本文主要是介绍LSS (Lift, Splat, Shoot)代码解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 论文研究背景
- 算法实现过程梳理
- 一、相关参数设置
- 二、模型相关参数
- 三、算法前向过程
论文研究背景
LSS是一篇发表在ECCV 2020上有关自动驾驶感知方向的论文,具体子任务为object segmentation and map segmentation。论文和官方repo如下:
论文:https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/2008.05711.pdf
官方repo:https://link.zhihu.com/?target=https%3A//github.com/nv-tlabs/lift-splat-shoot
目前在自动驾驶领域,比较火的一类研究方向是基于采集到的环视图像信息,去构建BEV视角下的特征完成自动驾驶感知的相关任务。所以如何准确的完成从相机视角向BEV视角下的转变就变得由为重要。目前感觉比较主流的方法可以大体分为两种:1)显式估计图像的深度信息,完成BEV视角的构建,在某些文章中也被称为自下而上的构建方式;2)利用transformer中的query查询机制,利用BEV Query构建BEV特征,这一过程也被称为自上而下的构建方式;
LSS这篇论文的核心则是通过显式估计图像的深度信息,对采集到的环视图像进行特征提取,并根据估计出来的离散深度信息,实现图像特征向BEV特征的转换,进而完成自动驾驶中的语义分割任务。
 论文中展示的插图:右侧为LSS算法根据当前帧的六张环视图像得到的BEV视角下的语义感知结果
论文中展示的插图:右侧为LSS算法根据当前帧的六张环视图像得到的BEV视角下的语义感知结果
算法实现过程梳理
一、相关参数设置
对于感知算法而言,我认为比较重要的是要了解在BEV视角下,x轴和y轴方向的感知距离,以及BEV网格的单位大小。在LSS源码中,其感知范围,BEV单元格大小,BEV下的网格尺寸如下:
1.感知范围
x轴方向的感知范围 -50m ~ 50m;y轴方向的感知范围 -50m ~ 50m;z轴方向的感知范围 -10m ~ 10m;
2.BEV单元格大小
x轴方向的单位长度 0.5m;y轴方向的单位长度 0.5m;z轴方向的单位长度 20m;
3.BEV的网格尺寸
200 x 200 x 1;
4.深度估计范围
由于LSS需要显式估计像素的离散深度,论文给出的范围是 4m ~ 45m,间隔为1m,也就是算法会估计41个离散深度;
二、模型相关参数
模型用到的参数主要包括以下7个参数,分别是imgs,rots,trans,intrinsic,post_rots,post_trans,binimgs;
imgs:输入的环视相机图片,imgs = (bs, N, 3, H, W),N代表环视相机个数;
rots:由相机坐标系->车身坐标系的旋转矩阵,rots = (bs, N, 3, 3);
trans:由相机坐标系->车身坐标系的平移矩阵,trans=(bs, N, 3);
intrinsic:相机内参,intrinsic = (bs, N, 3, 3);
post_rots:由图像增强引起的旋转矩阵,post_rots = (bs, N, 3, 3);
post_trans:由图像增强引起的平移矩阵,post_trans = (bs, N, 3);
binimgs:由于LSS做的是语义分割任务,所以会将真值目标投影到BEV坐标系,将预测结果与真值计算损失;具体而言,在binimgs中对应物体的bbox内的位置为1,其他位置为0;
三、算法前向过程
在进行详细描述LSS算法前向过程之前,先整体概括下LSS算法包括的五个步骤。1)生成视锥,并根据相机内外参将视锥中的点投影到ego坐标系;2)对环视图像完成特征的提取,并构建图像特征点云;3)利用变换后的ego坐标系的点与图像特征点云利用Voxel Pooling构建BEV特征;4)对生成的BEV特征利用BEV Encoder做进一步的特征融合;5)利用特征融合后的BEV特征完成语义分割任务;
1.生成视锥,并完成视锥锥点由图像坐标系->ego坐标系的空间位置转换
a)生成视锥
需要注意的是,生成的锥点,其位置是基于图像坐标系的,同时锥点是图像特征上每个单元格映射回原始图像的位置。生成方式如下:
def create_frustum():# 原始图片大小 ogfH:128 ogfW:352ogfH, ogfW = self.data_aug_conf['final_dim']# 下采样16倍后图像大小 fH: 8 fW: 22fH, fW = ogfH // self.downsample, ogfW // self.downsample # self.grid_conf['dbound'] = [4, 45, 1]# 在深度方向上划分网格 ds: DxfHxfW (41x8x22)ds = torch.arange(*self.grid_conf['dbound'], dtype=torch.float).view(-1, 1, 1).expand(-1, fH, fW)D, _, _ = ds.shape # D: 41 表示深度方向上网格的数量"""1. torch.linspace(0, ogfW - 1, fW, dtype=torch.float)tensor([0.0000, 