本文主要是介绍FFA-Net: Feature Fusion Attention Network for Single Image Dehazing (AAAI 2020)用于单图像去叠的特征融合注意力网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
用于单图像去叠的特征融合注意力网络
https://arxiv.org/pdf/1911.07559.pdf
Xu Qin1*Zhilin Wang2∗Yuanchao Bai1Xiaodong Xie1†Huizhu Jia1
1School of Electronics Engineering and Computer Science, Peking University
2School of Computer Science and Engineering, Beihang University
{qinxu,yuanchao.bai,donxie,hzjia}@pku.edu.cn, 007wangzhilin@buaa.edu.cn
摘要本文提出了一种端到端的特征融合注意网络(FFA-Net),用于直接恢复无雾图像。FFA网络体系结构由三个关键组成部分组成:1)考虑到不同的信道特征包含完全不同的加权信息,不同的图像像素上的雾度分布不均匀,提出了一种新的特征注意(FA)模块,将信道注意与像素注意机制相结合。FA不平等地处理不同的特征和像素,这为处理不同类型的信息提供了额外的灵活性,扩展了CNNs的表示能力。2)一种基本的块结构由局部剩余学习和特征注意组成,局部剩余学习允许通过多个局部剩余连接绕过薄雾区或低频等不太重要的信息,让主网络结构关注更有效的信息。3)基于注意的不同层次特征融合(FFA)结构,从特征注意(FA)模块中自适应学习特征权重,赋予重要特征更多权重。这种结构还可以保留浅层的信息,并将其传递到深层。实验结果表明,我们提出的FFANet在数量和质量上都大大超过了现有的单图像去叠方法,使SOTS室内测试数据集上公布的PSNR指标从30.23db提高到35.77db。代码已在https://github.com/zhilin007/FFA-Net提供。
单幅图像去叠作为一项基本的低层次视觉任务,在过去几十年里越来越受到计算机视觉界和人工智能公司的关注。
由于大气中存在烟雾、灰尘、烟雾、雾气和其他漂浮颗粒,在这样的大气中拍摄的图像经常受到颜色失真、模糊、低对比度和其他可见的质量退化的影响,以及朦胧的图像。图像输入将使分类、跟踪、人的再识别和目标检测等视觉任务难以解决。鉴于此,图像去叠的目的是从被破坏的图像中恢复出清晰的图像,这将是高级视觉任务的预处理步骤。大气散射模型(CARTNEY 1976)(Narasimhan和Nayar 2000)(Narasimhan和Nayar 2002)提供了雾效应的简单近似,它被表述为:
![]()
其中I(z)是观测到的朦胧图像,A是全球大气光,t(z)是介质传输图,J(z)是无霾图像。此外,我们还得到了t(z)=e-βd(z),其中β和d(z)分别是大气散射参数和景深。大气散射模型表明,在不知道A和t(z)的情况下,图像去叠是一个欠定问题。式(1)也可表述为:
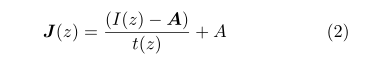
