本文主要是介绍【深度学习实战—7】:基于Pytorch的多标签图像分类-Fashion-Product-Images,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
✨博客主页:王乐予🎈
✨年轻人要:Living for the moment(活在当下)!💪
🏆推荐专栏:【图像处理】【千锤百炼Python】【深度学习】【排序算法】
目录
- 😺一、数据集介绍
- 😺二、工程文件夹目录
- 😺三、option.py
- 😺四、split_data.py
- 😺五、dataset.py
- 😺六、model.py
- 😺七、utils.py
- 😺八、train.py
- 😺九、predict.py
在图像分类领域,可能会遇到需要确定对象的多个属性的场景。例如,这些可以是类别、颜色、大小等。与通常的图像分类相比,此任务的输出将包含 2 个或更多属性。
在本教程中,我们将重点讨论一个问题,即我们事先知道属性的数量。此类任务称为多输出分类。事实上,这是多标签分类的一种特例,还可以预测多个属性,但它们的数量可能因样本而异。
本文程序已解耦,可当做通用型多标签图像分类框架使用。
数据集下载地址:Fashion-Product-Images
😺一、数据集介绍
我们将使用时尚产品图片数据集。它包含超过 44 000 张衣服和配饰图片,每张图片有 9 个标签。
从 kaggle 上下载到数据集后解压可以一个文件夹和一个csv表格,分别是images和styles.csv。
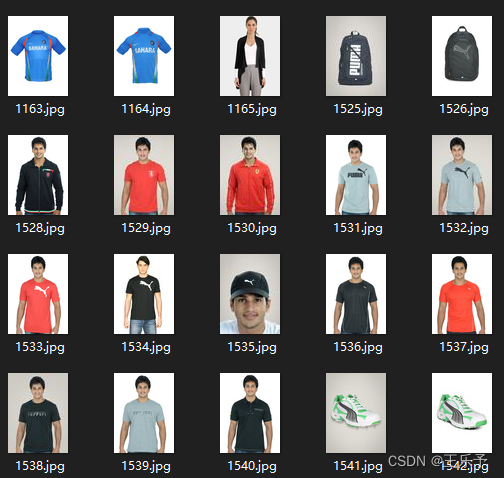
其中images里存放了数据集中所有的图片。
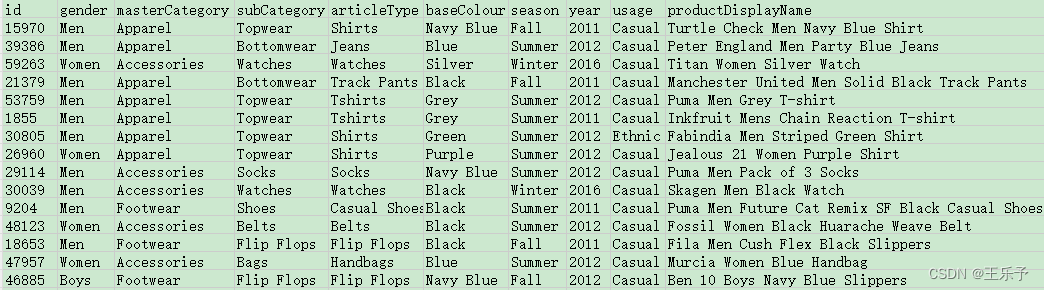
styles.csv中写入了图片的相关信息,包括 id(图片名称)、gender(性别)、masterCategory(主要类别)、subCategory(二级类别)、articleType(服装类型)、baseColour(描述性颜色)、season(季节)、year(年份)、usage(使用说明)、productDisplayName(品牌名称)。
😺二、工程文件夹目录
工程文件夹目录如下,每个py文件具有不同的功能,这么写的好处是未来修改程序更加方便,而且每个py程序都没有很长。如果全部写到一个py程序里,则会显得很臃肿,修改起来也不轻松。

对每个文件的解释如下:
- checkpoints:存放训练的模型权重;
- datasets:存放数据集。并对数据集划分;
- logs:存放训练日志。包括训练、验证时候的损失与精度情况;
- option.py:存放整个工程下需要用到的所有参数;
- utils.py:存放各种函数。包括模型保存、模型加载和损失函数等;
- split_data.py:划分数据集;
- model.py:构建神经网络模型;
- train.py:训练模型;
- predict.py:评估训练模型。
😺三、option.py
import argparsedef get_args():parser = argparse.ArgumentParser(description='ALL ARGS')parser.add_argument('--device', type=str, default='cuda', help='cuda or cpu')parser.add_argument('--start_epoch', type=int, default=0, help='start epoch')parser.add_argument('--epochs', type=int, default=100, help='Total Training Times')parser.add_argument('--batch_size', type=int, default=32, help='input batch size')parser.add_argument('--num_workers', type=int, default=0, help='number of processes to handle dataset loading')parser.add_argument('--lr', type=float, default=0.001, help='initial learning rate for adam')parser.add_argument('--datasets_path', type=str, default='./datasets/', help='Path to the dataset')parser.add_argument('--image_path', type=str, default='./datasets/images', help='Path to the style image')parser.add_argument('--original_csv_path', type=str, default='./datasets/styles.csv', help='Original csv file dir')parser.add_argument('--train_csv_path', type=str, default='./datasets/train.csv', help='train csv file dir')parser.add_argument('--val_csv_path', type=str, default='./datasets/val.csv', help='val csv file dir')parser.add_argument('--log_dir', type=str, default='./logs/', help='log dir')parser.add_argument('--checkpoint_dir', type=str, default='./checkpoints/', help='checkpoints dir')parser.add_argument('--checkpoint', type=str, default='./checkpoints/2024-05-24_13-50/checkpoint-000002.pth', help='choose a checkpoint to predict')parser.add_argument('--predict_image_path', type=str, default='./datasets/images/1163.jpg', help='show ground truth')return parser.parse_args()
😺四、split_data.py
由于数据集的各个属性严重不均衡,为简单起见,在本教程中仅使用三个标签:gender、articleType 和 baseColour
import csv
import os
import numpy as np
from PIL import Image
from tqdm import tqdm
