bayes专题

回归预测 | Matlab基于贝叶斯算法优化XGBoost(BO-XGBoost/Bayes-XGBoost)的数据回归预测+交叉验证
回归预测 | Matlab基于贝叶斯算法优化XGBoost(BO-XGBoost/Bayes-XGBoost)的数据回归预测+交叉验证 目录 回归预测 | Matlab基于贝叶斯算法优化XGBoost(BO-XGBoost/Bayes-XGBoost)的数据回归预测+交叉验证效果一览基本介绍程序设计参考资料 效果一览 基本介绍 Matlab实现基于贝叶斯算法优化X

Naive Bayes分类器详解
##1. 贝叶斯定理 假设随机事件 A A A发生的概率是 P ( A ) P(A) P(A),随机事件 B B B发生的概率为 P ( B ) P(B) P(B),则在已知事件 A A A发生的条件下,事件 B B B发生的概率为: P ( B ∣ A ) = P ( A ∣ B ) P ( B ) P ( A ) P(B|A) = \frac {P(A|B)P(B)}{P(A)} P(B∣A

使用MapReduce实现Bayes算法
代码如下: NBayes.conf 4 cl1 cl2 cl3 cl4 3 p1 12 p2 16 p3 17 NBayes.train cl1 5 6 7 cl2 3 8 4 cl1 2 5 2 cl3 7 8 7 cl4 3 8 2 cl4 9 2 7 cl2 1 8 5 cl5 2 9 4 cl3 10 3 4 cl1 4 5 6 cl3 4 6 7 NBayes.test

Python机器学习分类算法(一)-- 朴素贝叶斯分类(Naive Bayes Classifier)
简要描述 朴素贝叶斯分类器(Naive Bayes Classifier)是一种基于贝叶斯定理与特征条件独立假设的分类方法。它之所以被称为“朴素”,是因为它假设输入特征(在特征向量中)是独立的,即一个特征的出现不依赖于其他特征的出现。这个假设在实际应用中通常不成立,但在很多情况下,朴素贝叶斯分类器仍然可以取得很好的效果。 工作原理 贝叶斯定理: 给定一个类别
0409——bayes的一丢丢理论
为什么用最小二乘法做线性回归 问题描述:给定平面上N个点,找出一条最佳描述了这些点的直线。 学过线性代数的大概都知道经典的最小二乘方法来做线性回归。一个接踵而来的问题就是,我们如何定义最佳? 我们设每个点的坐标为 (Xi, Yi) 。如果直线为 y = f(x) 。那么 (Xi, Yi) 跟直线对这个点的“预测”(Xi, f(Xi)) 就相差了一个 ΔYi = |Yi – f(Xi)|
0330——python实现bayes分类器
http://python.jobbole.com/81019/ 为了学习Beyas并且练习python,按照上面地址的文章里面,一步步的实现。由于python基础比较弱,所以最简单的程序,也有可能需要我没见过并且解决不了的问题。 1. 处理数据。 用的数据是pima-indians-diebetes.csv,上文贴出的该数据集的地址已经失效,从CSDN的下载区下载的。 数据共包括768行