从公式1和公式2中,我们可以注意到,如果我们对捕捉到的模糊图像正确地估计全球大气和传输图,我们可以恢复一个清晰的无霾图像。基于大气散射模型,早期的去叠方法做了一系列工作(Berman、Avidan等,2016年)(Fattal,2014年)(He、Sun和Tang,2010年)(Jiang等人,2010年)。2017年)(Ju、Gu和Zhang,2017年)(Meng等人。2013年)(朱、麦、邵2015年)。DCP是一种优秀的基于先验的方法,它们基于室外无霾图像的图像块在至少一个信道中往往具有低强度值的假设,提出了暗通道先验。然而,由于先验方法在实际应用中容易被破坏,可能导致传输图的不准确率估计,因此先验方法在某些实际情况下可能不能很好地工作。随着深度学习的兴起,人们也提出了许多神经网络方法来估计雾霾效应,其中包括DehazeNet的开创性工作(Cai等。2016年),多尺度CNN(MSCNN)(Ren等人。2016),剩余学习技术(He等人。2016年),四叉树CNN(Kim,Ha,and Kwon 2018)和密集连接的金字塔去叠网络(Zhang and Patel 2018)。与传统方法相比,深度学习方法试图直接对中间传输图或最终无霾图像进行回归。随着大数据的应用,它们以健壮性获得了优异的性能。本文提出了一种新的用于单图像去叠的端到端特征融合网络(简称FFA网络)。以前基于CNN的图像去叠网络对通道和像素特征的处理是一样的,但是薄雾在图像中的分布是不均匀的,薄雾的权重应该与厚雾区域像素的权重明显不同。此外,DCP还发现,在至少一个颜色(RGB)通道中,一些像素具有非常低的强度是非常常见的,这进一步说明了不同的通道特征具有完全不同的加权信息。如果我们对它一视同仁,它将花费大量资源对不重要的信息进行不必要的计算,网络将缺乏覆盖所有像素和通道的能力。最后,它将极大地限制网络的表示。自注意机制(Xu等人。2015年)(V aswani等人。2017年)(Wang等人。2018)在神经网络的设计中得到了广泛的应用,对网络的性能起到了重要的作用。灵感来源于作品(Zhang等人。2018),我们进一步设计了一个新颖的功能关注(FA)模块。FA模块在信道和像素特征上分别结合了信道注意和像素注意。FA不平等地处理不同的特征和像素,这可以在处理不同类型的信息时提供额外的灵活性。
snet的合并(他等。2016年),这使得培训一个非常深入的网络成为可能。采用跳跃连接和注意机制的思想,设计了一个由多个局部剩余学习跳跃连接和特征注意组成的基本模块。一方面,局部残差学习可以通过多个局部残差学习绕过薄雾区域和低频信息,使主网络学习到更多有用信息。而信道关注进一步提高了FFA网络的性能。随着网络的不断深入,浅层特征信息往往难以保存。为了识别和融合不同层次的特征,U-Net(Ronneberger、Fischer和Brox,2015)和其他网络努力整合浅层和深层信息。同样,我们提出了一种基于注意力的特征融合结构(FFA),这种结构可以保留浅层信息并将其传递到深层。最重要的是,FFA网络在将所有特征输入特征融合模块之前,对不同层次的特征赋予不同的权值,权值是通过对FA模块的自适应学习获得的。它比那些直接指定重量的要好得多。为了评价不同图像去噪网络的性能,常用峰值信噪比(PSNR)和结构相似性指数(SSIM)来量化去噪图像的恢复质量。对于人的主观评价,我们还提供了大量的网络输出。我们在广泛使用的去叠基准数据集RESIDE上验证了FFA网络的有效性(Li等人。2018年)。将PSNR和SSIM度量与以前的最新方法进行了比较。实验表明,FFA网络在定性和定量上都大大优于以往的方法。此外,我们还进行了大量的烧蚀实验,证明我们的FFA网络的关键部件具有优异的性能。总的来说,我们的贡献是以下四点:
提出了一种新的用于单图像去叠的端到端特征融合注意网络FFA网。FFA网在很大程度上超越了以往最先进的图像去叠方法,尤其在雾度大、纹理细节丰富的区域表现尤为突出。如图1和图8所示,我们在恢复图像细节和颜色保真度方面也具有强大的优势。
我们提出了一种新的特征注意(FA)模块,它结合了通道注意和像素注意机制。该模块在处理不同类型的信息时提供了额外的灵活性,更加关注浓雾的像素和更重要的信道信息。
我们提出了一个由局部剩余学习和特征注意(FA)组成的基本块,局部剩余学习允许通过多跳连接绕过薄雾区域和低频信息,特征注意(FA)进一步提高了FFA网络的容量。
