lift专题

hdu a strang lift
按得最短路做的,DP 搜索也能搞 #include <cstdio>#include <cstring>#include <algorithm>#include <vector>#include <queue>using namespace std;#define MAX_N 10000#define INF 0xfffftypedef pair<int, int> P;in
Codeforces 479E Riding in a Lift(dp)
题目链接:Codeforces 479E Riding in a Lift 题目大意:有一栋高N层的楼,有个无聊的人在A层,他喜欢玩电梯,每次会做电梯到另外一层。但是这栋楼里有个秘 密实验室在B层,所以每次他移动的时候就有了一个限制,x为当前所在层,y为目标层,|x - y| < |x - b|。问说移动K次 后,有多少不同的路径。 解题思路:dp[i][j]表示在第i步到达j层
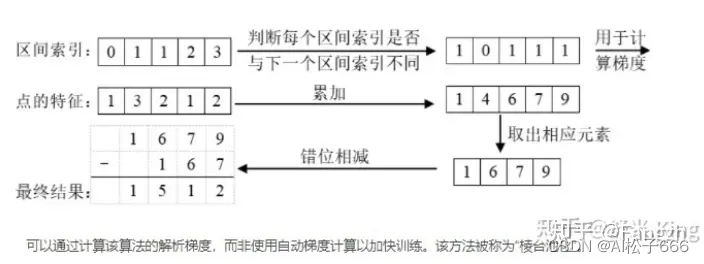
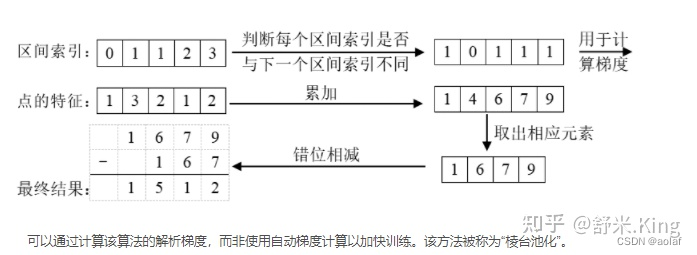
LSS (Lift, Splat, Shoot)代码解析
文章目录 论文研究背景算法实现过程梳理一、相关参数设置二、模型相关参数三、算法前向过程 论文研究背景 LSS是一篇发表在ECCV 2020上有关自动驾驶感知方向的论文,具体子任务为object segmentation and map segmentation。论文和官方repo如下: 论文:https://link.zhihu.com/?target=https%3A//ar

