本文主要是介绍【BEV感知 LSS方案】Lift-Splat-Shoot(LSS),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
LSS全称是Lift-Splat-Shoot,它先从车辆周围的多个摄像头拍摄到的图像进行特征提取,在特征图中估计出每个点的深度,然后把这些点“提升”到3D空间中。
接着,这些3D信息被放置到一个网格上,最后将这些信息“拍扁”到一个平面视图上,形成BEV特征图。
- Lift,是提升的意思,2D → 3D特征转换模块,将二维图像特征生成3D特征,涉及到深度估计。
- Splat,是展开的意思,3D → BEV特征编码模块,把3D特征“拍扁”得到BEV特征图。
- Shooting,是指在BEV特征图上进行相关任务操作,比如检测、分割、轨迹预测等。
论文地址:Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
代码地址:https://github.com/nv-tlabs/lift-splat-shoot

一、Lift 2D → 3D特征转换模块
"Lift-Splat-Shoot"(LSS)中的 "Lift" 部分是这个系统中的一个关键步骤,它用于将2D图像数据转换为3D空间中的特征。
目的:"Lift" 的目的是要确定2D图像中的每个像素在3D空间中的位置,特别是它们的深度信息。这对于理解和解释3D世界非常关键。
深度信息的重要性:在3D世界中,要确定一个对象的确切位置,仅有2D像素坐标是不够的。我们还需要知道这个像素点距离相机的深度(即它有多远)。
获取深度信息:在没有深度相机这类设备的情况下,LSS系统通过为每个像素点生成一系列可能的深度值来估计深度信息,简称为“深度离散预估”。这是一个创新的方法。
下面详细介绍一下,首先看看下面的图,不同的物体距离相机的距离是不一样的。比如,小狗距离相机是4m,汽车距离相机是43m。
我们将4米到44米的范围内生成一系列离散的深度值,每隔1米一个,就形成下面图的结果了。
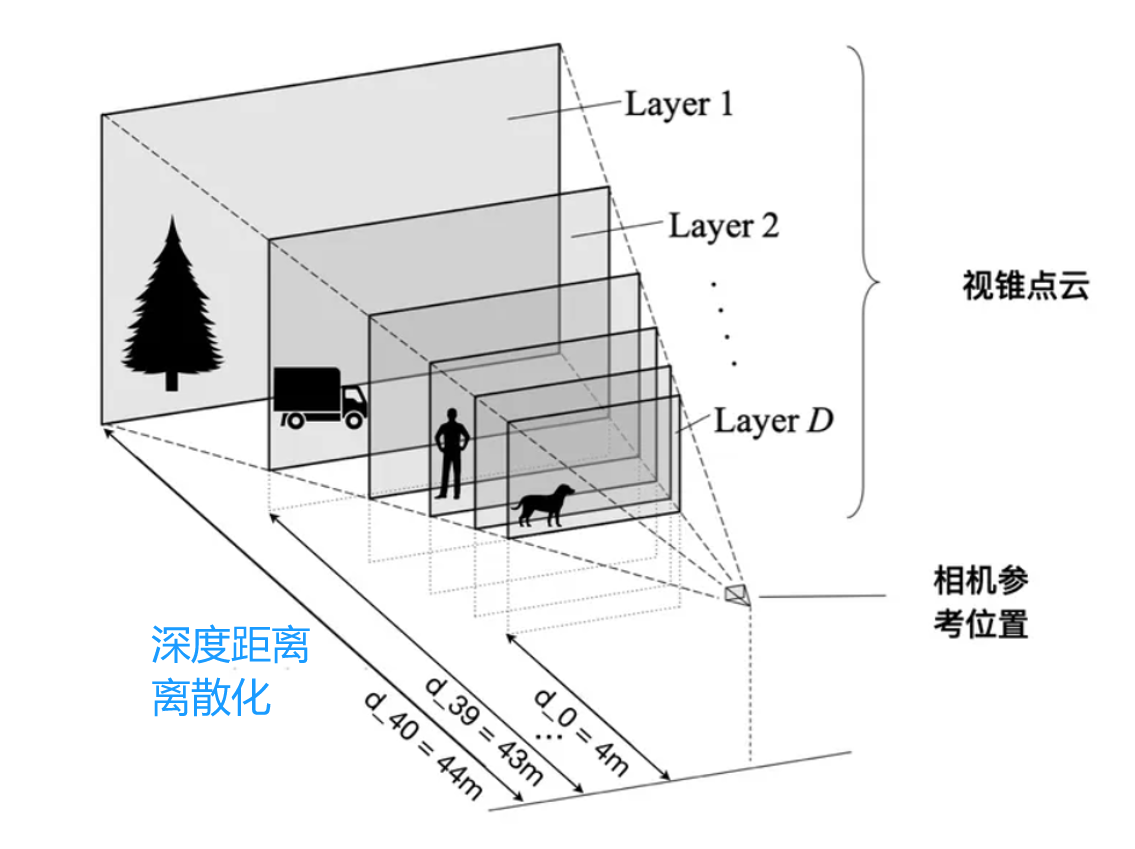
考虑 2D 图片上的一个点对应 3D 世界的一条射线,现在不知道的是该像素具体在射线上位置,即不知道该像素的深度值,
故可以在这条直线上采样 N 个点(比如 41 个),每个点对应深度离散值,每隔1米一个。

在下图中,相机视锥中一根射线上设置了10个可选深度值,即D=10,第三个深度下特征最为显著,因此该位置的深度值为第三个。
注意,深度值LSS论文例图用了10个,实际代码用了41个。
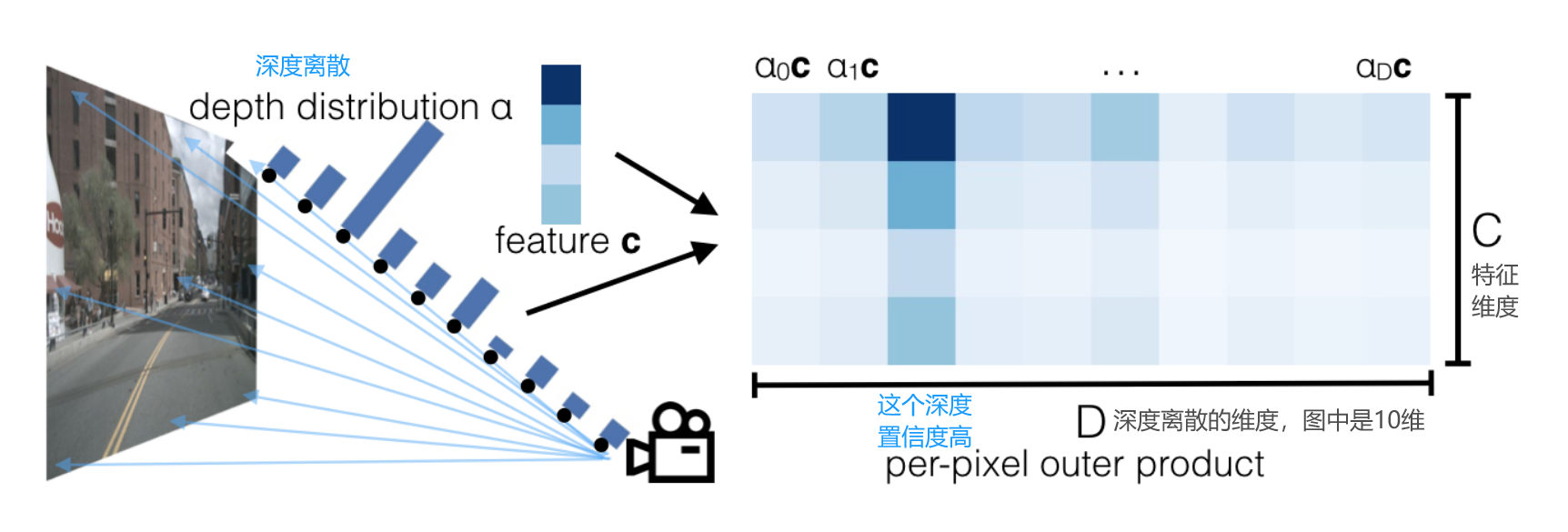
在官方的LSS实现中,对于图像中的每个像素点,系统会在5米到45米的范围内生成一系列离散的深度值,每隔1米一个。这样,每个像素点就有41个可能的深度值可供选择。