我们提出了一种基于注意力的特征融合(FFA)结构,这种结构可以保留浅层信息并将其传递到深层。此外,它不仅能融合所有特征,而且能自适应地学习不同层次特征信息的不同权重。最后,与其他特征融合方法相比,该方法取得了更好的性能。

现有的图像去雾方法大多依赖于物理散射模型等式1的制定,这是由于未知的传输图和全球大气光引起的高度不适定问题。这些方法大致可以分为两类:传统的基于先验的方法和现代的基于学习的方法。无论采用哪种方法,关键是解决透射图和大气光的问题。对于传统的方法,基于不同的图像统计先验,利用其作为额外的约束来补偿腐败过程中的信息损失。DCP(He,Sun,and Tang 2010)提出了一种用于估计传输图的暗信道先验。然而,当场景对象与大气光相似时,先验信息是不可靠的。(Zhu,Mai,and Shao 2015)通过创建一个线性模型来建模模糊图像的场景深度,提出了一个简单但强大的颜色衰减先验。(Fattal 2008)提出了一种估计朦胧场景中光传输的新方法,消除散射光以提高场景可见性并恢复无霾场景对比度,,(Berman、Avidan等,2016)提出了一种非局部性的方法来表征干净的图像,该算法依赖于假设一个无雾图像的颜色很好地近似由几百个不同的颜色,从而形成紧密集群在RGB空间。尽管这些方法已经取得了一系列的成功,但是先验的方法并不能很好地处理所有的情况,比如野外的无约束环境。鉴于图像处理任务中深度学习的普遍成功和大型图像数据集的可用性,(Cai等。2016)提出了一种基于卷积神经网络去杂网的端到端去杂模型,它以一幅朦胧图像为输入,输出其介质传输图,然后利用大气散射模型恢复一幅朦胧图像。(Ren等人。2016年)采用了多尺度MSCNN,能够从模糊图像执行精确的传输地图。(Y ang和Sun 2018)结合了传统的基于优先级的去叠方法和深度学习方法的优势,将与霾相关的事先学习融入到深度网络中。。(Li等人。2017年)AOD网通过一个轻量级CNN直接生成一个干净的图像。这种新颖的端到端设计使得AOD网络很容易嵌入到其他深度模型中。门控融合网络(GFN)(Ren等人。2018年)利用人工选择的预处理方法和多尺度估计,这些方法本质上是通用的,有待改进。(Chen等人。2019)提出了一种端到端的门控上下文聚合网络来直接恢复最终的无霾图像,该网络采用了最新的平滑膨胀技术,以帮助去除因广泛使用的可忽略额外参数的扩展卷积而产生的网格伪影。EPDN(Qu等人。2019年)嵌入了一个生成性对抗网络,随后是一个精心设计的增强器,而不依赖物理散射模型。
在这一部分中,我们主要介绍了我们的特征融合注意力网络FFA-Net。如图2所示,FFA网络的输入是一个模糊的图像,它被传递到一个浅层特征提取部分,然后被输入到N个具有多跳连接的群结构中,然后通过我们提出的特征注意模块将N个群结构的输出特征融合在一起,这些特征最终传递到重构部分和全局残差学习结构,从而得到无雾输出。此外,每一组结构都将B个基本块结构与局部剩余学习相结合,每一个基本块都结合了跳跃连接和特征注意(FA)模块。FA是由通道注意和像素注意组成的注意机制结构。
特征注意(FA)大多数图像去叠网络对通道和像素特征的处理是平等的,不能处理雾度分布不均匀和通道加权的图像
功能正常。我们的特性注意(参见图3)由频道注意力和像素注意力组成,这可以在处理不同类型的信息时提供额外的灵活性。FA不平等地处理不同的特征和像素区域,这可以在处理不同类型的信息时提供额外的灵活性,并且可以扩展CNNs的表示能力。关键的一步是如何为每个通道和像素特征生成不同的权重。我们的解决方案如下。

频道注意(CA)我们的频道注意主要关注不同的频道特征对于DCP具有完全不同的加权信息(He、Sun和Tang 2010)。首先,利用全局平均池将信道全局空间信息转化为信道描述符。
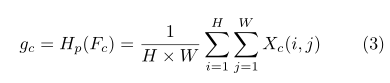