16.7143, 33.4286, 50.1429, 66.8571, 83.5714, 100.2857,117.0000, 133.7143, 150.4286, 167.1429, 183.8571, 200.5714, 217.2857,234.0000, 250.7143, 267.4286, 284.1429, 300.8571, 317.5714, 334.2857,351.0000])2. torch.linspace(0, ogfH - 1, fH, dtype=torch.float)tensor([0.0000, 18.1429, 36.2857, 54.4286, 72.5714, 90.7143, 108.8571,127.0000])"""# 在0到351上划分22个格子 xs: DxfHxfW(41x8x22)xs = torch.linspace(0, ogfW - 1, fW, dtype=torch.float).view(1, 1, fW).expand(D, fH, fW) # 在0到127上划分8个格子 ys: DxfHxfW(41x8x22)ys = torch.linspace(0, ogfH - 1, fH, dtype=torch.float).view(1, fH, 1).expand(D, fH, fW) # D x H x W x 3# 堆积起来形成网格坐标, frustum[i,j,k,0]就是(i,j)位置,深度为k的像素的宽度方向上的栅格坐标 frustum: DxfHxfWx3frustum = torch.stack((xs, ys, ds), -1) return nn.Parameter(frustum, requires_grad=False)
b)锥点由图像坐标系向ego坐标系进行坐标转化
这一过程主要涉及到相机的内外参数,对应代码中的函数为get_geometry();
def get_geometry(self, rots, trans, intrins, post_rots, post_trans):B, N, _ = trans.shape # B: batch size N:环视相机个数# undo post-transformation# B x N x D x H x W x 3# 抵消数据增强及预处理对像素的变化points = self.frustum - post_trans.view(B, N, 1, 1, 1, 3)points = torch.inverse(post_rots).view(B, N, 1, 1, 1, 3, 3).matmul(points.unsqueeze(-1))# 图像坐标系 -> 归一化相机坐标系 -> 相机坐标系 -> 车身坐标系# 但是自认为由于转换过程是线性的,所以反归一化是在图像坐标系完成的,然后再利用# 求完逆的内参投影回相机坐标系points = torch.cat((points[:, :, :, :, :, :2] * points[:, :, :, :, :, 2:3],points[:, :, :, :, :, 2:3]), 5) # 反归一化combine = rots.matmul(torch.inverse(intrins))points = combine.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1)points += trans.view(B, N, 1, 1, 1, 3)# (bs, N, depth, H, W, 3):其物理含义# 每个batch中的每个环视相机图像特征点,其在不同深度下位置对应# 在ego坐标系下的坐标return points
2.对环视图像进行特征提取,并构建图像特征点云
a)利用Efficientnet-B0主干网络对环视图像进行特征提取
输入的环视图像 (bs, N, 3, H, W),在进行特征提取之前,会将前两个维度进行合并,一起提取特征,对应维度变换为 (bs, N, 3, H, W) -> (bs * N, 3, H, W);其输出的多尺度特征尺寸大小如下:
level0 = (bs * N, 16, H / 2, W / 2)
level1 = (bs * N, 24, H / 4, W / 4)
level2 = (bs * N, 40, H / 8, W / 8)
level3 = (bs * N, 112, H / 16, W / 16)
level4 = (bs * N, 320, H / 32, W / 32)
b)对其中的后两层特征进行融合,丰富特征的语义信息,融合后的特征尺寸大小为 (bs * N, 512, H / 16, W / 16)
Step1: 对最后一层特征升采样到倒数第二层大小;
level4 -> Up -> level4' = (bs * N, 320, H / 16, W / 16)Step2:对主干网络输出的后两层特征进行concat;
cat(level4', level3) -> output = (bs * N, 432, H / 16, W / 16)Step3:对concat后的特征,利用ConvLayer卷积层做进一步特征拟合;ConvLayer(output) -> output' = (bs * N, 512, H / 16, W / 16)其中ConvLayer层构造如下:
