本文主要是介绍Lift-Attend-Splat,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
此文转载于大佬哦~~ 感谢
最新BEV LV融合方案
论文:Lift-Attend-Splat: Bird’s-eye-view camera-lidar fusion using transformers
链接:https://arxiv.org/pdf/2312.14919.pdf
结合互补的传感器模态对于为自动驾驶等安全关键应用提供强大的感知至关重要。最近最先进的自动驾驶相机-激光雷达融合方法依赖于单目深度估计,与直接使用激光雷达的深度信息相比,这是一项困难任务。在这里,我们发现这种方法并没有像预期的那样利用深度,并表明天真地改进深度估计并不能提高目标检测性能,而且令人惊讶的是,完全消除深度估计并不会降低目标检测性能。
这表明,在相机-激光雷达融合过程中,依赖单目深度可能是一个不必要的架构瓶颈。本文介绍了一种新的融合方法,该方法完全绕过单目深度估计,而是使用简单的注意力机制在BEV网格中选择和融合相机和激光雷达的特征。论文表明,提出的模型可以根据激光雷达特征的可用性调整其对相机特征的使用,并且它在nuScenes数据集上比依赖于单目深度估计的基线产生更好的3D检测性能。
本文介绍了一种新的相机-激光雷达融合方法,称为“Lift Attented Splat”,该方法完全绕过单目深度估计,而是使用简单的transformer在BEV中选择和融合相机和激光雷达特征。证据表明,与基于Monocular深度估计的方法相比,本文的方法显示出更好的相机利用率,并提高了物体检测性能。贡献如下:
-
基于Lift Splat范式的相机-激光雷达融合方法并没有像预期的那样利用深度。特别地,我们表明,如果完全去除单目深度预测,它们的性能相当或更好。
-
本文介绍了一种新的相机-激光雷达融合方法,该方法使用简单的注意力机制融合纯BEV中的相机和激光雷达特征。论文证明,与基于Lift Splat范式的模型相比,它可以更好地利用相机,并提高3D检测性能。
主要结构介绍
Lift Splat深度预测通常较差,通过使用绝对相对误差(Abs.Rel.)和均方根误差(RMSE)将其与激光雷达深度图进行定性和定量比较,来分析BEVFusion预测的深度质量。如图1所示,深度预测不能准确反映场景的结构,并且与激光雷达深度图明显不同,后者表明单目深度没有如预期的那样得到利用。论文还进行了研究,改进深度预测并不能提高检测性能!完全取消深度预测不会影响物体检测性能。