2017.05.25回顾 lift转roc 不会出现前期发力模型
1、上午连续写了两篇小结 2、继续上一篇小结中的第一个问题,定性上觉得可以loss来判断,但是觉得定量上证明比较复杂,我就曲线救国,研究了下这些lift画出roc是什么样子 蓝线是我正常模型的lift曲线,红线是根据boss的描述画出来的,因为E(lift) = 1(这里有错,是当每个decile接近于等分的时候有这个性质),所以红线后面只能越来越平缓,直线是我自己构造出来的,每个dec
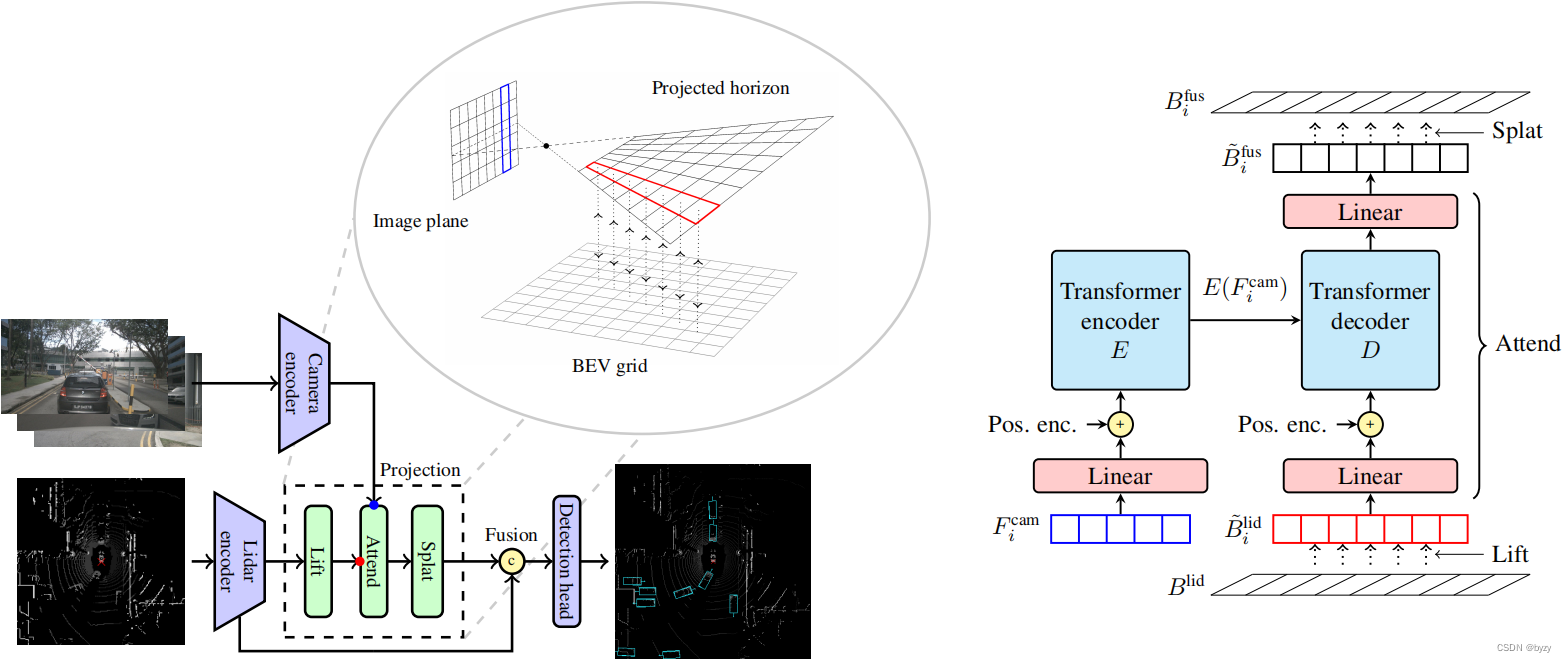
【论文笔记】Lift-Attend-Splat: Bird’s-eye-view camera-lidar fusion using transformers
原文链接:https://arxiv.org/abs/2312.14919 1. 引言 多模态融合时,由于不同模态有不同的过拟合和泛化能力,联合训练不同模态可能会导致弱模态的不充分利用,甚至会导致比单一模态方法性能更低。 目前的相机-激光雷达融合方法多基于Lift-Splat,即基于深度估计投影图像特征到BEV,再与激光雷达特征融合。这高度依赖深度估计的质量。本文发现深度估计不能为这些