"""Sequential((0): Conv2d(432, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)
)"""
c)估计深度方向的概率分布并输出特征图每个位置的语义特征 (用64维的特征表示),整个过程用1x1卷积层实现
c)步骤整体pipeline
output' -> Conv1x1 -> x = (bs * N, 105, H / 16, W / 16)b)步骤输出的特征:
output = Tensor[(bs * N, 512, H / 16, W / 16)]c)步骤使用的1x1卷积层:
Conv1x1 = Conv2d(512, 105, kernel_size=(1, 1), stride=(1, 1))c)步骤输出的特征以及对应的物理含义:
x = Tensor[(bs * N, 105, H / 16, W / 16)]
第二维的105个通道分成两部分;第一部分:前41个维度代表不同深度上41个离散深度;第二部分:后64个维度代表特征图上的不同位置对应的语义特征;
d)对c)步骤估计出来的离散深度利用softmax()函数计算深度方向的概率密度
e)利用得到的深度方向的概率密度和语义特征通过外积运算构建图像特征点云
代码实现:
# d)步骤得到的深度方向的概率密度
depth = (bs * N, 41, H / 16, W / 16) -> unsqueeze -> (bs * N, 1, 41, H / 16, W / 16)# c)步骤得到的特征,选择后64维是预测出来的语义特征
x[:, self.D:(self.D + self.C)] = (bs * N, 64, H / 16, W / 16) -> unsqueeze(2) -> (bs * N, 64, 1 , H / 16, W / 16)# 概率密度和语义特征做外积,构建图像特征点云
new_x = depth.unsqueeze(1) * x[:, self.D:(self.D + self.C)].unsqueeze(2) # (bs * N, 64, 41, H / 16, W / 16)
论文图例:
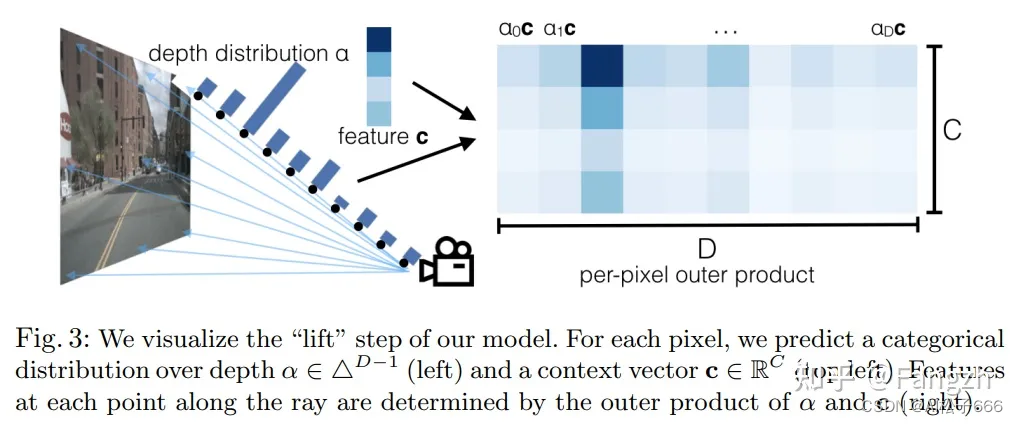
论文中表示构建图像特征点云的实现过程插图
3. 利用ego坐标系下的坐标点与图像特征点云,利用Voxel Pooling构建BEV特征
a)Voxel Pooling前的准备工作
def voxel_pooling(self, geom_feats, x):# geom_feats;(B x N x D x H x W x 3):在ego坐标系下的坐标点;# x;(B x N x D x fH x fW x C):图像点云特征B, N, D, H, W, C = x.shapeNprime = B*N*D*H*W # 将特征点云展平,一共有 B*N*D*H*W 个点x = x.reshape(Nprime, C) # flatten indicesgeom_feats = ((geom_feats - (self.bx - self.dx/2.)) / self.dx).long() # ego下的空间坐标转换到体素坐标(计算栅格坐标并取整)有点像栅格化。geom_feats = geom_feats.view(Nprime, 3) # 将体素坐标同样展平,geom_feats: (B*N*D*H*W, 3)batch_ix = torch.cat([torch.full([Nprime//B, 1], ix,device=x.device, dtype=torch.long) for ix in range(B)]) # 每个点对应于哪个batchgeom_feats = torch.cat((geom_feats, batch_ix), 1) # geom_feats: (B*N*D*H*W, 4)# filter out points that are outside box# 过滤掉在边界线之外的点 x:0~199 y: 0~199 z: 0kept = (geom_feats[:, 0] >= 0) & (geom_feats[:, 0] < self.nx[0])\& (geom_feats[:, 1] >= 0) & (geom_feats[:, 1] < self.nx[1])\& (geom_feats[:, 2] >= 0) & (geom_feats[:, 2] < self.nx[2])x = x[kept]geom_feats = geom_feats[kept]# get tensors from the same voxel next to each otherranks = geom_feats[:, 0] * (self.nx[1] * self.nx[2] * B)\+ geom_feats[:, 1] * (self.nx[2] * B)\+ geom_feats[:, 2] * B\+ geom_feats[:, 3] # 给每一个点一个rank值,rank相等的点在同一个batch,并且在在同一个格子里面sorts = ranks.argsort()x, geom_feats, ranks = x[sorts], geom_feats[sorts], ranks[sorts] # 按照rank排序,这样rank相近的点就在一起了# cumsum trickif not self.use_quickcumsum:x, geom_feats = cumsum_trick(x, geom_feats, ranks)else:x, geom_feats = QuickCumsum.apply(x, geom_feats, ranks)# griddify (B x C x Z x X x Y)final = torch.zeros((B, C, self.nx[2], self.nx[0], self.nx[1]), device=x.device) # final: bs x 64 x 1 x 200 x 200final[geom_feats[:, 3], :, geom_feats[:, 2], geom_feats[:, 0], geom_feats[:, 1]] = x # 将x按照栅格坐标放到final中# collapse Zfinal = torch.cat(final.unbind(dim=2), 1) # 消除掉z维return final # final: bs x 64 x 200 x 200
b)采用cumsum_trick完成Voxel Pooling运算,代码和图例如下:
主要需要注意的,图中的区间索引代表下面代码中的ranks,点的特征代表的是x;
代码:
class QuickCumsum(torch.autograd.Function):@staticmethoddef forward(ctx, x, geom_feats, ranks):x = x.cumsum(0) # 求前缀和kept = torch.ones(x.shape[0], device=x.device, dtype=torch.bool) kept[:-1] = (ranks[1:] != ranks[:-1]) # 筛选出ranks中前后rank值不相等的位置x, geom_feats = x[kept], geom_feats[kept] # rank值相等的点只留下最后一个,即一个batch中的一个格子里只留最后一个点x = torch.cat((x[:1], x[1:] - x[:-1])) # x后一个减前一个,还原到cumsum之前的x,此时的一个点是之前与其rank相等的点的feature的和,相当于把同一个格子的点特征进行了sum# save kept for backwardctx.save_for_backward(kept)# no gradient for geom_featsctx.mark_non_differentiable(geom_feats)return x, geom_feats
图例:
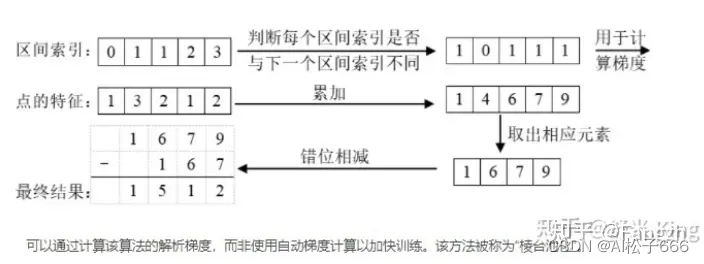
图例来源:https://zhuanlan.zhihu.com/p/567880155(侵删)
4 + 5. 对生成的BEV特征利用BEV Encoder做进一步的特征融合 + 语义分割结果预测
a)对BEV特征先利用ResNet-18进行多尺度特征提取,输出的多尺度特征尺寸如下
level0:(bs, 64, 100, 100)
level1: (bs, 128, 50, 50)
level2: (bs, 256, 25, 25)
b)对输出的多尺度特征进行特征融合 + 对融合后的特征实现BEV网格上的语义分割
Step1: level2 -> Up (4x) -> level2' = (bs, 256, 100, 100)Step2: concat(level2', level0) -> output = (bs, 320, 100, 100)Step3: ConvLayer(output) -> output' = (bs, 256, 100, 100)'''ConvLayer的配置如下
Sequential((0): Conv2d(320, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(2): ReLU(inplace=True)(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(5): ReLU(inplace=True)
)'''Step4: Up2(output') -> final = (bs, 1, 200, 200) # 第二个维度的1就代表BEV每个网格下的二分类结果
'''Up2的配置如下
Sequential((0): Upsample(scale_factor=2.0, mode=bilinear)(1): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)(2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)(3): ReLU(inplace=True)(4): Conv2d(128, 1, kernel_size=(1, 1), stride=(1, 1))
)'''
最后就是将输出的语义分割结果与binimgs的真值标注做基于像素的交叉熵损失,从而指导模型的学习过程。
以上就是LSS算法的整体实现流程,如有错误,欢迎大家在评论区评论指正!😃
本篇文章转载自:https://zhuanlan.zhihu.com/p/589146284
这篇关于LSS (Lift, Splat, Shoot)代码解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