数据挖掘算法之 Naive Bayes
一、什么是Naive Bayes? 在2分类的情况下:使用类别已知的初始对象(训练数据)构造一一个划分器,使得获得叫大分值的对象同类别1关联而获得较小分值的对象同类别0关联。划分器对新对象给出分值,将该对象的得分同某个预定的“分类阈值”进行比较即可实现分类,得分大于阈值就分到类别1,小于阈值就分到类别0。 据此扩充到多分类。 二、Naive Bayes 算法思想。 朴素
2.1 条件概率,全概率公式,Bayes公式
2.1 条件概率,全概率公式,Bayes公式 1.条件概率 对概率的讨论总是限制在一组固定条件下进行。以前的讨论总是假设除此以外再无其余信息可供使用。然而,我们有时却需要考虑:已知某一事件 B B B 已经发生,要求在该情况下另一事件 A A A 发生的概率这样的情况。我们所需要计算的概率实际上是“在已知事件 B B B 发生的条件下,事件 A A A 发生的概率”,我们记这个概率为:
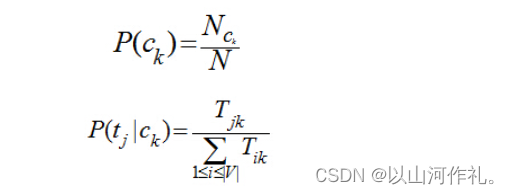
8.机器学习-十大算法之一朴素贝叶斯(Naive Bayes)算法原理讲解
8.机器学习-十大算法之一朴素贝叶斯(Naive Bayes)算法原理讲解 一·摘要二·个人简介三·朴素贝叶斯算法简介朴素贝叶斯算法概念贝叶斯方法朴素贝叶斯算法贝叶斯公式 四·贝叶斯算法的核心思想:利用贝叶斯定理进行分类五·优缺点优点缺点 六·朴素贝叶斯原理七·朴素贝叶斯分类器八·在文本分类上的应用 一·摘要 机器学习中的十大算法之一的朴素贝叶斯(Naive Bayes)算法,

Bayes判别示例数据:鸢尾花数据集
使用Bayes判别的R语言实例通常涉及使用朴素贝叶斯分类器。朴素贝叶斯分类器是一种简单的概率分类器,基于贝叶斯定理和特征之间的独立性假设。在R中,我们可以使用`e1071`包中的`naiveBayes`函数来实现这一算法。下面,我将通过一个简单的示例展示如何在R中应用朴素贝叶斯方法来进行数据分类。 示例数据:鸢尾花数据集 这个例子使用的是鸢尾花数据集(Iris dataset),这是一个常用的
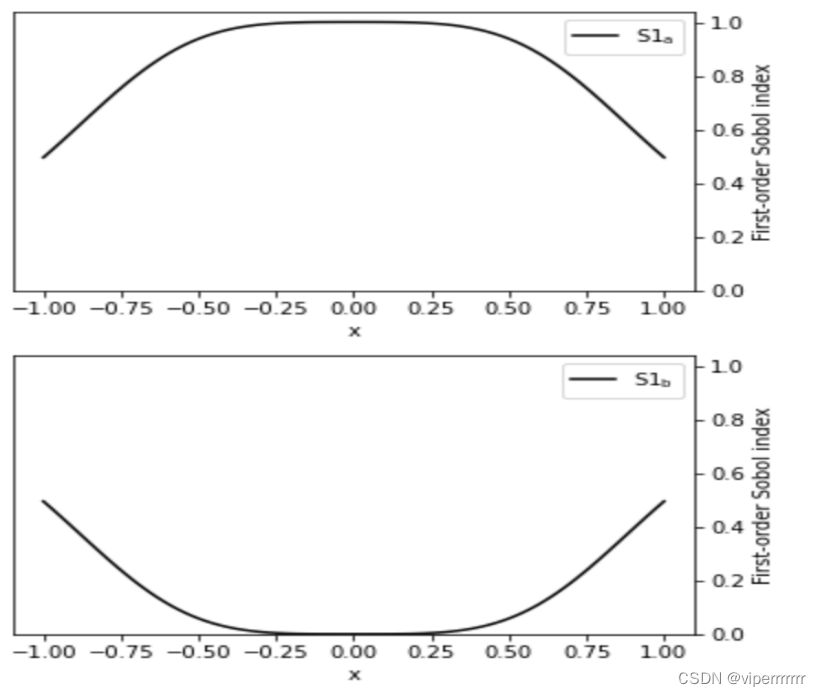
数学建模-最优包衣厚度终点判别法-三(Bayes判别分析法和梯度下降算法)
💞💞 前言 hello hello~ ,这里是viperrrrrrr~💖💖 ,欢迎大家点赞🥳🥳关注💥💥收藏🌹🌹🌹 💥个人主页:viperrrrrrr的博客 💥 欢迎学习数学建模算法、大数据、前端等知识,让我们一起向目标进发! 基于近红外光谱的肠溶片最优包衣厚度终点判别法 包衣是将片剂的外表面均匀地包裹上一层衣膜的过程,旨在控制药物在胃肠道中的释放部位