from option import get_argsdef save_csv(data, path, fieldnames=['image_path', 'gender', 'articleType', 'baseColour']):with open(path, 'w', newline='') as csv_file:writer = csv.DictWriter(csv_file, fieldnames=fieldnames)writer.writeheader()for row in data:writer.writerow(dict(zip(fieldnames, row)))if __name__ == '__main__':args = get_args()input_folder = args.datasets_pathoutput_folder = args.datasets_pathannotation = args.original_csv_pathall_data = []with open(annotation) as csv_file:reader = csv.DictReader(csv_file)for row in tqdm(reader, total=reader.line_num):img_id = row['id']# only three attributes are used: gender articleType、baseColourgender = row['gender']articleType = row['articleType']baseColour = row['baseColour']img_name = os.path.join(input_folder, 'images', str(img_id) + '.jpg')# Determine if the image existsif os.path.exists(img_name):# Check if the image is 80 * 60 size and if it is in RGB formatimg = Image.open(img_name)if img.size == (60, 80) and img.mode == "RGB":all_data.append([img_name, gender, articleType, baseColour])np.random.seed(42)all_data = np.asarray(all_data)# Randomly select 40000 data pointsinds = np.random.choice(40000, 40000, replace=False)# Divide training and validation setssave_csv(all_data[inds][:32000], args.train_csv_path)save_csv(all_data[inds][32000:40000], args.val_csv_path)
😺五、dataset.py
该代码实现了两个类,AttributesDataset用于处理属性标签,FashionDataset类继承自Dataset类,用于处理带有图片路径和属性标签的数据集。关键地方的解释在代码中已经进行了注释。
get_mean_and_std函数用于获取数据集图像的均值与标准差
import csv
import numpy as np
from PIL import Image
import os
from torch.utils.data import Dataset
from torchvision import transforms
from option import get_argsargs = get_args()mean = [0.85418772, 0.83673165, 0.83065592]
std = [0.25331535, 0.26539705, 0.26877365]class AttributesDataset():def __init__(self, annotation_path):color_labels = []gender_labels = []article_labels = []with open(annotation_path) as f:reader = csv.DictReader(f)for row in reader:color_labels.append(row['baseColour'])gender_labels.append(row['gender'])article_labels.append(row['articleType'])# Remove duplicate values to obtain a unique label setself.color_labels = np.unique(color_labels)self.gender_labels = np.unique(gender_labels)self.article_labels = np.unique(article_labels)# Calculate the number of categories for each labelself.num_colors = len(self.color_labels)self.num_genders = len(self.gender_labels)self.num_articles = len(self.article_labels)# Create label mapping: Create two dictionaries: one from label ID to label name, and the other from label name to label ID.# Mapping results:self.gender_name_to_id:{'Boys': 0, 'Girls': 1, 'Men': 2, 'Unisex': 3, 'Women': 4}# Mapping results.gender_id_to_name:{0: 'Boys', 1: 'Girls', 2: 'Men', 3: 'Unisex', 4: 'Women'}self.color_id_to_name = dict(zip(range(len(self.color_labels)), self.color_labels))self.color_name_to_id = dict(zip(self.color_labels, range(len(self.color_labels))))self.gender_id_to_name = dict(zip(range(len(self.gender_labels)), self.gender_labels))self.gender_name_to_id = dict(zip(self.gender_labels, range(len(self.gender_labels))))self.article_id_to_name = dict(zip(range(len(self.article_labels)), self.article_labels))self.article_name_to_id = dict(zip(self.article_labels, range(len(self.article_labels))))class FashionDataset(Dataset):def __init__(self, annotation_path, attributes, transform=None):super().