encoding专题
![[LeetCode] 820. Short Encoding of Words](/front/images/it_default.jpg)
[LeetCode] 820. Short Encoding of Words
题:https://leetcode.com/problems/short-encoding-of-words/ 题目大意 参考题目 思路 set 集合 将所有word 放入set中,然后遍历所有set中的word,将word的从头的子串都从set中删除,最后统计 set中所有(word 的长度 + 1)(’#’) class Solution {public int minimumL

whose UTF8 encoding is longer than the max length 32766
问题描述:java.lang.IllegalArgumentException: Document contains at least one immense term in field=“cf_jg.keyword” (whose UTF8 encoding is longer than the max length 32766) 原因:设置为keyword类型的字段,插入很长的大段内容后,报
自然语言处理(NLP)-子词模型(Subword Models):BPE(Byte Pair Encoding)、WordPiece、ULM(Unigram Language Model)
在NLP任务中,神经网络模型的训练和预测都需要借助词表来对句子进行表示。传统构造词表的方法,是先对各个句子进行分词,然后再统计并选出频数最高的前N个词组成词表。通常训练集中包含了大量的词汇,以英语为例,总的单词数量在17万到100万左右。出于计算效率的考虑,通常N的选取无法包含训练集中的所有词。因而,这种方法构造的词表存在着如下的问题: 实际应用中,模型预测的词汇是开放的,对于未在词表中出现的词

【位置编码】【Positional Encoding】直观理解位置编码!把位置编码想象成秒针!
【位置编码】【Positional Encoding】直观理解位置编码!把位置编码想象成秒针! 你们有没有好奇过为啥位置编码非得长成这样: P E ( p o s , 2 i ) = s i n ( p o s 1000 0 2 i / d m o d e l ) P E ( p o s , 2 i + 1 ) = c o s ( p o s 1000 0 2 i / d m o d e l

PHP Curl Content-Encoding: gzip乱码问题解决
笔者在使用php curl对接hugegraph的过程中,发现向gremlin发送结果返回乱码,截图如下: 对比这个请求和普通的请求: 发现返回乱码的乱码请求中有Content-Encoding: gzip,即返回的内容采用了gzip压缩,所以需要在curl请求中加入 curl_setopt($curl, CURLOPT_ENCODING, 'gzip'); 即返回正常。

什么是大模型的位置编码Position Encoding?
1. 什么是位置编码 位置编码(Positional Encoding)是一种在处理序列数据时,用于向模型提供序列中每个元素位置信息的技术。 在自然语言处理(NLP)中,尤其是在使用Transformer模型时,位置编码尤为重要,因为Transformer模型本身并不包含处理序列顺序的机制。 位置编码的主要目的是让模型能够区分输入序列中词的顺序,从而更好地理解句子的结构和含义。 2.
error:0D0C50A1:asn1 encoding routines:ASN1_item_verify:unknown message digest algorithm
备注:本笔记所描述的问题的前提是机器上已安装成功git且通过配置ca证书支持以https方式获取远程仓库,如果使用git时碰到这篇文章描述的问题,那么按那篇文章给出的办法解决即可。 最近从github clone repo时,git clone命令报错如下(以vim代码补全插件youcompleteme为例): ? 1 2 3 $ git clone https:

requests请求时,遇到的Accept-Encoding问题
在使用requests请求链接的时候,发现请求得到的内容总是一堆乱码: 此时请求的headers里的Accept-Encoding是这样写的: headers = {'Accept-Encoding': 'gzip, deflate','User-Agent': str('Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:81.0) Geck