自动驾驶定位算法-递归贝叶斯滤波(Bayes Filter)
自动驾驶定位算法-递归贝叶斯滤波(Bayes Filter) 附赠自动驾驶学习资料和量产经验:链接 贝叶斯滤波器(Bayes Filter)是无人驾驶汽车中高精定位相关的基础技术,同时也是机器人技术中的基础算法。 如上图,开始机器人不知道自己在哪里,跟人在陌生的环境中一样,一脸茫然,觉得四周哪里都一样,对机器人来说就是在任何地方的置信度都相等。 置信度(Belief)是什么 要让
Scikit-learn——Naive Bayes
本文主要介绍sklearn中关于朴素贝叶斯模型的用法,其中主要包含以下两类模型: 离散型:所有维度的特征都是离散型的随机变量连续型:所有维度的特征都是连续型的随机变量 1.sklearn.naive_bayes.MultinomialNB 多项式朴素贝叶斯(Multinomial Naive Bayes),即所有特征都是离散型的随机变量(例如在做文本分类时所使用的词向量就是离散型的).在s

Mahout bayes分类器
实现包括三部分:The Trainer(训练器)、The Model(模型)、The Classifier(分类器) 1、训练 首先,要对输入数据进行预处理,转化成Bayes M/R job读入数据要求的格式,即训练器输入的数据是KeyValueTextInputFormat格式,第一个字符是类标签,剩余的是特征属性(即单词)。以20个新闻的例子来说,从官网上下载的原始数据是一
深入理解贝叶斯分类与朴素贝叶斯模型(Naive Bayes, NB):从基础到实战
目录 贝叶斯分类 公式 决策规则 优点 贝叶斯分类器的例子——垃圾邮件问题 1. 特征(输入): 2. 类别: 3. 数据: 4. 模型训练: 注:类别先验概率 5. 模型预测: 朴素贝叶斯模型 模型定位&模型假设 模型算法 例子 sklearn朴素贝叶斯代码实现 贝叶斯分类 公式 在贝叶斯分类中,我们关注的是样本属于某个类别的概率。设是输入特征向

统计学/机器学习入门(三): 朴素贝叶斯Naïve Bayes及其决策边界,交叉验证
一)理论基础 不做过多介绍,NB(Naïve Bayes) 可用来分类,直接上公式: P(H|E) = P(E|H) * P(H) / P(E) 二)举例说明 a)文本数据: 直接来个例子比较直观, 现在有这样一堆数据: 我们将通过过去的天气数据来判断 今天是否适合出去玩耍,然后今天的天气是这样: 这就是个很简单的0 1问题,play到底可不可以呢,于是我们就需要计算P(
2.朴素贝叶斯Naive Bayes
1.思想简介和实例 http://www.cnblogs.com/leoo2sk/archive/2010/09/17/naive-bayesian-classifier.html 2.适用情况和评价 朴素贝叶斯分类器(NBC)基于一个简单的假定:给定目标值时属性之间相互条件独立。 所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法
Matlab R2018b 使用Bayes Net Toolbox的经历和问题
安装包的下载与加载主要参考: https://blog.csdn.net/moodytong/article/details/8122327 问题1: 简单案例运行后,图形绘制没有箭头,出现错误提示: 未定义与 ‘matlab.graphics.axis.Axes’ 类型的输入参数相对应的运算符 ‘*’。 出错 arrow (line 393) ax = o * gca; 出错 draw_grap