__init__()self.transform = transformself.attr = attributes# Initialize a list to store the image path and corresponding labels of the datasetself.data = []self.color_labels = []self.gender_labels = []self.article_labels = []# Read data from a CSV file and store the image path and corresponding labels in a listwith open(annotation_path) as f:reader = csv.DictReader(f)for row in reader:self.data.append(row['image_path'])self.color_labels.append(self.attr.color_name_to_id[row['baseColour']])self.gender_labels.append(self.attr.gender_name_to_id[row['gender']])self.article_labels.append(self.attr.article_name_to_id[row['articleType']])def __len__(self):return len(self.data)def __getitem__(self, idx):img_path = self.data[idx]img = Image.open(img_path)if self.transform:img = self.transform(img)dict_data = {'img': img,'labels': {'color_labels': self.color_labels[idx],'gender_labels': self.gender_labels[idx],'article_labels': self.article_labels[idx]}}return dict_datatrain_transform = transforms.Compose([transforms.RandomHorizontalFlip(p=0.5),transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.3, hue=0),transforms.ToTensor(),transforms.Normalize(mean, std)])val_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean, std)])# Calculate the mean and variance of all images in the dataset
def get_mean_and_std(image_paths, transform): # Initialize the accumulator of mean and variancemeans = np.zeros((3,)) stds = np.zeros((3,)) count = 0 for image_path in image_paths: image = Image.open(image_path).convert('RGB') image_tensor = transform(image).unsqueeze(0) image_array = image_tensor.numpy() # Calculate the mean and variance of the imagebatch_mean = np.mean(image_array, axis=(0, 2, 3)) batch_var = np.var(image_array, axis=(0, 2, 3)) # Accumulate to the totalmeans += batch_mean stds += batch_var count += 1 # Calculate the mean and standard deviation of the entire datasetmeans /= count stds = np.sqrt(stds / count) return means, stds # Calculate the mean and variance of the dataset
if __name__ == '__main__':mena_std_transform = transforms.Compose([transforms.ToTensor()])image_path = []for root, _, files in os.walk(args.image_path):for file in files:if os.path.splitext(file)[1].lower() in ('.jpg', '.jpeg', '.png', '.bmp', '.tiff', '.gif'):image_path.append(os.path.join(root, file))means, stds = get_mean_and_std(image_path, mena_std_transform)print("Calculated mean and standard deviation:=========>") print("Mean:", means) print("Std:", stds)
😺六、model.py
该代码用来创建网络模型,需要注意的是最后使用了三个分类头对三个属性进行分类。
import torch
import torch.nn as nn
import torchvision.models as modelsclass MultiOutputModel(nn.Module):def __init__(self, n_color_classes, n_gender_classes, n_article_classes):super().__init__()self.base_model = models.mobilenet_v2().featureslast_channel = models.mobilenet_v2().last_channelself.pool = nn.AdaptiveAvgPool2d((1, 1))# Create three independent classifiers for predicting three categoriesself.color = nn.Sequential(nn.Dropout(p=0.2), nn.Linear(in_features=last_channel, out_features=n_color_classes))self.gender = nn.Sequential(nn.Dropout(p=0.2), nn.Linear(in_features=last_channel, out_features=n_gender_classes))self.article = nn.Sequential(nn.Dropout(p=0.2), nn.Linear(in_features=last_channel, out_features=n_article_classes))def forward(self, x):x = self.base_model(x)x = self.pool(x)x = torch.flatten(x, 1)return {'color': self.color(x),'gender': self.gender(x),'article': self.article(x)}
😺七、utils.py
对utils.py中各函数的解释:
get_cur_time:获取当前时间。checkpoint_save:保存模型。checkpoint_load:加载模型。get_loss:定义损失函数。calculate_metrics:计算精度。
import os
from datetime import datetime
import warnings
from sklearn.metrics import balanced_accuracy_score
import torch
import torch.nn.functional as F# Get the current date and time and format it as a string
