本文主要是介绍【LSS】Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【LSS】Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
1 摘要
现有的自动驾驶车辆的主要目标是从多个传感器抽取语义信息,并将这些语义信息融合成一个 BEV 坐标系下的特征图,然后进行运动规划。本文作者提出了一个方法,该方法将任意多的相机数据转化成BEV下的特征;lift:首先将 Image 信息映射到截头体中,splat:然后将多个截头体进行栅格化,训练结果表明,该模型不仅能够实现对图片信息很好的表达,还能实现对多个图片很好的融合在一个单一的表达,而且对标定误差具有鲁棒性,shoot:当将目标运动的轨迹映射到我们的 BEV 视角下,能够发现我们的模型推断的表示能够实现可解释的运动规划。

2 介绍
在自动驾驶中将多个传感器作为输入,每个传感器都有自己的坐标系,最终需要统一到自车坐标系下进行运动规划:
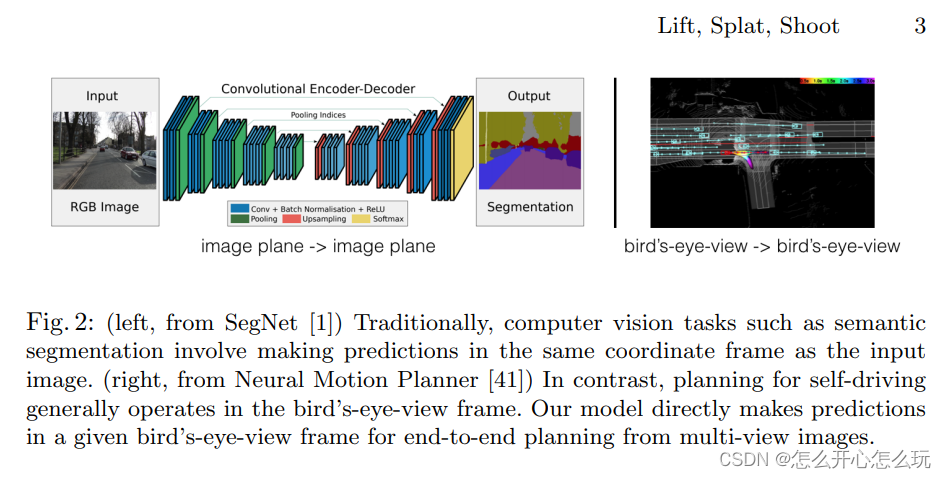
对于多个相机生成的 Images,可以通过单个 Image 进行检测,然后再进行转换和平移大自车坐标系下,实现多自车的全景检测,并且单个 Image 检测具有平移不变性,转置不变性,自车自车框架下的等距,这三个有价值的性质,但是需要对数据进行后处理实现,而且这种后处理是不能够通过数据驱动的方式实现的。
作者提出了“lift-splat”方法保证了上述的三个对称性有点,但是能够实现端到端训练的模型。“lift” 是通过生成一个截面体,实现将 Images 映射到 3D 空间上;“splat” 是将所有的截面体映射到同一个平面上,方便下游实现运动规划;“shooting” 是将预测轨迹映射到参照平面,可以得到可解释的运动规划。
3 Method
作者提出了在 BEV 视角下对多个 images 数据进行融合,并且保存了上述的三个有点。作者使用相机的内参矩阵和外参矩阵实现对参照坐标(x, y, z)到像素坐标(h, w, d)的映射。
3.1 Lift: Latent Depth Distribution
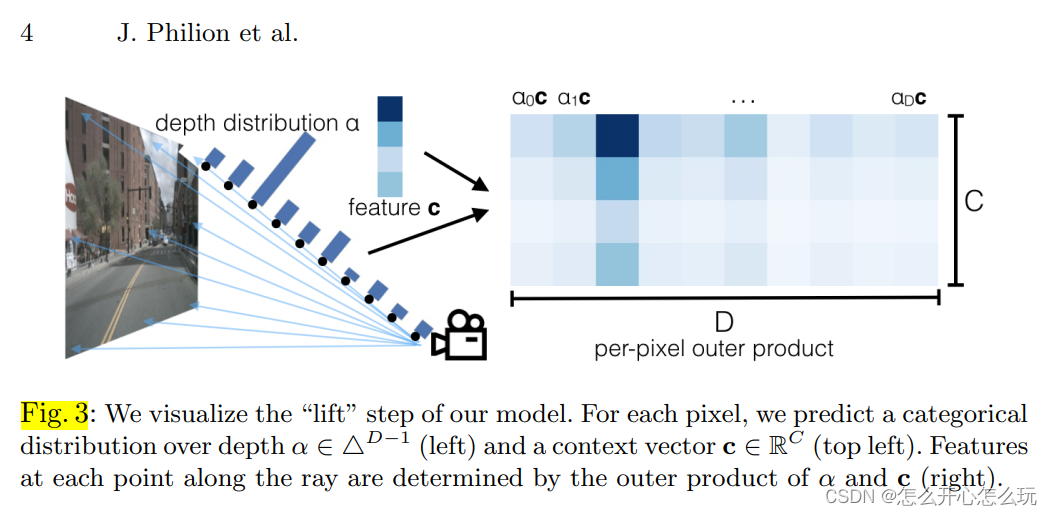
作者首根据 image 生成一个截面体,并将截面体在depth方向上离散化成 |D| 个点,
对于每一个voxel(h, w)在 image 上都能找到与之对应的特征 c ( c 是已经提取过的上下文特征),由于每个voxel(h, w)都有 |D| 个点与之对应,因此生成一个 |D| - 1 维向量 α,用于表示同一个voxel (h, w)中位置 d 的特征向量:

