本文主要是介绍自识别标记(self-identifying marker) -(4) 用于相机标定的CALTag源码剖析(下),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
接上篇内容,继续对CALTag源码进行详细剖析~
3、 角点检测
为了方便说明,在此将一个自识别标记,也就是上一步骤保留的连通区域,称为一个quad。下面分析一下如何检测quad的四个角点。
首先找到该quad的外接最小矩形bbox, 二值化掩模mask,然后对mask边界加了3个像素的pad,目的是方便后面做形态学闭运算,运算完再去掉pad。然后找出边界轮廓上的点,计算他们的梯度方向,将这些梯度方向聚成4类,从而获得4个主要的边缘方向。然后分别对每一类的边界点进行线性拟合,得到4条拟合的直线。然后计算它们的交点就是角点。
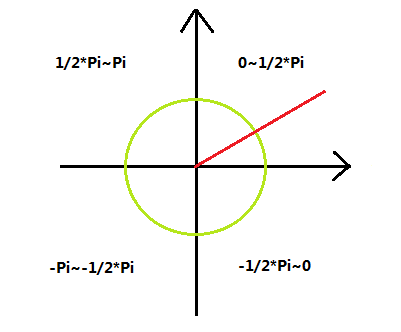
然后有一个很重要的步骤,就是把这些角点按照逆时针进行排序,这对后面恢复角点、求对应关系至关重要。排序的方法是先求出四个角点的平均坐标,就是该quad的重心。然后分别求每个角点和该重心的向量,将这些向量转化为极坐标系,将极坐标系下的角度按照升序排列就是逆时针角点的顺序。极坐标下的角度如下:
上述步骤对应的代码是:
[isq,cnr,cnr0] = fitquad( R(i).BoundingBox, R(i).FilledImage, layout );这样每个quad就会计算出四个伪角点(下图中四个红色十字),这样每个真实的角点周围就会有四个伪角点,那么如何根据这四个伪角点来计算真实角点坐标呢?

首先是根据距离聚类,然后取聚类中心的点作为初始角点saddles_0(下图中绿色圆圈),然后使用和opencv中一样的方法来寻找亚像素级精度的鞍点(下图中绿色十字)。也就是下面几句代码
[saddles] = cornerfinder_saddle_point( flipud(saddles_0), I, 11,11 );
[saddles,good] = cornerfinder_saddle_point( saddles, I, 9,9 );
saddles = flipud( saddles(:,good) ); 结果见下图