def get_cur_time():return datetime.strftime(datetime.now(), '%Y-%m-%d_%H-%M')def checkpoint_save(model, name, epoch):f = os.path.join(name, 'checkpoint-{:06d}.pth'.format(epoch))torch.save(model, f)print('Saved checkpoint:', f)# Load Checkpoints
def checkpoint_load(model, name):print('Restoring checkpoint: {}'.format(name))model = torch.load(name, map_location='cpu')epoch = int(os.path.splitext(os.path.basename(name))[0].split('-')[1])return model, epochdef get_loss(net_output, ground_truth):color_loss = F.cross_entropy(net_output['color'], ground_truth['color_labels'])gender_loss = F.cross_entropy(net_output['gender'], ground_truth['gender_labels'])article_loss = F.cross_entropy(net_output['article'], ground_truth['article_labels'])loss = color_loss + gender_loss + article_lossreturn loss, {'color': color_loss, 'gender': gender_loss, 'article': article_loss}def calculate_metrics(output, target):_, predicted_color = output['color'].cpu().max(1)gt_color = target['color_labels'].cpu()_, predicted_gender = output['gender'].cpu().max(1)gt_gender = target['gender_labels'].cpu()_, predicted_article = output['article'].cpu().max(1)gt_article = target['article_labels'].cpu()with warnings.catch_warnings(): # sklearn may produce a warning when processing zero row in confusion matrixwarnings.simplefilter("ignore")accuracy_color = balanced_accuracy_score(y_true=gt_color.numpy(), y_pred=predicted_color.numpy())accuracy_gender = balanced_accuracy_score(y_true=gt_gender.numpy(), y_pred=predicted_gender.numpy())accuracy_article = balanced_accuracy_score(y_true=gt_article.numpy(), y_pred=predicted_article.numpy())return accuracy_color, accuracy_gender, accuracy_article
😺八、train.py
该程序用于模型训练。
程序记录了训练日志,可以启动tensorboard观察训练过程(需要改成自己的路径):
tensorboard --logdir=logs/2024-05-24_15-16
程序还添加了学习率衰减的训练策略。
程序使用tqdm库用于在终端可视化训练时间。
# Start Tensorboard:tensorboard --logdir=logs/2024-05-24_15-16
import os
from tqdm import tqdm
import torch
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from dataset import AttributesDataset, FashionDataset, train_transform, val_transform
from model import MultiOutputModel
from utils import get_loss, get_cur_time, checkpoint_save
from predict import calculate_metrics, validate
from option import get_argsargs = get_args()# Initial parameters
start_epoch = args.start_epoch
N_epochs = args.epochs
batch_size = args.batch_size
num_workers = args.num_workers
batch_size = args.batch_size
device = args.device# Initial paths
original_csv_path = args.original_csv_path
train_csv_path = args.train_csv_path
val_csv_path = args.val_csv_path
log_dir = args.log_dir
checkpoint_dir = args.checkpoint_dir# Load attribute classes, The attributes contain labels and mappings for three categories
attributes = AttributesDataset(original_csv_path)# Load Dataset
train_dataset = FashionDataset(train_csv_path, attributes, train_transform)
val_dataset = FashionDataset(val_csv_path, attributes, val_transform)train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers)
val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers)# Load model
model = MultiOutputModel(n_color_classes=attributes.num_colors,n_gender_classes=attributes.num_genders,n_article_classes=attributes.num_articles)
model.to(device)optimizer = torch.optim.Adam(model.parameters(), lr=args.lr)
sch = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.9) # Add learning rate decaylogdir = os.path.join(log_dir, get_cur_time())
savedir = os.path.join(checkpoint_dir, get_cur_time())os.makedirs(logdir, exist_ok=True)
