images专题
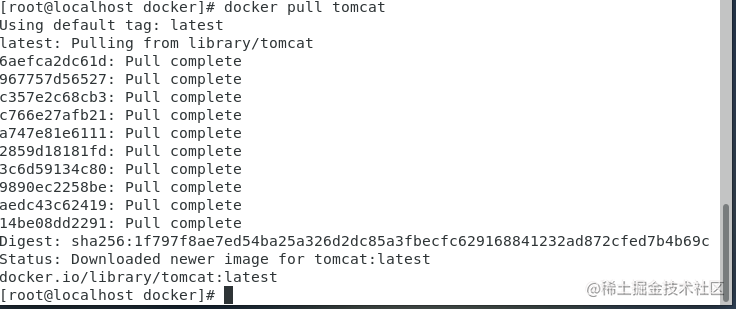
docker images
docker 装好docker之后,先掌握一下docker启动与停止 docker启动关闭状态 systemctl 命令是系统服务管理器指令,它是 service 和 chkconfig 两个命令组合。 查看 docker 的启动状态 systemctl status docker 关闭 docker systemctl stop docker 启动 docker syste

k8s执行crictl images报错
FATA[0000] validate service connection: CRI v1 image API is not implemented for endpoint "unix:///run/containerd/containerd.sock": rpc error: code = Unimplemented desc = unknown service runtime.v1.Ima

mkimage command not found - U-Boot images will not be
ubuntu14.04编译内核报错: "mkimage" command not found - U-Boot images will not be built make[1]: *** [arch/arm/boot/uImage] Error 1 make: *** [uImage] Error 2 按照错误提示安装uboot-mkimage # apt-get install uboo

SAM 2: The next generation of Meta Segment Anything Model for videos and images
https://ai.meta.com/blog/segment-anything-2/ https://github.com/facebookresearch/segment-anything-2 https://zhuanlan.zhihu.com/p/712068482

OpenCV-Python 教程——从Images开始
目标 这里,你将会学到如何读取、显示、保存一张图片你将会学习这些函数:cv2.imread(), cv2.imshow(), cv2.imwrite()当然,你将会学习如何用Matplotlib显示这些图片 使用OpenCV 读取图片 利用函数cv2.imread()来读取一张图片。该图片应该在工作目录中或是提供图片的绝对路径。 第二个参数用来明确读取图片的方式。 cv2.IMREAD

DynamiCrafter:Animating open-domain images with video diffusion priors
1.Method 图像条件视频生成, 1.1 Image Dynamics from Video Diffusion Priors 1.1.1 文本对齐的上下文表征 文本嵌入通过clip构建,图像通过clip编码,主要代表语义层面的视觉内容,未能捕获图像的完整信息,为了提取更完整的信息,使用来自clip图像vit最后一层的全视觉标记,该token在条件图像生成时表现出了高保真度,为

简单使用富有创造力的DALL·E 3 图像生成器——OpenAI Images Generations API
OpenAI Images Generations API 申请及使用 DALL-E 3 是 OpenAI 开发的两个版本的图像生成模型,它们能够根据文本描述生成高质量的图像。 本文档主要介绍 OpenAI Images Generations API 操作的使用流程,利用它我们可以轻松使用官方 OpenAI DALL-E 的图像生成功能。 申请流程 要使用 OpenAI Images G
[Banner] The number of titles and images is different
[Banner] --> The number of titles and images is different 应该设置setBannerStyle(BannerConfig.CIRCLE_INDICATOR) 之前设置的BannerConfig.CIRCLE_INDICATOR_TITLE,所以要校验title和image的数量

实时语义分割--ICNet for Real-Time Semantic Segmentation on High-Resolution Images
github代码:https://github.com/hszhao/ICNet 语义分割算法精度和速度对比: 由图可以看出,ResNet38,PSPNet,DUC精度虽然较高,但是无法速度相对较慢,无法达到实时,ENet速度较快,但精度较低,而本文算法既可以达到实时,精度也相对较高. Speed Analysis PSPNet50的处理不同大小的输入图像所需时间: 图中,sta
Segment anything in medical images
原文:Segment anything in medical images 作者:Jun Ma, YutingHe, FeifeiLi, Lin Han, Chenyu You, Bo Wang 作者单位:The University of Toronto,University Health Network 期刊/会议:2024th nature communications 引用格式:M
imx6 android6.0几个快速编译images指令
Android比较重要的image: 0.make update-api //修改framework公共api后,更新api 1.make bootimage – boot.img 2.make systemimage – system.img (这个system.img 是 从 out/target/product/xxxx/system 制作打包的) 3.make us

CVPR2017《Detecting Oriented Text in Natural Images by Linking Segments》阅读笔记
前言 本文是对CVPR2017《Detecting Oriented Text in Natural Images by Linking Segments》论文的简要介绍和细节分析。该论文是华中科大白翔组的工作,主要针对自然场景下文本检测模型由char-level到word-level和line-level的检测。 关键词:SSD、Segment、Link、Scene Text Detectio
【文字识别】UnrealText: Synthesizing Realistic Scene Text Images from the Unreal World论文阅读
类别: 文本合成 来源: CVPR2020,旷视 code: https://jyouhou.github.io/UnrealText/ 摘要: 合成数据是训练场景文本检测和识别模型的关键工具。一方面,在场景文本识别器的训练中,合成词图像已被证明是真实图像的成功替代品。然而,另一方面,场景文本检测器仍然严重依赖于大量手工注释的真实世界图像,这是非常昂贵的。在本文中,我们介绍了一种有效的图像合成方法