4、 Code/ID提取和验证
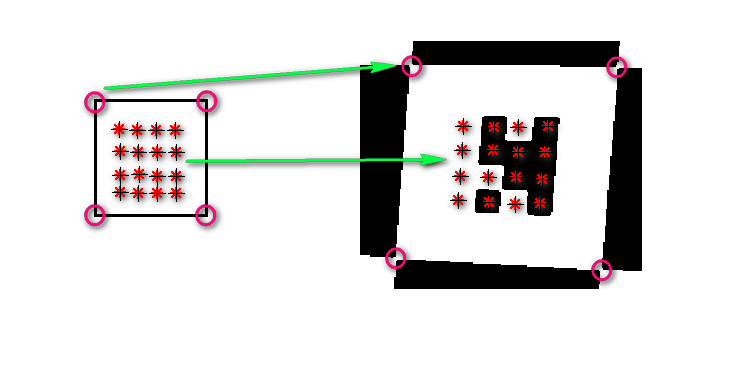
要提取标记中的code,首先需要从图片中采样出code的二进制码。流程如下图。首先定义一个理想的单位方形(即代码中的unitSquare),对应下图中左侧的黑色方形。右侧图是图片中真实的quad。首先把unitSquare的四个角点映射到quad的四个角点(下图品红色圆圈),由此得到一个单应矩阵H。然后对unitSquare内部均匀采样(下图左内部的米字形表示采样点),利用上面得到的矩阵H进行映射就得到了右边quad中的真实采样点。对应代码为:
unitSquare = [ 0 1 1 0; 0 0 1 1; 1 1 1 1 ];
R(i).H = homography2d( unitSquare, quadSquare );
R(i).HS = homoTrans( R(i).H, S );其中quadSquare就是下图右quad对应的四个角点。R(i).H为映射矩阵H,S是下图左unitSquare内部均匀采样点,R(i).HS是计算得到的右边quad中的真实采样点。
这右图中采样点按顺序排成一列就是该quad的code值。
接下来就是对code的验证了,由于实际拍摄时棋盘旋转方向未知,所以我们不知道哪个点对应标记的左上角正方向,所以需要对提取的code进行旋转4次,每个方向的code都检测一遍,如果最终四个方向里只有一个方向的code能在code矩阵表里查到就表明code有效。当检测到code有效后,需要对code内包含的ID进行验证。这16bit的code里面包含了10bit的数据,首先需要做CRC验证,验证通过才能说明真正识别了这个标记。然后按照上面找到的正确的方向把角点也转到正确的方向。
可能有人会问了,识别了code为啥还要再识别ID,不嫌麻烦啊?
原因是这样的:首先双重保障鲁棒性肯定很好,不会产生false negative(标定结果对false negative很敏感,要保证为0)。另外,CRC校验一方面是验证ID是否有效,另一方面还可以尝试对错误的采样进行修正,这在有遮挡的情况下还是有可能发生的。
上述过程对应的代码如下:
isvalid=@(x)crc_validate(b2d(x),idBits,crcBits)&&ismember(b2d(x),CODE);
validity = [ isvalid(c), isvalid(rot90(c,-1)), isvalid(rot90(c,-2)), isvalid(rot90(c,-3)) ];
R(i).isValid = (nnz(validity) == 1);
shift = find( validity ) - 1;
R(i).code = rot90( R(i).code, -shift );
data = b2d( R(i).code );
R(i).id = rightshift( bitand(data,idmask), crcBits );
R(i).crc = bitand( data, 2^crcBits-1 );
R(i).saddles = circshift( R(i).saddles,[0,-shift-1] );
还有一个小插曲就是对全部检测成功的标记再进行一次过滤。方法就是计算每个标记的方向,如果某个标记的方向和其他标记的方向差别较大,就过滤掉。那么问题来了,如何计算标记的方向呢?这就是上面为什么要把角点转到正确的方向的原因之一。用连接第一、二个角点的矢量方向表示该标记的方向就OK了。
下图中每个quad中绿色的十字表示经过验证有效的code的采样点;每个quad边缘上的红线表示连接第一、二个角点的矢量方向,用来标记该quad的正方向。

5、 恢复丢失的角点
由于我们事先知道棋盘中每个标记的ID、位置排列等信息(我们称之为标记信息表),所以在上述检测角点验证ID结束之后,我们查找标记信息表就能发现哪些标记没有检测到,从而尝试去找到这些丢失的/未检测到的标记和他们的角点。
那么在此有个问题,为什么上面的步骤检测不到呢?是什么原因导致这些角点被忽视了?
请看下图的一个例子,图中深红色圆圈内的角点是经过上述步骤(验证CODE,识别ID)检测到的角点。品红色圆圈内的角点就是利用标记信息表恢复出来的角点。从图中就可以很明显的看出为什么品红色角点没被检测到,这是因为他们所在的quad(标记)因为遮挡无法被检测,并且他们周围正确被识别的quad也没有把他们包含进去。