其中Xc(i,j)表示第c个通道Xcat位置(i,j)的值,Hpis是全局池函数。特征图的形状由C×H×W变为C×1×1。为了得到不同通道的权值,特征通过两个卷积层和sigmoid,ReLu激活函数后。
![]()
其中,σ是sigmoid函数,δ是ReLu函数。最后,我们将输入fc与信道CAc的权值相乘。
最后,我们将输入fc与信道CAc的权值相乘
![]()
像素注意(Pixel Attention,PA)考虑到不同图像像素上的雾度分布不均匀,我们提出了一个像素注意(Pixel Attention,PA)模块,使网络更加关注信息特征,如浓密的雾度像素和高频图像区域。

与CA类似,我们使用ReLu和sigmoid激活函数将输入F∗(CA的输出)直接输入到两个卷积层中形状由C×H×W变为1×H×W。
![]()
最后,我们对输入F*和P A使用元素乘法,![]() 是Future Attention(FA)模块的输出。
是Future Attention(FA)模块的输出。
![]()
为了直观地说明特征注意(FA)机制的有效性,我们打印了组结构输出的通道级和像素级特征权重图。我们可以清楚地看到,不同的特征映射在不同的权值下被自适应地学习。图4显示了较厚的模糊图像像素区域和具有较大权重的对象的边缘、纹理。像素注意(PA)机制使得FFA网络更加关注高频和浓密的像素区域。图5示出了一个3×64大小的图,并且三行对应于在信道方向上输出的三个组架构的特征映射权重,说明不同的特征自适应地学习完全不同的权重。
基本块结构如图6所示,基本块结构由局部剩余学习和特征注意(FA)模块组成,局部剩余学习允许通过多个局部剩余连接绕过薄雾或低频区域等不太重要的信息,而主网络则注重有效的信息。实验结果表明,其结构可以进一步提高网络性能和训练的稳定性,局部残差学习的效果可以在图7中看到,具体细节可以在烧蚀研究部分看到

组架构和全局剩余学习我们的组架构结合了B基本块结构和跳过连接模块。连续的B块增加了FFA网络的深度和表现力。跳转连接使得FFA网在训练中遇到困难。在FFA网络的最后,我们使用两层卷积网络实现和一个快捷的全局残差学习模块添加了一个恢复部分。最后,我们恢复我们想要的无雾图像。
特征融合注意如上所述,首先我们将G组结构输出的所有特征映射在信道方向连接起来。此外,我们通过乘以由特征注意(FA)机制获得的自适应学习权重来融合特征。由此,我们可以保留低层的信息并将其传递到深层,由于权重机制的存在,使得FFA网络更加关注厚雾区、高频纹理和色彩保真度等有效信息。
损失函数均方误差(MSE)或L2损失是应用最广泛的单图像去叠损失函数。然而(Lim等人。(2017)指出,在PSNR和SSIM指标方面,许多L1丢失的图像恢复任务训练取得了比L2丢失更好的性能。遵循同样的策略,我们默认采用简单的L1损失。尽管许多去叠算法也使用感知损耗和GAN损耗,但我们选择了L1损耗的优化。
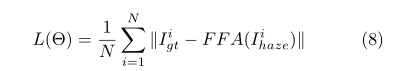
式中,Θ表示FFA网参数,igt表示真实标注,ihaze表示输入。
实施细节在本节中,我们将详细说明我们提议的FFA网络的实现细节。群结构G的个数是3。在每个组结构中,我们将基本块结构数设置为B=19。除信道关注度为1×1外,所有卷积层滤波器的大小均为3×3。除频道注意模块外,所有功能图都保持大小不变。每个组结构输出64个筛选器。

数据集和度量(Li等人。2018)提出了一个图像去叠基准住宅,其中包含来自深度数据集(NYU depth V2(Silberman et al.)的室内和室外场景中的合成模糊图像。以及立体声数据集(Middlebury立体声数据集(Scharstein和Szeliski 2003))。RESIDE的室内训练集包含1399幅洁净图像和相应洁净图像生成的13990幅朦胧图像。全球大气光照范围从0.8到1.0,散射参数从0.04到0.2。为了与已有的最新方法进行比较,我们采用PSNR和SSIM度量,在包含500幅室内图像和500幅室外图像的合成目标测试集中进行综合比较测试。我们还测试了真实感模糊图像的主观评价结果。