3.2 Splat: Pillar Pooling
首先使用内参和外参将 “lift” 得到的 3D 点转化成 BEV平面,然后再利用 pointpilliar 将转化后的 points 利用 sum pooling 转化成bev 下的 featuremap ,实现对离散的矩阵使用离散卷积。
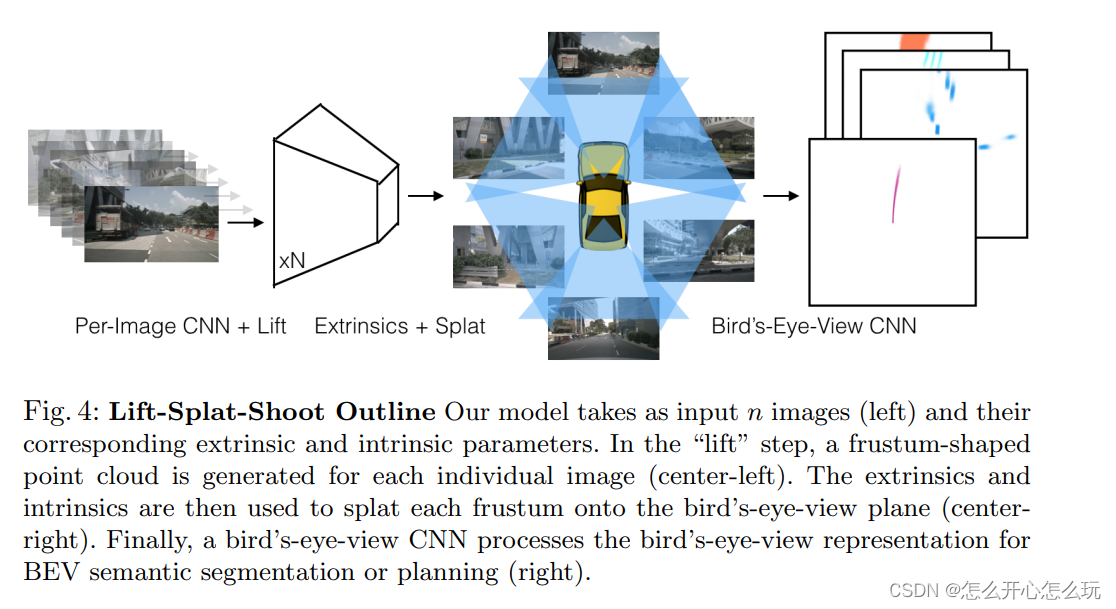
4 实施
4.2 棱台池化累积和技巧
该技巧是基于本文方法用图像产生的点云形状是固定的,因此每个点可以预先分配一个区间(即BEV网格)索引,用于指示其属于哪一个区间。按照索引排序后,按下列方法操作:
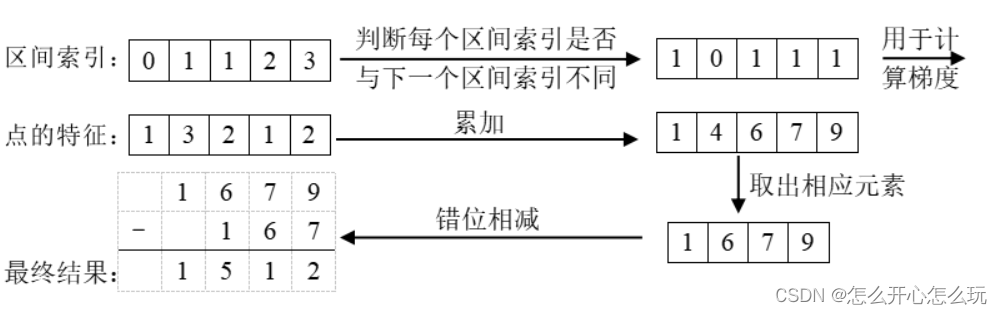
可以通过计算该算法的解析梯度,而非使用自动梯度计算以加快训练。该方法被称为“棱台池化”。
5 实验与结果