gbase8s之Encoding or code set not supported
如图发生以下错误: 解决办法:在url里加上ifx_use_strenc=true 就可以了 参数解释:
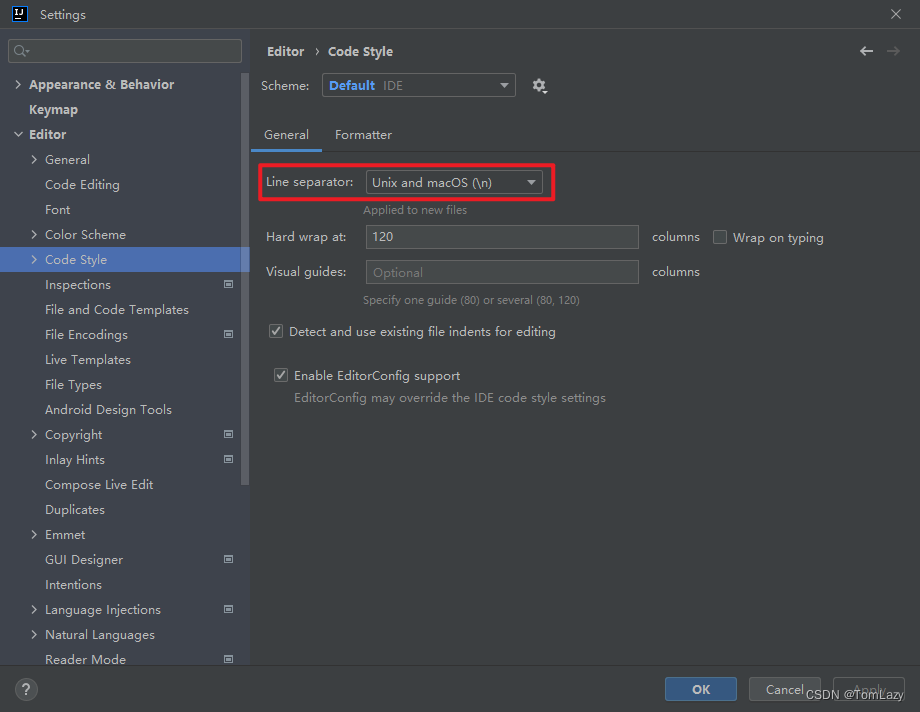
【Java开发规范】IDEA 设置 text file encoding 为 UTF-8,且文件的换行符使用 Unix 格式
1. IDEA 设置 text file encoding 为 UTF-8 file -> settings -> editor -> code style -> file encoding Transparent-native-to-asci conversion 要不要勾选?==> 不推荐勾选(它的作用是用来自动转换ASCII编码,防止文件乱码;如果勾选了,项目文件放在 linu
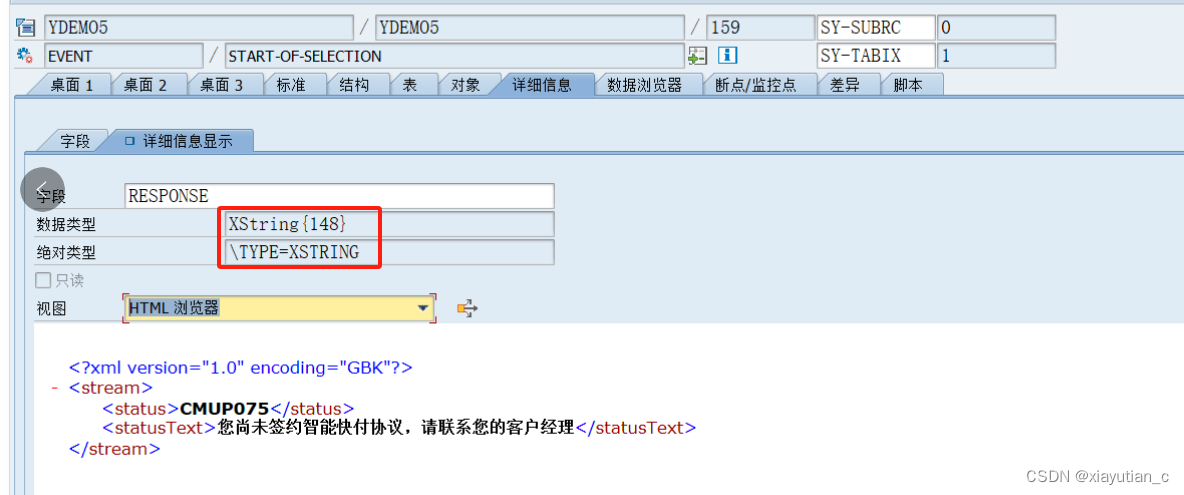
XML Encoding = ‘GBK‘ after STRANS,中文乱码
最近帮同事处理了一个中信银行银企直连接口的一个问题,同事反馈,使用STRANS转换XML后,encoding始终是’utf-16’,就算指定了GBK也不行。尝试了很多办法始终不行,发到银行的数据中,中文始终是乱码。 Debug使用HTML视图看报文时也可以看到中文是乱码。 解决方案: 使用cl_sxml_string_writer=>create创建一个GBK编码的对象 ,用来做为ST

在机器学习领域中,One-Hot Encoding是什么
一般来说,机器学习模型要求所有的输入输出变量都必须是数字。如果我们的数据中包含了分类数据,我们必须将它们编码成一些数字,这样我们才可以拿去训练和评测一个机器学习模型。 我们常说的分类数据是不能够直接拿来训练、预测的。因为它们一般都不是数值数据(数字),分类数据一般都是一些名称、标签,比如说颜色的分类数据有”红“、”绿“、”黄“、“紫”等等,再比如汽车品牌分类数据有“比亚迪”、“奇瑞”、“长城”、
LeetCode 820. 单词的压缩编码 Short Encoding of Words
Table of Contents 一、中文版 二、英文版 三、My answer 四、解题报告 一、中文版 给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A。 例如,如果这个列表是 ["time", "me", "bell"],我们就可以将其表示为 S = "time#bell#" 和 indexes = [0, 2, 5]。 对于每一个索引