训练设置我们在RGB通道中训练FFA网络,并用90,180,270度随机旋转和水平翻转来扩充训练数据集。提取2个大小为240×240的模糊图像块作为FFA网络输入。整个网络训练5×105步。我们使用Adam优化器,其中β1和β2分别取默认值0.9和0.999。初始学习率设置为1×10-4,我们采用余弦退火策略(He等人。2019)根据余弦函数将学习率从初始值调整为0。假设批次总数为T,η为初始收益率,然后在批次T,学习率ηT计算为:
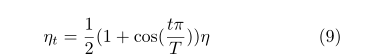
PytTorch(Paszke等人。使用RTX 2080Ti GPU实现我们的模型。)
驻留数据集上的结果
在这一部分中,我们将从定量和定性两个方面比较FFA网络和以往最先进的图像去叠算法。比较了DCP、AOD网、DehazeNet、GCANet四种最新的去叠算法,比较结果见表1。

(a)室内和室外结果

图8:SOTS和真实模糊图像测试集的定性比较
为了方便起见,引用了(Li等人。以及(Qu等人。2019年)。可以看出,我们提出的FFA网络的性能优于-艺术方法在PSNR和SSIM方面有很大的优势。此外,我们还对图8中的视觉效果进行了比较,以便进行定性比较。

从室内和室外结果来看,上面三行是室内结果,下面三行是室外结果。我们可以观察到,DCP由于其潜在的先验假设而遭受严重的颜色失真,从而丢失了图像深度的细节。AOD网络不能完全消除雾,容易输出低亮度图像。相比之下,Dehazenet恢复的图像相对于地面真实度亮度过高。GCANet在纹理、边缘、第5行蓝天等高频细节信息性能方面的处理能力一直不理想。对于真实的模糊图像结果,我们的网络可以神奇地发现第一行图像深处隐约可见的塔。更重要的是,我们的网络结果几乎完全符合真实的场景信息,比如第二排有纹理的湿路和雨滴。然而,发现在GCANE的建筑表面上存在不存在的斑点,导致行2。从其他网络恢复的图像不令人满意。我们的网络在图像细节和色彩逼真度的真实表现上明显优于其他网络。
烧蚀分析
为了进一步证明FFA网络结构的优越性,我们考虑到所提出的FFA网络的不同模块进行了消融研究。我们主要关注这些因素:1)FA(特征注意)模块。2)局部剩余学习(LRL)与FA的结合。3)特征融合注意结构。我们将图像裁剪为48×48作为输入,训练3×105步,其他配置与我们的实现细节相同。结果见表2。如果充分利用本文的实现细节,PSNR将达到35.77db。结果表明,我们考虑的每一个因素对网络性能都有重要影响,特别是FFA结构。我们也可以清楚地看到,即使我们只使用足总的结构,我们的网络也会比以前有很大的竞争力最先进的方法。LRL在提高网络性能的同时,使网络训练更加稳定。FA机制和特征融合(FFA)的结合,使我们的研究成果达到了很高的水平。

结论本文提出了一种端到端的特征融合注意网络,并证明了其在单图像去叠中的强大能力。虽然我们的FFA网络结构简单,但它比以前的最先进的方法有很大的优势。我们的网络在图像细节恢复和色彩保真度恢复方面具有强大的优势,有望解决其他低层次视觉任务,如去噪、超分辨率、去噪等。FFA网络中的FFA等有效模块在图像恢复算法中起着重要的作用。
References
[Berman, Avidan, and others 2016] Berman, D.; Avidan, S.;
et al. 2016. Non-local image dehazing. In Proceedings of
the IEEE conference on computer vision and pattern recog-
nition, 1674–1682.