下面具体分析一下算法是如何恢复出这些丢失的角点的?
目前对于检测成功的标记,我们知道他们的CODE, ID,在标记信息表中的位置(第几行第几列),比如实验用的自识别标记图案的标记信息表如下:
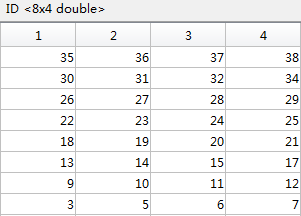
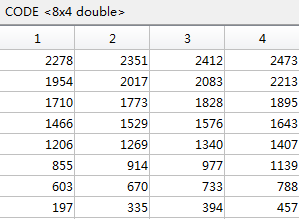
那么缺失的标记在标记信息表中的位置wPtMissing就可以知道了。我们列出所有检测到的角点的图像坐标iPt、标记信息表坐标wPt,然后用RANSAC的方法求从wPt映射到iPt的单应矩阵H。那么用该矩阵H乘以wPtMissing就得到了丢失标记的图像坐标iPtMissing。
以上过程主要对应如下代码:
H = ransacfithomography( wPt', iPtUndist', 0.1 );
trialPoints = homoTrans( H, [mrow;mcol;ones(1,length(mrow))] );其中iPtUndist就是对应所有检测到的角点的图像坐标iPt,只是经过了去畸变。
[mrow;mcol;ones(1,length(mrow))]就是缺失的标记在标记信息表中的位置wPtMissing。
trialPoints就是丢失标记的图像坐标iPtMissing。
这里我们用的是普通的摄像头,拍摄的图片畸变都非常小,略过了对于畸变较大镜头的去畸变过程。如果使用鱼眼广角镜头,畸变的影响会较大,此时就需要先对畸变的角度就行去畸变再做上述变换。
到这里还没完,你以为恢复出来的较大就是真的角点了?图样图森破!如上图中品红色的*也是恢复出的“角点”,但是其实他们是伪角点,不具备角点的性质,因为棋盘被遮挡了,他们的位置如果不被遮挡的话下面可能是真正的角点。所以下面就要对这些恢复出来的角点进行验证,必须经过如下两个验证通过,才能加入真正角点的队伍:
验证1:角点圆周上颜色反转次数。想法非常直观,好理解,就是如果以一个真正的角点为中心,一定的半径R画圆,取圆周上连续的点排成一列,应该是黑、白、黑、白间隔的顺序,反应到二进制就是0101或者1010间隔排列,也就是01翻转刚好4次。具体做起来,需要先对角点所在的窗口做个高斯平滑,避免有些噪点混入影响翻转次数。另外就是如何选择这个半径还是比较难的,见下图,图中点1,2,3,4半径选的比较合适。点5,6选的不合适。但是他们的半径都不一样。半径过小和过大都容易引入干扰:点5,6就选的过大,半径穿过了code;点7半径选的过小,如果二值化处理不好很容易引入噪声;这些角点会通不过角点翻转验证。一幅图中的角点半径都有如此大差异,何况要求算法要在不同环境不同角度下都非常稳定,半径的选取就要谨慎了。一种是固定半径值,找出图中所有角点半径不穿过code所需的最大半径,然后选择其中最小的那个作为固定的半径值。另一种思路是自适应的半径,对不同角点选择不同的半径,这个听起来很棒实现比较难。反转次数验证对应的代码如下:
valid(i) = validate_point( I, iPt(i,1), iPt(i,2), rad );验证2:beta分布验证。想法也容易理解,就是角点所在的邻域内的像素灰度应该服从一定的分布,这里用beta分布来描述,参数
0<alpha≈beta<1计算出已经确认角点的beta分布参数,取参数的中值,如果恢复角点的beta分布参数和参数的中值差在一定阈值T范围内,认为符合成为角点的条件,否则认为不是角点。同样的,这种方法也需要阈值T,下图中我们看到点2中黑白面积比例基本相等,但点3中黑色像素比例明显高于白色,而点4中反过来了,白色像素比例明显高于黑色,这一反一正参数就差开了不少。所以这个阈值的选取要靠经验判断。Beta分布验证对应的代码如下:
beta(i,:) = betafit( double(zi(:)) );
beta = abs( beta(:,1) - beta(:,2) );
beta_median = median( beta );
beta_std = std( beta );
outliers = (beta > 0.05) & (abs( beta - beta_median ) > (3 * beta_std));

最后的结果如下图。集中解释一下不同颜色标记的含义:
红色圆圈表示通过CODE, ID识别后的标记的角点位置。
绿色*表示通过CODE, ID识别后的标记的采样点位置。
品红色*表示恢复出的伪角点位置,这些角点没有通过角点验证,通过的话会在角点出画圈。
每个标记边缘上的红线表示连接第一、二个角点的矢量方向,用来标记该标记的正方向。

参考资料
参考论文:
CALTag: High Precision Fiducial Markers for Camera Calibration
参考网站:
http://www.cs.ubc.ca/labs/imager/tr/2010/Atcheson_VMV2010_CALTag/
https://github.com/brada/caltag
这篇关于自识别标记(self-identifying marker) -(4) 用于相机标定的CALTag源码剖析(下)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







