attend专题

Show,Attend and Tell: Neural Image Caption Generation with Visual Attention
简单的翻译阅读了一下 Abstract 受机器翻译和对象检测领域最新工作的启发,我们引入了一种基于注意力的模型,该模型可以自动学习描述图像的内容。我们描述了如何使用标准的反向传播技术,以确定性的方式训练模型,并通过最大化变分下界随机地训练模型。我们还通过可视化展示了模型如何能够自动学习将注视固定在显着对象上,同时在输出序列中生成相应的单词。我们通过三个基准数据集(Flickr9k,Flickr
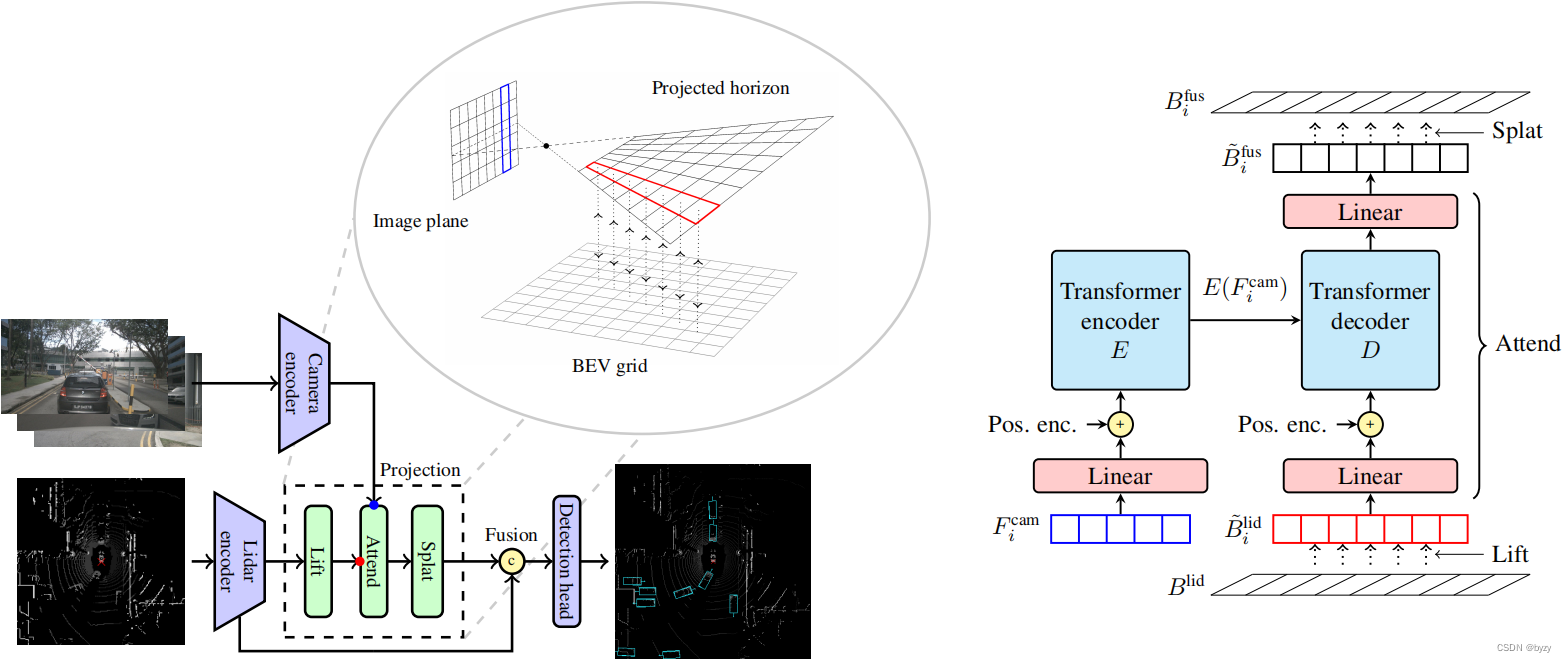
【论文笔记】Lift-Attend-Splat: Bird’s-eye-view camera-lidar fusion using transformers
原文链接:https://arxiv.org/abs/2312.14919 1. 引言 多模态融合时,由于不同模态有不同的过拟合和泛化能力,联合训练不同模态可能会导致弱模态的不充分利用,甚至会导致比单一模态方法性能更低。 目前的相机-激光雷达融合方法多基于Lift-Splat,即基于深度估计投影图像特征到BEV,再与激光雷达特征融合。这高度依赖深度估计的质量。本文发现深度估计不能为这些
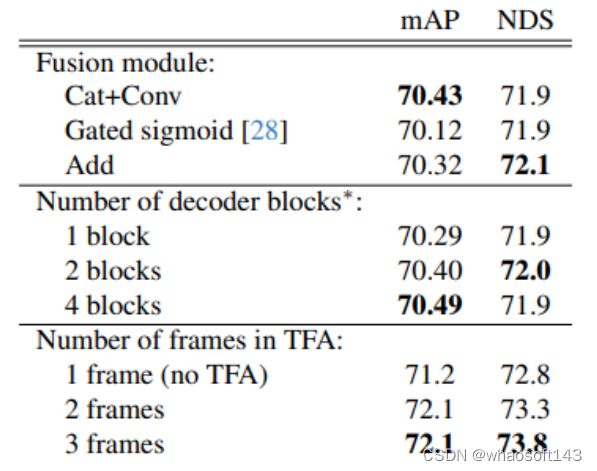
Lift-Attend-Splat
此文转载于大佬哦~~ 感谢 最新BEV LV融合方案 论文:Lift-Attend-Splat: Bird’s-eye-view camera-lidar fusion using transformers 链接:https://arxiv.org/pdf/2312.14919.pdf 结合互补的传感器模态对于为自动驾驶等安全关键应用提供强大的感知至关重要。最近最先进的自动驾驶相机-激光雷

Show attend and Tell模型
改进 对之前Show and Tell模型的衍生,多了一个attend ,加入了一个attention机制 (一种加权机制)卷积神经网络从全连接层改成了卷积层hadow_50,text_Q1NETiBA54mn576KTEw=,size_20,color_FFFFFF,t_70,g_se,x_16)。通过卷积层,可以得到一个照片的位置信息(通过卷积核的视野域,确定信息在矩阵的位置)卷积网络对