A strange lift
题目: There is a strange lift.The lift can stop can at every floor as you want, and there is a number Ki(0 <= Ki <= N) on every floor.The lift have just two buttons: up and down.When you at floor i,if
UVa10801 - Lift Hopping
题意:一栋摩天楼(0~99层)有n个电梯。每个电梯的速度是不一样的,第i个电梯运行(上下)一层要花Ti秒,每个电梯只在某些楼层停,换电梯需要等1分钟。你现在在0层,去往k层,问最少要花多少时间。 思路:SPFA求最短路。 不过这个题建图不是那么好建,索性不建图了。我联想到了平行宇宙。。。假设这个楼在5个世界里都存在。。“穿越”到另一个世界需要花一
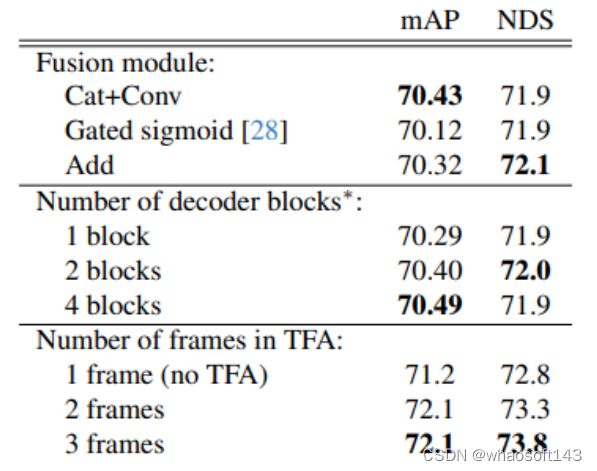
Lift-Attend-Splat
此文转载于大佬哦~~ 感谢 最新BEV LV融合方案 论文:Lift-Attend-Splat: Bird’s-eye-view camera-lidar fusion using transformers 链接:https://arxiv.org/pdf/2312.14919.pdf 结合互补的传感器模态对于为自动驾驶等安全关键应用提供强大的感知至关重要。最近最先进的自动驾驶相机-激光雷
BEV(1)---lift splat shoot
1. 算法简介 1.1 2D坐标与3D坐标的关系 如图,已知世界坐标系上的某点P(Xc, Yc, Zc)经过相机的内参矩阵可以获得唯一的图像坐标p(x, y),但是反过来已知图像上某点p(x, y),无法获得唯一的世界坐标(只能知道P在Ocp这一射线上),只有当深度坐标Zc已知时,我们才可求得唯一的世界坐标P,因此2D坐标往3D坐标的转换多围绕Zc的获取展开。 1.2 LSS原理 LSS
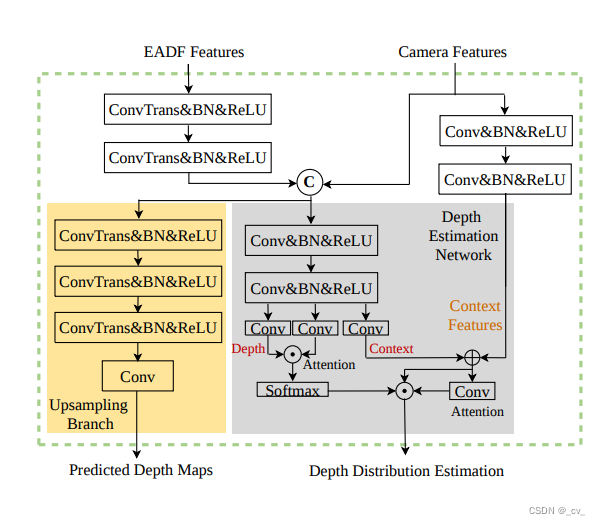
【nuScenes SOTA】EA-LSS:Edge-aware Lift-splat-shot Framework for 3D BEV Object Detection个人解析
文章目录 重点Fine-grained Depth ModuleEdge-aware Depth Fusion Module 重点 这篇文章最主要就是提出来两个模块,如上图所示,一个是FGD Module(Fine-grained Depth Module),另一个是EADF Module(Edge-aware Depth Fusion Module) Fine-g

Lift, Splat, Shoot图像BEV安装与模型代码详解
左侧6帧图像为不同的相机帧,右侧为BEV视角下的分割与路径规划结果 由于本人才疏学浅,解析中难免会出现不足之处,欢迎指正、讨论,有好的建议或意见都可以在评论区留言。谢谢大家! 专栏地址:https://blog.csdn.net/qq_41366026/category_11640689.html?spm=1001.2014.3001.5482 1 前言 计算机视觉算