os.makedirs(savedir, exist_ok=True)logger = SummaryWriter(logdir)n_train_samples = len(train_dataloader)if __name__ == '__main__':for epoch in range(start_epoch, N_epochs):# Initialize training loss and accuracy for each categorytotal_loss, color_loss, gender_loss, article_loss = 0, 0, 0, 0accuracy_color, accuracy_gender, accuracy_article = 0, 0, 0# Create a tqdm instance to visualize training progresspbar = tqdm(total=len(train_dataset), desc='Training', unit='img')for batch in train_dataloader:pbar.update(train_dataloader.batch_size) # Update progress baroptimizer.zero_grad()img = batch['img']target_labels = batch['labels']target_labels = {t: target_labels[t].to(device) for t in target_labels}output = model(img.to(device))# Calculate lossesloss_train, losses_train = get_loss(output, target_labels)total_loss += loss_train.item()color_loss += losses_train['color']gender_loss += losses_train['gender']article_loss += losses_train['article']# Calculation accuracybatch_accuracy_color, batch_accuracy_gender, batch_accuracy_article = calculate_metrics(output, target_labels)accuracy_color += batch_accuracy_coloraccuracy_gender += batch_accuracy_genderaccuracy_article += batch_accuracy_articleloss_train.backward()sch.step()# Print epoch, total loss, loss for each category, accuracy for each categoryprint("epoch {:2d}, total_loss: {:.4f}, color_loss: {:.4f}, gender_loss: {:.4f}, article_loss: {:.4f}, color_acc: {:.4f}, gender_acc: {:.4f}, article_acc: {:.4f}".format(epoch,total_loss / n_train_samples, color_loss / n_train_samples, gender_loss / n_train_samples, article_loss / n_train_samples,accuracy_color / n_train_samples, accuracy_gender / n_train_samples, accuracy_article / n_train_samples))# Loss and accuracy write to logslogger.add_scalar('train_total_loss', total_loss / n_train_samples, epoch) logger.add_scalar('train_color_loss', color_loss / n_train_samples, epoch) logger.add_scalar('train_gender_loss', gender_loss / n_train_samples, epoch) logger.add_scalar('train_article_loss', article_loss / n_train_samples, epoch) logger.add_scalar('train_color_acc', accuracy_color / n_train_samples, epoch) logger.add_scalar('train_gender_acc', accuracy_gender / n_train_samples, epoch) logger.add_scalar('train_article_acc', accuracy_article / n_train_samples, epoch) if epoch % 2 == 0:validate(model=model, dataloader=val_dataloader, logger=logger, iteration=epoch, device=device, checkpoint=None)if epoch % 2 == 0:checkpoint_save(model, savedir, epoch)pbar.close()
😺九、predict.py
该程序中定义了两个函数:
validate用于在训练过程中启动验证。visualize_grid用于对测试集进行评估。
在visualize_grid中,添加了三种属性测试结果的混淆矩阵,以及可视化预测结果。
在main函数中,需要对测试集进行评估就注释掉Single image testing。反之,如果需要对单张图片测试,需要注释掉Dir testing。
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import torch
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from dataset import FashionDataset, AttributesDataset, mean, std
from model import MultiOutputModel
from utils import get_loss, calculate_metrics, checkpoint_load
from option import get_argsargs = get_args()
batch_size = args.batch_size
num_workers = args.num_workers
device = args.device
original_csv_path = args.original_csv_path
val_csv_path = args.val_csv_path
checkpoint=args.checkpoint