3D 论文阅读SDF-SRN: Learning Signed Distance 3D Object Reconstruction from Static Images
浏览SDF-SRN: Learning Signed Distance 3D Object Reconstruction from Static Images 在解决什么问题?面临的困难本文的方法Signed distance functionsRendering Implicit 3D Surfaces(I donot care) 在解决什么问题? 如何从单幅图像(仅仅利用轮
Synthetic Data for Text Localisation in Natural Images(人工合成带有文本的图片)
https://github.com/JarveeLee/SynthText_Chinese_version 1.解决python3的pickle.load错误:a bytes-like object is required, not 'str' 经过几番查找,发现是Python3和Python2的字符串兼容问题,因为数据文件是在Python2下序列化的,所以使用Python3读取时,需要将‘

Deep Neural Networks are Easily Fooled:High Confidence Predictions for Unrecognizable Images
在卷积神经网络如日中天的现在,重要会议上的论文自然成了广大学者研究的对象。苦苦寻觅,然而并不能搜到“大家们”对论文的见解。痛定思痛,决定对自己看过的论文写点小感。只是个人看法,如有瑕疵,欢迎指正。一是为了督促自己看论文要仔细认真,二是希望有人指正自己的错误。 Abstract 深度神经网络(DNNs)在各种模式识别任务中取得了一定的成就,其中最显著的是视觉分类问题。鉴于,
Android之提示MIME type application/octet-stream cannot be inserted into **/images expected
1、问题 在三星手机(Androd10.0)我需要把图片插入系统图库,错误提示如下 AndroidRuntime: java.lang.RuntimeException: Unable to start activity ComponentInfo{com.appsinnova.android.keepdrop/com.appsinnova.android.keepdrop.account.A

【深度学习实战—7】:基于Pytorch的多标签图像分类-Fashion-Product-Images
✨博客主页:王乐予🎈 ✨年轻人要:Living for the moment(活在当下)!💪 🏆推荐专栏:【图像处理】【千锤百炼Python】【深度学习】【排序算法】 目录 😺一、数据集介绍😺二、工程文件夹目录😺三、option.py😺四、split_data.py😺五、dataset.py😺六、model.py😺七、utils.py😺八、train.py😺九

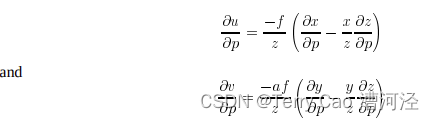
Fitting Parameterized Three-Dimensional Models to Images
摘要 基于模型的识别和运动跟踪依赖于解决投影和模型参数,使其最佳适应匹配的2D图像特征的3D模型的能力。本文将当前的参数求解方法扩展到处理具有任意曲面和任意数量的内部参数(表示关节、可变尺寸或表面变形)的对象。开发了数值稳定化方法,考虑了图像测量中固有的不准确性,并允许在匹配数小于未知参数数时确定有用的解决方案。使用Levenberg-Marquardt方法始终确保解决方案的收敛性。这些技术
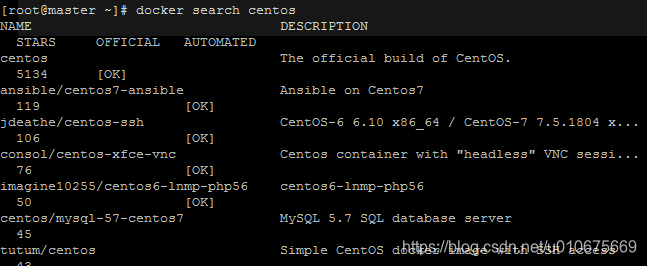
Openwrt:编译固件提示[mktplinkfw] error: images are too big 错误
在编译mr3420的固件时,添加了luci、jamvm,但是最终编译的固件“openwrt-ar71xx-generic-tl-mr3420-v1-squashfs-factory.bin”的大小仅仅只有3.1MB,为何会如此小巧,心生疑惑下把该固件烧录到路由中,发现luci和java虚拟机都没有添加上去,然后才发现是固件生成失败了。提示如下: /bin/ar71xx/openwrt-ar71
![[深度学习论文笔记]Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images](https://img-blog.csdnimg.cn/20190103195855504.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3UwMTAxNTg2NTk=,size_16,color_FFFFFF,t_70)
[深度学习论文笔记]Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images
[ACM MM 15] Temporal Localization of Fine-Grained Actions in Videos by Domain Transfer from Web Images Chen Sun, Sanketh Shettyy, Rahul Sukthankary and Ram Nevatia from USC & Google paper link Moti

Open Images数据集解析----下载Open Images V4指定的类别数据
1.下载Open Images的注释文件 注释文件如下: Class Names: class-descriptions-boxable.csv 数据集内部使用的类名到人类可理解名称的对应 Boxes: train-annotations-bbox.csv 训练图像中对象实例的边框注释
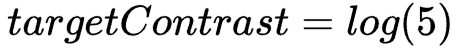
Fast Bilateral Filteringfor the Display of High-Dynamic-Range Images
1 Title Fast Bilateral Filtering for the Display of High-Dynamic-Range Images(Fr´edo Durand and Julie Dorsey)【SIGGRAPH '02】 2 Conclusion This paper presents a new technique for the