encoding/pem
pem包实现了PEM数据编码(源自保密增强邮件协议)。目前PEM编码主要用于TLS密钥和证书 PEM 编码格式如下 -----BEGIN Type----- Headers base64-encoded Bytes -----END Type----- 编码 func Encode(out io.Writer, b *Block) error type Block struct {Type

encoding/json
json 包实现了json对象的编解码 获取v变量的json编码将json编码的数据存入到解析v变量中如何实现延时解析实现标准HTML转义实现json字符串格式缩进和前缀剔除编码后数据中的空白字符结构体json编码选项应用 获取v变量的json编码 func Marshal(v interface{}) ([]byte, error) package mainimport ("encoding/

encoding/gob
import "encoding/gob" gob包管理gob流——在编码器(发送器)和解码器(接受器)之间交换的binary值。一般用于传递远端程序调用(RPC)的参数和结果,如net/rpc包就有提供。 本实现给每一个数据类型都编译生成一个编解码程序,当单个编码器用于传递数据流时,会分期偿还编译的消耗,是效率最高的。 基本特点 1.gob流是自解码的 2.流中的所有数据都有前缀(采用一个预定

encoding/hex
hex 实现了16进制字符表示编解码 func Encode(dst,src []byte)intfunc EncodeToString(src []byte)stringfunc Decode(dst,src []byte)(int,error)func DecodeString(src []byte)(string,error)func DecodedLen(x int) intfunc E
encoding/ascii85
ascii85包实现了ascii85数据编码(5个ascii字符表示4个字节),该编码用于btoa工具和Adobe的PostScript语言和PDF文档格式。 编码 func Encode(dst, src []byte) int 将src编码成最多MaxEncodedLen(len(src))数据写入dst,返回实际写入的字节数。编码每4字节一段进行一次,最后一个片段采用特殊的处理方式,因此不

encoding/base64
base64实现了RFC 4648规定的base64编码 RFC 4648标准化了两种字符集。默认字符集用于MIME(RFC 2045)和PEM(RFC 1421)编码,RFC 4648定义的另一base64编码字符集,用于URL和文件名用'-'和'_'替换了'+'和'/' 对字符进行编解码 var StdEncoding = NewEncoding(encodeStd) const encod

【CS.CN】优化HTTP传输:揭示Transfer-Encoding: chunked的奥秘与应用
文章目录 0 序言0.1 由来0.2 使用场景 1 `Transfer-Encoding: chunked`的机制2 语法 && 通过设置`Transfer-Encoding: chunked`优化性能3 总结References 0 序言 0.1 由来 Transfer-Encoding头部字段在HTTP/1.1中被引入,用于指示数据传输过程中使用的编码方式。常见的

LLM的基础模型7:Positional Encoding
大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。 位置编码 在自然语音处理器中,输入的单词或者Token序列的顺序
iOS: NSString的方法initWithData:encoding:
- (id)initWithData:(NSData *)data encoding:(NSStringEncoding)encoding
SZU:L89 Frog Encoding
Judge Info Memory Limit: 65536KBCase Time Limit: 3000MSTime Limit: 3000MSJudger: Normal Description 青蛙们发现在传输信件时经常会被别人偷看,愤怒的青蛙向码农们求救。于是,码农们为它们提供了一套加密和解密的方法,从而将它们的信件内容加密成一段莫尔斯电码。现在给出译码程序:0.加密序列为:
mb_convert_encoding使用举例
mb_convert_encoding函数使用举例. mb_convert_encoding函数功能非常强大,如果你能够知道一种字符的编码格式,基本上都可以转换成utf-8格式。 说明: mb_convert_encoding — 转换字符的编码 string mb_convert_encoding ( string $str , string $to_encoding [
分块编码(Transfer-Encoding: chunked)(转)
一、背景: 持续连接的问题:对于非持续连接,浏览器可以通过连接是否关闭来界定请求或响应实体的边界;而对于持续连接,这种方法显然不奏效。有时,尽管我已经发送完所有数据,但浏览器并不知道这一点,它无法得知这个打开的连接上是否还会有新数据进来,只能傻傻地等了。用Content-length解决:计算实体长度,并通过头部告诉对方。浏览器可以通过 Content-Length 的长度信息,判断出响应实体已
Python 3 was configured to use ASCII as encoding for the environment 问题解决
写的程序大概逻辑是用py2使用getstatusoutput来执行py3的脚本,然后报错: err info: Traceback (most recent call last):File "/home/zhangwm/Software/ebola_jig/trec-dd-jig/jig/jig.py", line 81, in <module>main()File "/home/zh