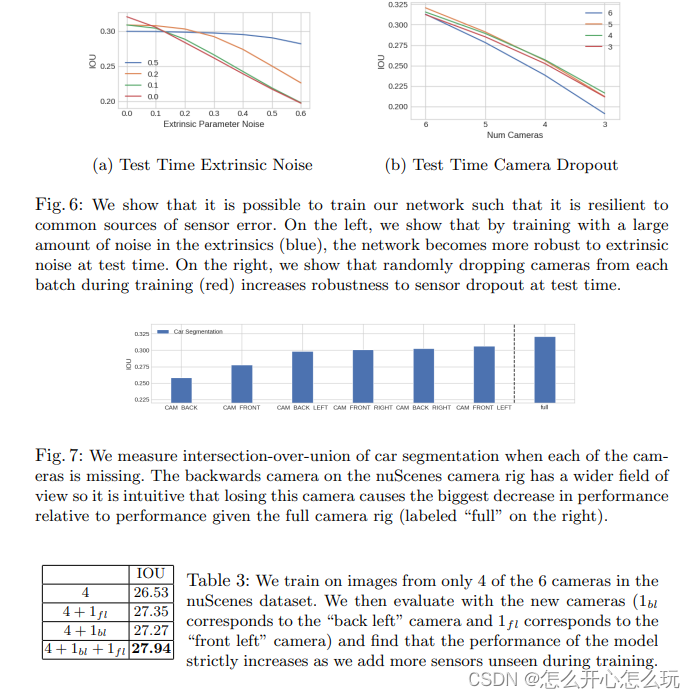

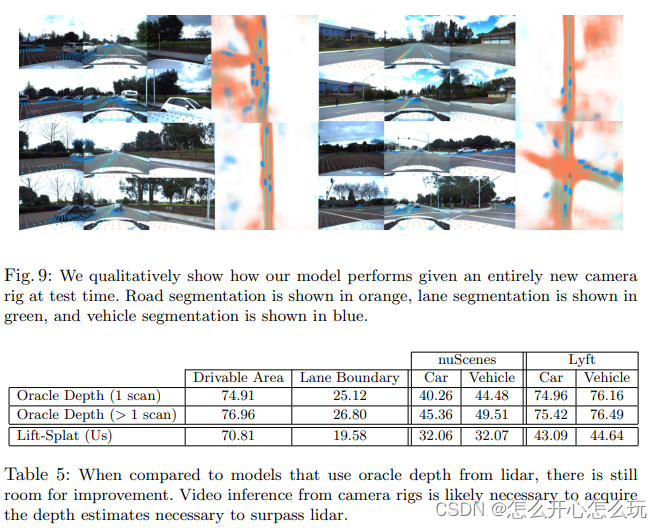

这篇关于【LSS】Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