【LSS】Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
【LSS】Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D 1 摘要 现有的自动驾驶车辆的主要目标是从多个传感器抽取语义信息,并将这些语义信息融合成一个 BEV 坐标系下的特征图,然后进行运动规划。本文作者提出了一个方法,该方法将任意多的相机数据转化成B
rxjava : compose 与 ObservableTransformer、lift 与 ObservableOperator
compose 与 ObservableTransformer : //操作被观察者(abstract class Observable<T> implements ObservableSource<T> )//将源ObservableSource整体转换//通过对它应用特定的Transformer函数来转换ObservableSource。 //此方法在ObservableSource本身
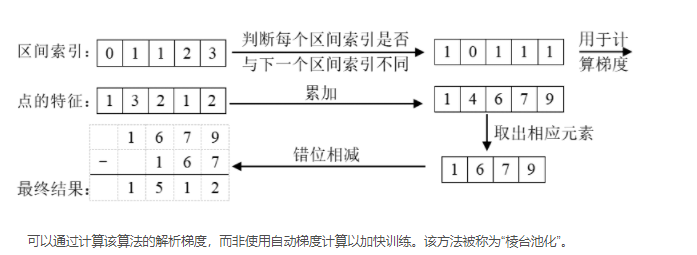
【BEV感知 LSS方案】Lift-Splat-Shoot(LSS)
前言 LSS全称是Lift-Splat-Shoot,它先从车辆周围的多个摄像头拍摄到的图像进行特征提取,在特征图中估计出每个点的深度,然后把这些点“提升”到3D空间中。 接着,这些3D信息被放置到一个网格上,最后将这些信息“拍扁”到一个平面视图上,形成BEV特征图。 Lift,是提升的意思,2D → 3D特征转换模块,将二维图像特征生成3D特征,涉及到深度估计。Splat,是展开的意思,3

Lift, Splat, Shoot图像BEV安装与模型详解
1 前言 计算机视觉算法通常使用图像是作为输入并输出预测的结果,但是对结果所在的坐标系却并不关心,例如图像分类、图像分割、图像检测等任务中,输出的结果均在原始的图像坐标系中。因此这种范式不能很好的与自动驾驶契合。 在自动驾驶中,多个相机传感器的数据一起作为输入,这样每帧图像均在自己的坐标系中;但是感知算法最终需要在车辆自身坐标系(ego coordinate)中输出最终的预测结果;并提供给下游
Lift, Splat, Shoot图像BEV安装与模型详解
1 前言 计算机视觉算法通常使用图像是作为输入并输出预测的结果,但是对结果所在的坐标系却并不关心,例如图像分类、图像分割、图像检测等任务中,输出的结果均在原始的图像坐标系中。因此这种范式不能很好的与自动驾驶契合。 在自动驾驶中,多个相机传感器的数据一起作为输入,这样每帧图像均在自己的坐标系中;但是感知算法最终需要在车辆自身坐标系(ego coordinate)中输出最终的预测结果;并提供给下游

LIFT: Learned Invariant Feature Transform 论文解读
LIFT: Learned Invariant Feature Transform 论文概述 创新点 使用统一的模型进行端到端的有监督训练利用了传统特征提取的先验知识 方法 训练过程 * 分阶段训练* 利用SfM中sift的位置和角度,训练描述符网络* 利用SfM中sift的位置,和训练好的描述符网络,训练旋转估计网络* 利用已经训练好的旋转估计和描述符网络训练特征点提取网络* 损失

BEV经典之作Lift, Splat, Shoot解析
第一篇:LSS算法数据shape流程图 - 知乎 Lift Splat Shoot算法是一种用于自动驾驶感知的算法,它由NVIDIA提出。该算法通过将多视角相机图像转换为3D空间中的特征表示。其主要思想是将每个相机的图像通过"抬升(Lift)"的方式生成3D特征,然后将这些3D特征通过"拍扁(Splat)"的方式投射到光栅化的鸟瞰图网格中。最后,通过将模板运动轨迹"投射(Shoot)"到网络输出