朴素贝叶斯(Naive Bayes) | 算法实现
01 起 大数据时代,我们的“隐私”早已不再是隐私,一个特别直接的证据是什么呢? 我们的邮箱也好、手机也好,经常收到恼人的垃圾邮件、垃圾短信 被这些东西烦的不行,怎么办呢?网上有很多垃圾邮件过滤软件,可以拿来直接用的,其中的原理是什么呢? 今天我们自己造个轮子来过滤邮箱里的垃圾邮件吧! 系好安全带,我要开车了! 02 过滤原理 垃圾邮件过滤的原理其实很简单:朴素贝叶斯(
NBSVM (Naive Bayes - Support Vector Machine)学习
title: NBSVM 算法学习 date: 2020-06-14 18:14:29 tags: NBSVM (Naive Bayes - Support Vector Machine)学习 文章目录 NBSVM (Naive Bayes - Support Vector Machine)学习相关资料MotivationNB(Naive Bayes)本论文中的贝叶斯:数据介绍:
【NLP冲吖~】一、朴素贝叶斯(Naive Bayes)
0、朴素贝叶斯法 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入输出的联合概率分布,然后基于此模型,对给定的输入 x x x,利用贝叶斯定理求出后验概率最大的输出 y y y。 朴素贝叶斯分类是贝叶斯分类中最简单,也是常见的一种分类方法。 从数学角度,定义分类问题如下: 已知集合 C = y 1 , y 2 , . . . ,
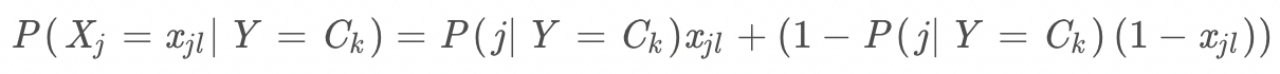
机器学习实验报告——Bayes算法
目录 一、算法介绍 1.1算法背景 1.2算法假设 1.3 贝叶斯与朴素贝叶斯 1.4算法原理 二、算法推导 2.1朴素贝叶斯介绍 2.2朴素贝叶斯算法推导 2.2.1先验后验概率 2.2.2条件概率公式 2.3 独立性假设 2.4 朴素贝叶斯推导 三、算法实现 3.1数据集描述 3.2代码实现 四、实验讨论 4.1算法优缺点 4.2关于三种朴素贝叶斯算法使用场

Bayes理论相关应用之——Bayes定理
问题导入:一个故事引出的一个小问题。 场景描述:面前有两只木桶,编号为C1,C2(之所以用C,是因为木桶的英文为Cask).两只木桶中有数目不等的黑色球和白色球,数目分别是:C1中有70个黑球,30个白球;C2中有50个黑球,50个白球。黑球用B(即Black)表示,白球用W(即White)表示。 问题描述:随机地从两只木桶中取出一个球,发现该球是白色球,问:该白色球来自C1的概率有多大

朴素贝叶斯(Naive Bayes)
朴素贝叶斯(Naive Bayes)是一组基于贝叶斯定理的分类算法,它基于特征之间的独立性假设,因此被称为“朴素”。尽管这个假设在实际情况中往往不成立,但朴素贝叶斯在实践中表现得相当好,并在文本分类和垃圾邮件过滤等领域广泛应用。 以下是朴素贝叶斯的基本原理和使用方法: 基本原理 贝叶斯定理: 根据贝叶斯定理,后验概率(posterior)等于先验概率(prior)与似然度(likelihoo
朴素贝叶斯法_naive_Bayes
朴素贝叶斯法(naive Bayes)是基于贝叶斯定理与特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入输出的联合概率分布;然后基于此模型,对给定的输入 x x x,利用贝叶斯定理求出后验概率最大的输出 y y y。 基本方法: 设输入空间 X ⊆ R n X\subseteq R^n X⊆Rn为 n n n维向量的集合,输出空间为类标记集合 Y = { c
深入理解贝叶斯分类与朴素贝叶斯模型(Naive Bayes, NB):从基础到实战
目录 贝叶斯分类 公式 决策规则 优点 贝叶斯分类器的例子——垃圾邮件问题 1. 特征(输入): 2. 类别: 3. 数据: 4. 模型训练: 注:类别先验概率 5. 模型预测: 朴素贝叶斯模型 模型定位&模型假设 模型算法 例子 sklearn朴素贝叶斯代码实现 贝叶斯分类 公式 在贝叶斯分类中,我们关注的是样本属于某个类别的概率。设是输入特征向