[Cai et al. 2016] Cai, B.; Xu, X.; Jia, K.; Qing, C.; and Tao,
D. 2016. Dehazenet: An end-to-end system for single im-
age haze removal. IEEE Transactions on Image Processing
25(11):5187–5198.
[Cartney 1976] Cartney, E. J. 1976. Optics of the atmo-
sphere: scattering by molecules and particles. New York,
John Wiley and Sons, Inc., 1976. 421 p.
[Chen et al. 2019] Chen, D.; He, M.; Fan, Q.; Liao, J.;
Zhang, L.; Hou, D.; Y uan, L.; and Hua, G. 2019. Gated
context aggregation network for image dehazing and derain-
ing. In 2019 IEEE Winter Conference on Applications of
Computer Vision (WACV), 1375–1383. IEEE.
[Fattal 2008] Fattal, R. 2008. Single image dehazing. ACM
transactions on graphics (TOG) 27(3):72.
[Fattal 2014] Fattal, R. 2014. Dehazing using color-lines.
ACM transactions on graphics (TOG) 34(1):13.
[He et al. 2016] He, K.; Zhang, X.; Ren, S.; and Sun, J. 2016.
Deep residual learning for image recognition. In Proceed-
ings of the IEEE conference on computer vision and pattern
recognition, 770–778.
[He et al. 2019] He, T.; Zhang, Z.; Zhang, H.; Zhang, Z.; Xie,
J.; and Li, M. 2019. Bag of tricks for image classification
with convolutional neural networks. In Proceedings of the
IEEE Conference on Computer Vision and Pattern Recogni-
tion, 558–567.
[He, Sun, and Tang 2010] He, K.; Sun, J.; and Tang, X.
2010. Single image haze removal using dark channel prior.
IEEE transactions on pattern analysis and machine intelli-
gence 33(12):2341–2353.
[Jiang et al. 2017] Jiang, Y .; Sun, C.; Zhao, Y .; and Y ang,
L. 2017. Image dehazing using adaptive bi-channel priors
on superpixels. Computer Vision and Image Understanding
165:17–32.
[Ju, Gu, and Zhang 2017] Ju, M.; Gu, Z.; and Zhang, D.
2017. Single image haze removal based on the improved at-
mospheric scattering model. Neurocomputing 260:180–191.
[Kim, Ha, and Kwon 2018] Kim, G.; Ha, S.; and Kwon, J.
2018. Adaptive patch based convolutional neural network
for robust dehazing. In 2018 25th IEEE International Con-
ference on Image Processing (ICIP), 2845–2849. IEEE.
[Li et al. 2017] Li, B.; Peng, X.; Wang, Z.; Xu, J.; and Feng,
D. 2017. Aod-net: All-in-one dehazing network. In Pro-
ceedings of the IEEE International Conference on Computer
Vision, 4770–4778.
[Li et al. 2018] Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.;
Zeng, W.; and Wang, Z. 2018. Benchmarking single-image
dehazing and beyond. IEEE Transactions on Image Process-
ing 28(1):492–505.
[Lim et al. 2017] Lim, B.; Son, S.; Kim, H.; Nah, S.; and
Mu Lee, K. 2017. Enhanced deep residual networks for sin-
gle image super-resolution. In Proceedings of the IEEE con-
ference on computer vision and pattern recognition work-
shops, 136–144.
[Meng et al. 2013] Meng, G.; Wang, Y .; Duan, J.; Xiang, S.;
and Pan, C. 2013. Efficient image dehazing with boundary
constraint and contextual regularization. In Proceedings of
the IEEE international conference on computer vision, 617–
624.
[Narasimhan and Nayar 2000] Narasimhan, S. G., and Na-
yar, S. K. 2000. Chromatic framework for vision in
bad weather. In Proceedings IEEE Conference on Com-
puter Vision and Pattern Recognition. CVPR 2000 (Cat. No.
