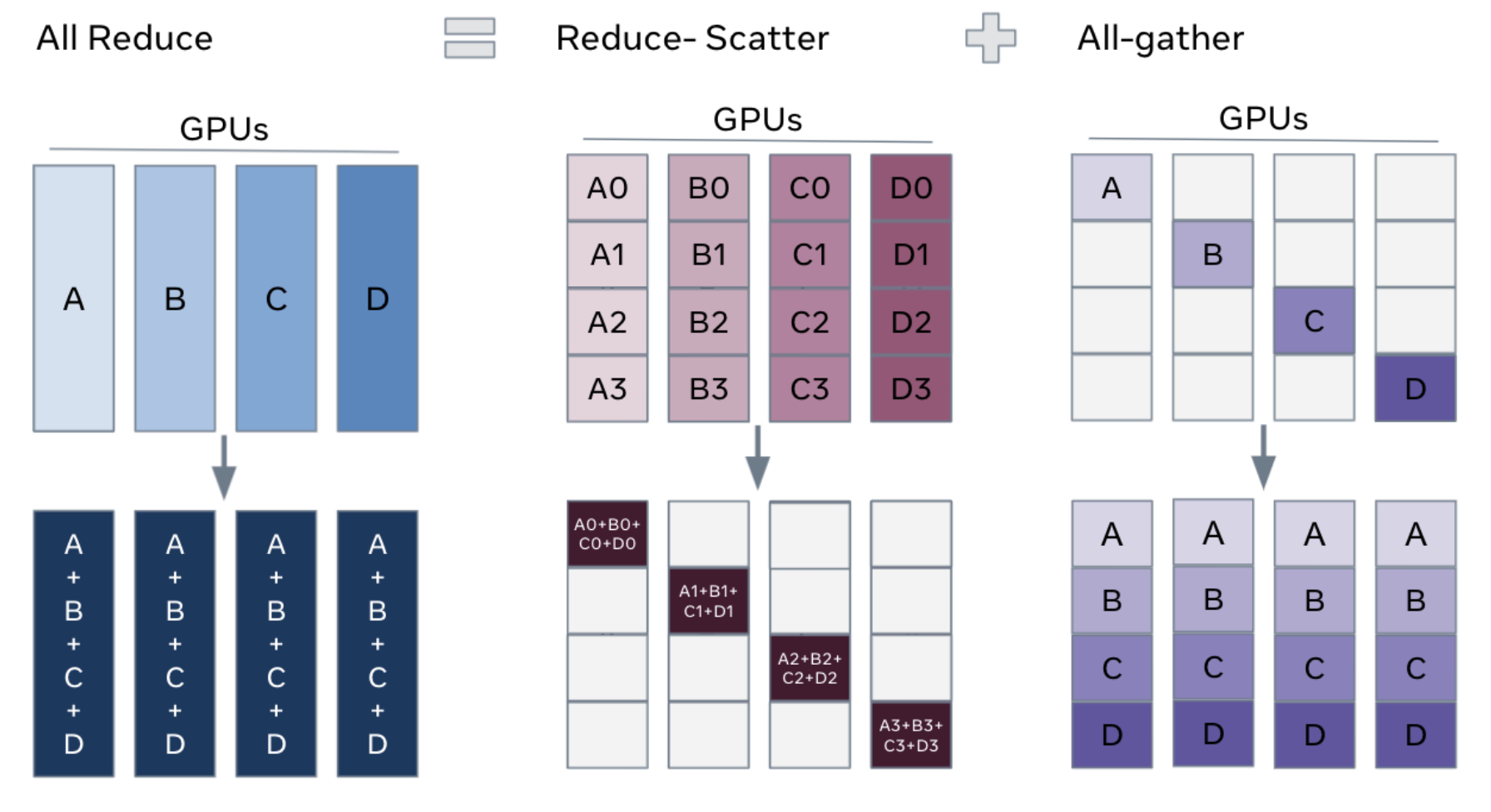
为什么带宽会成为瓶颈,可以参考一流科技的文章https://juejin.cn/post/7090798853711986695:

关于reduce-scatter这几个操作的定义可以参考英伟达的文档https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/collectives.html:

Zero-Offload
Zero-offload,也有被称为Zero4的, 这个甚至是一张卡都可以,Zero-offload就是针对GPU显存不够,甚至单卡的场景设计出来的。Zero-offload,为了优化各种算子的执行,把复杂的FWD和BWD放在了GPU上执行,而相对固定可控的算子param update和float2half就放在了CPU上进行运算,而这一部分除了相对算子简单以外,最重要的是Adam优化器本身是32bit的,把它放在CPU的内存上,会极大的节省GPU的显存。
这部分转载自:
- https://zhuanlan.zhihu.com/p/402232568
- https://www.zhihu.com/question/453941150/answer/3443788295
这篇关于Deepspeed、ZeRO、FSDP、ZeRO-Offload、all reduce、reduce-scatter的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