predict_image_path = args.predict_image_pathdef validate(model, dataloader, logger, iteration, device, checkpoint):if checkpoint is not None:checkpoint_load(model, checkpoint)model.eval()with torch.no_grad():# The total loss and accuracy of each category in initializing the validation setavg_loss, accuracy_color, accuracy_gender, accuracy_article = 0, 0, 0, 0for batch in dataloader:img = batch['img']target_labels = batch['labels']target_labels = {t: target_labels[t].to(device) for t in target_labels}output = model(img.to(device))val_train, val_train_losses = get_loss(output, target_labels)avg_loss += val_train.item()batch_accuracy_color, batch_accuracy_gender, batch_accuracy_article = calculate_metrics(output, target_labels)accuracy_color += batch_accuracy_coloraccuracy_gender += batch_accuracy_genderaccuracy_article += batch_accuracy_articlen_samples = len(dataloader)avg_loss /= n_samplesaccuracy_color /= n_samplesaccuracy_gender /= n_samplesaccuracy_article /= n_samplesprint('-' * 80)print("Validation ====> loss: {:.4f}, color_acc: {:.4f}, gender_acc: {:.4f}, article_acc: {:.4f}\n".format(avg_loss, accuracy_color, accuracy_gender, accuracy_article))logger.add_scalar('val_loss', avg_loss, iteration)logger.add_scalar('val_color_acc', accuracy_color, iteration)logger.add_scalar('val_color_acc', accuracy_gender, iteration)logger.add_scalar('val_color_acc', accuracy_article, iteration)model.train()def visualize_grid(model, dataloader, attributes, device, show_cn_matrices=True, show_images=True, checkpoint=None,show_gt=False):if checkpoint is not None:model, _ = checkpoint_load(model, checkpoint)model.eval()# Define image listimgs = [] # Define a list of predicted results (predicted labels, predicted color labels, predicted gender labels, predicted article labels)labels, predicted_color_all, predicted_gender_all, predicted_article_all = [], [], [], []# Define a list of real values (real labels, real color labels, real gender labels, real article labels)gt_labels, gt_color_all, gt_gender_all, gt_article_all = [], [], [], []# Initialize precision for each categoryaccuracy_color = 0accuracy_gender = 0accuracy_article = 0with torch.no_grad():for batch in dataloader:img = batch['img']gt_colors = batch['labels']['color_labels']gt_genders = batch['labels']['gender_labels']gt_articles = batch['labels']['article_labels']output = model(img)batch_accuracy_color, batch_accuracy_gender, batch_accuracy_article = \calculate_metrics(output, batch['labels'])accuracy_color += batch_accuracy_coloraccuracy_gender += batch_accuracy_genderaccuracy_article += batch_accuracy_article# Calculate maximum probability prediction label_, predicted_colors = output['color'].cpu().max(1)_, predicted_genders = output['gender'].cpu().max(1)_, predicted_articles = output['article'].cpu().max(1)for i in range(img.shape[0]):image = np.clip(img[i].permute(1, 2, 0).numpy() * std + mean, 0, 1)predicted_color = attributes.color_id_to_name[predicted_colors[i].item()]predicted_gender = attributes.gender_id_to_name[predicted_genders[i].item()]predicted_article = attributes.article_id_to_name[predicted_articles[i].item()]gt_color = attributes.color_id_to_name[gt_colors[i].item()]gt_gender = attributes.gender_id_to_name[gt_genders[i].item()]gt_article = attributes.article_id_to_name[gt_articles[i].item()]gt_color_all.append(gt_color)gt_gender_all.append(gt_gender)gt_article_all.append(gt_article)predicted_color_all.append(predicted_color)predicted_gender_all.append(predicted_gender)predicted_article_all.append(predicted_article)imgs.append(image)labels.append("{}\n{}\n{}".format(predicted_gender, predicted_article, predicted_color))gt_labels.append("{}\n{}\n{}".format(gt_gender, gt_article, gt_color))if