PR00662), volume 1, 598–605. IEEE.
[Narasimhan and Nayar 2002] Narasimhan, S. G., and Na-
yar, S. K. 2002. Vision and the atmosphere. International
journal of computer vision 48(3):233–254.
[Paszke et al. 2017] Paszke, A.; Gross, S.; Chintala, S.;
Chanan, G.; Y ang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.;
Antiga, L.; and Lerer, A. 2017. Automatic differentiation in
pytorch.
[Qu et al. 2019] Qu, Y .; Chen, Y .; Huang, J.; and Xie, Y .
2019. Enhanced pix2pix dehazing network. In Proceed-
ings of the IEEE Conference on Computer Vision and Pat-
tern Recognition, 8160–8168.
[Ren et al. 2016] Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao,
X.; and Y ang, M.-H. 2016. Single image dehazing via multi-
scale convolutional neural networks. In European confer-
ence on computer vision, 154–169. Springer.
[Ren et al. 2018] Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao,
X.; Liu, W.; and Y ang, M.-H. 2018. Gated fusion networkfor single image dehazing. In Proceedings of the IEEE Con-
ference on Computer Vision and Pattern Recognition, 3253–
3261.
[Ronneberger, Fischer, and Brox 2015] Ronneberger, O.;
Fischer, P .; and Brox, T. 2015. U-net: Convolutional
networks for biomedical image segmentation. In Inter-
national Conference on Medical image computing and
computer-assisted intervention, 234–241. Springer.
[Scharstein and Szeliski 2003] Scharstein, D., and Szeliski,
R. 2003. High-accuracy stereo depth maps using structured
light. In 2003 IEEE Computer Society Conference on Com-
puter Vision and Pattern Recognition, 2003. Proceedings.,
volume 1, I–I. IEEE.
[Silberman et al. 2012] Silberman, N.; Hoiem, D.; Kohli, P .;
and Fergus, R. 2012. Indoor segmentation and support infer-
ence from rgbd images. In European Conference on Com-
puter Vision, 746–760. Springer.
[V aswani et al. 2017] V aswani, A.; Shazeer, N.; Parmar, N.;
Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, Ł.; and Polo-
sukhin, I. 2017. Attention is all you need. In Advances in
neural information processing systems, 5998–6008.
[Wang et al. 2018] Wang, X.; Girshick, R.; Gupta, A.; and
He, K. 2018. Non-local neural networks. In Proceedings
of the IEEE Conference on Computer Vision and Pattern
Recognition, 7794–7803.
[Xu et al. 2015] Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville,
A.; Salakhudinov, R.; Zemel, R.; and Bengio, Y . 2015.
Show, attend and tell: Neural image caption generation with
visual attention. In International conference on machine
learning, 2048–2057.
[Y ang and Sun 2018] Y ang, D., and Sun, J. 2018. Proximal
dehaze-net: a prior learning-based deep network for single
image dehazing. InProceedings of the European Conference
on Computer Vision (ECCV), 702–717.
[Zhang and Patel 2018] Zhang, H., and Patel, V . M. 2018.
Densely connected pyramid dehazing network. In Proceed-
ings of the IEEE conference on computer vision and pattern
recognition, 3194–3203.
[Zhang et al. 2018] Zhang, Y .; Li, K.; Li, K.; Wang, L.;
Zhong, B.; and Fu, Y . 2018. Image super-resolution us-
ing very deep residual channel attention networks. In Pro-
ceedings of the European Conference on Computer Vision
(ECCV), 286–301.
[Zhu, Mai, and Shao 2015] Zhu, Q.; Mai, J.; and Shao, L.
2015. A fast single image haze removal algorithm using
color attenuation prior. IEEE transactions on image pro-
cessing 24(11):3522–3533.
这篇关于FFA-Net: Feature Fusion Attention Network for Single Image Dehazing (AAAI 2020)用于单图像去叠的特征融合注意力网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