我们提出了一种相机-激光雷达融合方法,该方法完全绕过单目深度估计,而是使用简单的transformer在鸟瞰图中融合相机和激光雷达特征。然而,由于大量的相机和激光雷达特征以及注意力的二次性,transformer架构很难简单地应用于相机-激光雷达融合问题。在BEV中投影相机特征时,可以使用问题的几何形状来大幅限制注意力的范围,因为相机特征应该只对沿其相应光线的位置有贡献。我们将这一想法应用于相机-激光雷达融合的情况,并介绍了一种简单的融合方法,该方法使用相机平面中的柱和激光雷达BEV网格中的极射线之间的交叉注意力!交叉注意力不是预测单目深度,而是在激光雷达特征沿着其光线提供的背景下,学习哪些相机特征是最显著的。
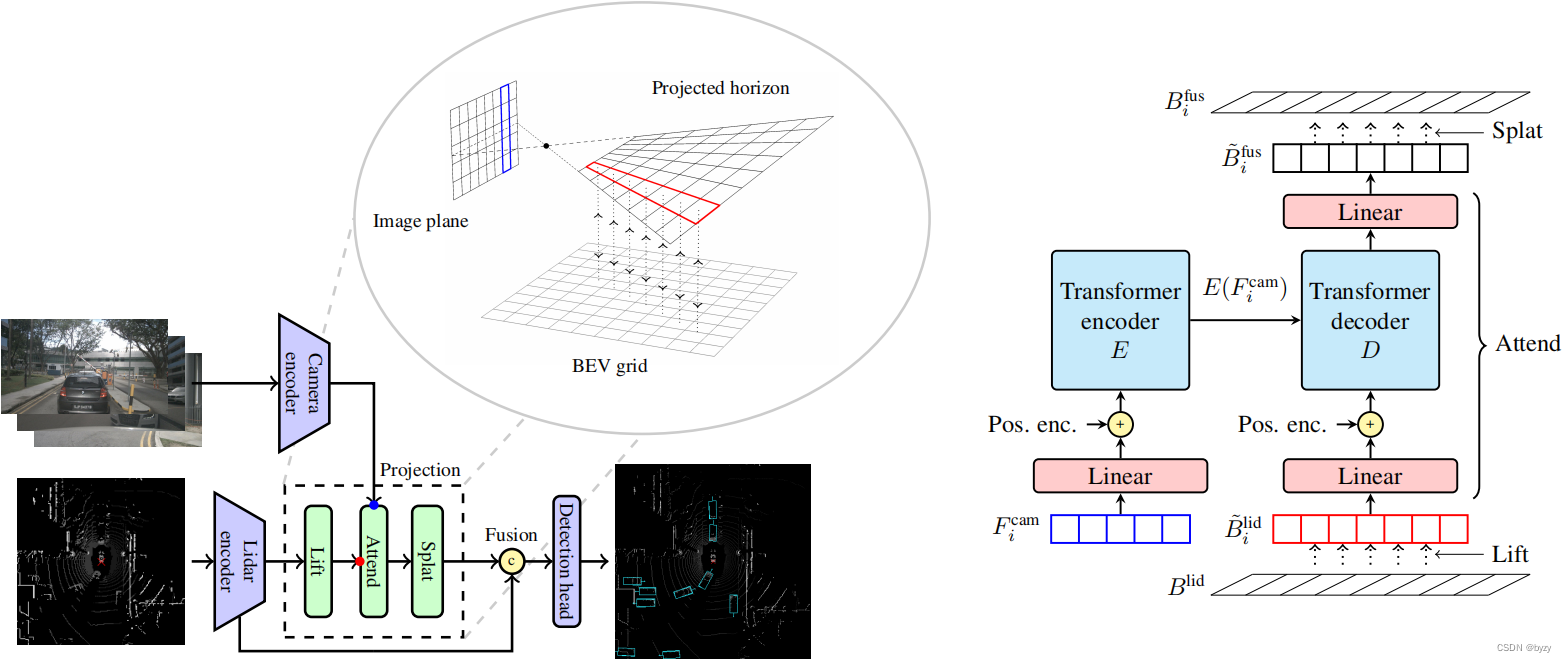
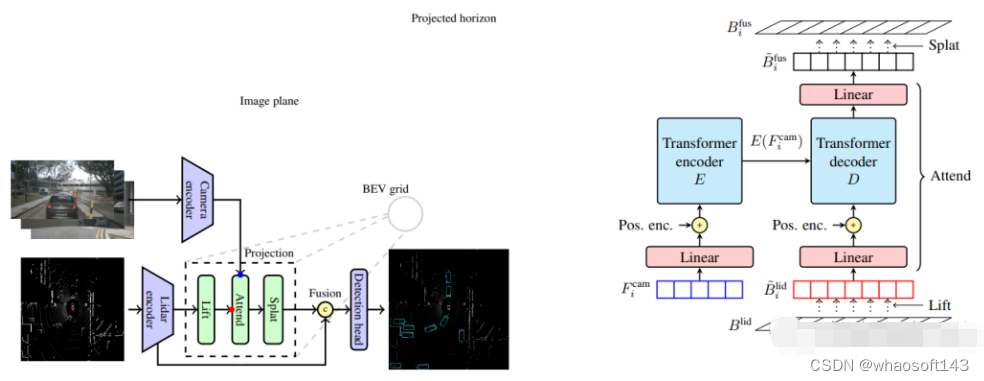
除了在BEV中投影相机特征外,我们的模型与基于Lift Splat范式的方法具有相似的总体架构,如下图所示。它由以下模块组成:相机和激光雷达主干,独立生成每个模态的特征;投影和融合模块,将相机特征嵌入BEV并与激光雷达融合;最后是检测头。当考虑目标检测时,模型的最终输出是场景中目标的属性,表示为具有位置、维度、方向、速度和分类信息的3D边界框。
Lift Attented Splat相机激光雷达融合架构如下所示。(左)总体架构:相机和激光雷达主干的特征在传递到检测头之前融合在一起。(inset)我们的3D投影的几何结构:“Lift”步骤通过使用双线性采样沿z方向提升激光雷达特征,将激光雷达BEV特征嵌入投影地平线。“splat”步骤对应于逆变换,因为它使用双线性采样将特征从投影的地平线投影回BEV网格,再次沿着z方向!右边是project模块的细节部分。 whaosoft aiot http://143ai.com
实验结果
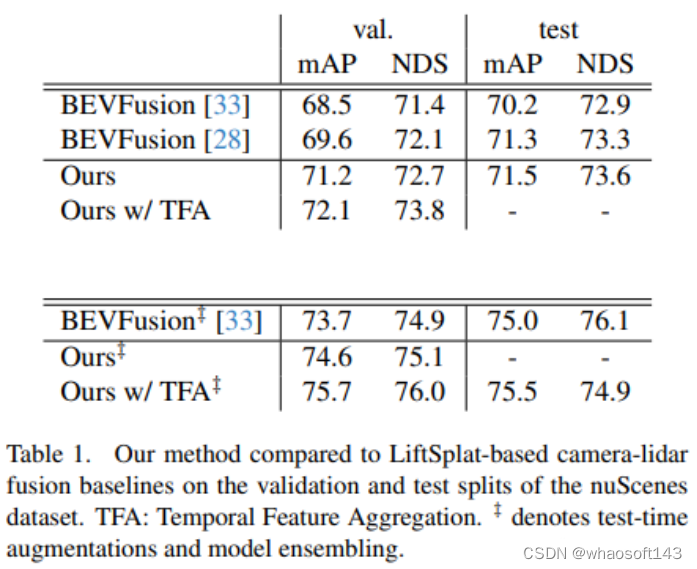

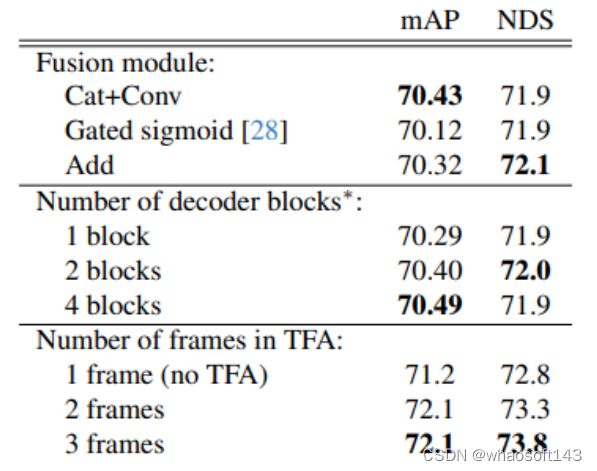
这篇关于Lift-Attend-Splat的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!