not show_gt:n_samples = len(dataloader)print("Accuracy ====> color: {:.4f}, gender: {:.4f}, article: {:.4f}".format(accuracy_color / n_samples,accuracy_gender / n_samples,accuracy_article / n_samples))# Draw confusion matrixif show_cn_matrices:# Color confusion matrixcn_matrix = confusion_matrix(y_true=gt_color_all,y_pred=predicted_color_all,labels=attributes.color_labels,normalize='true')ConfusionMatrixDisplay(confusion_matrix=cn_matrix, display_labels=attributes.color_labels).plot(include_values=False, xticks_rotation='vertical')plt.title("Colors")plt.tight_layout()plt.savefig("confusion_matrix_color.png")# plt.show()# Gender confusion matrixcn_matrix = confusion_matrix(y_true=gt_gender_all,y_pred=predicted_gender_all,labels=attributes.gender_labels,normalize='true')ConfusionMatrixDisplay(confusion_matrix=cn_matrix, display_labels=attributes.gender_labels).plot(xticks_rotation='horizontal')plt.title("Genders")plt.tight_layout()plt.savefig("confusion_matrix_gender.png")# plt.show()# Article confusion matrix (with too many categories, images may be too large to display fully)cn_matrix = confusion_matrix(y_true=gt_article_all,y_pred=predicted_article_all,labels=attributes.article_labels,normalize='true')plt.rcParams.update({'font.size': 1.8})plt.rcParams.update({'figure.dpi': 300})ConfusionMatrixDisplay(confusion_matrix=cn_matrix, display_labels=attributes.article_labels).plot(include_values=False, xticks_rotation='vertical')plt.rcParams.update({'figure.dpi': 100})plt.rcParams.update({'font.size': 5})plt.title("Article types")plt.savefig("confusion_matrix_article.png")# plt.show()if show_images:labels = gt_labels if show_gt else labelstitle = "Ground truth labels" if show_gt else "Predicted labels"n_cols = 5n_rows = 3fig, axs = plt.subplots(n_rows, n_cols, figsize=(10, 10))axs = axs.flatten()for img, ax, label in zip(imgs, axs, labels):ax.set_xlabel(label, rotation=0)ax.get_xaxis().set_ticks([])ax.get_yaxis().set_ticks([])ax.imshow(img)plt.suptitle(title)plt.tight_layout()plt.savefig("images.png")# plt.show()model.train()if __name__ == '__main__':"""Dir testing"""attributes = AttributesDataset(original_csv_path)val_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean, std)])test_dataset = FashionDataset(val_csv_path, attributes, val_transform)test_dataloader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers)model = MultiOutputModel(n_color_classes=attributes.num_colors, n_gender_classes=attributes.num_genders,n_article_classes=attributes.num_articles).to('cpu')visualize_grid(model, test_dataloader, attributes, device, checkpoint)"""Single image testing"""model = torch.load(checkpoint, map_location='cpu')img = Image.open(predict_image_path) if img.mode != 'RGB': img = img.convert('RGB') img_tensor = val_transform(img).unsqueeze(0)with torch.no_grad():outputs = model(img_tensor)_, predicted_color = outputs['color'].cpu().max(1)_, predicted_gender = outputs['gender'].cpu().max(1)_, predicted_article = outputs['article'].cpu().max(1)print("Predicted color ====> {}, gender: {}, article: {}".format(attributes.color_id_to_name[predicted_color.item()],attributes.gender_id_to_name[predicted_gender.item()],attributes.article_id_to_name[predicted_article.item()]))
这篇关于【深度学习实战—7】:基于Pytorch的多标签图像分类-Fashion-Product-Images的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