对一张图片每个 2D 特征点做相同的操作,就可以生成一个形状类似平头金字塔 (frustum) 的点云。
在训练过程中,深度学习网络会自动选择每个像素点的最合适深度值。
整理一下思路:
-
深度特征的表示:每个像素点有一个d维的深度分布。这个深度分布用于表示该像素在3D空间中的位置,特别是它距离相机的深度。
-
联合特征表示:一个像素点的整体特征由它的c维图像特征和d维深度特征共同表示,形成一个d,c,h,w的四维向量。
-
深度值的概率表示:对于每个像素点,其在3D空间中的确切深度是不确定的。因此,系统通过划分1米间隔的深度格子,并使用D维向量(通过softmax函数处理)来表示该像素点处于每个深度格子的概率。在这里,D=41,代表4米到45米范围内的每1米间隔。
实现代码:
class CamEncode(nn.Module):def __init__(self, D, C, downsample):super(CamEncode, self).__init__()self.D = Dself.C = Cself.trunk = EfficientNet.from_pretrained("efficientnet-b0")self.up1 = Up(320+112, 512)# 输出通道数为D+C,D为可选深度值个数,C为特征通道数self.depthnet = nn.Conv2d(512, self.D + self.C, kernel_size=1, padding=0)def get_depth_dist(self, x, eps=1e-20):return x.softmax(dim=1)def get_depth_feat(self, x):# 主干网络提取特征x = self.get_eff_depth(x)# 输出通道数为D+Cx = self.depthnet(x)# softmax编码,相理解为每个可选深度的权重depth = self.get_depth_dist(x[:, :self.D])# 深度值 * 特征 = 2D特征转变为3D空间(俯视图)内的特征new_x = depth.unsqueeze(1) * x[:, self.D:(self.D + self.C)].unsqueeze(2)return depth, new_xdef get_eff_depth(self, x):......return xdef forward(self, x):depth, x = self.get_depth_feat(x)return x总结
"Lift"阶段通过为每个像素点提供一系列可能的深度值,然后利用深度学习来选择最合适的深度,从而将2D图像信息转换为3D世界中的特征。这是LSS系统中的一个重要创新,它使得3D感知在没有专用深度传感器的情况下成为可能。
二、Splat 3D → BEV特征编码模块
"Lift-Splat-Shoot"(LSS)系统中的 "Lift" 步骤之后,来到“Splat”,接下来的目标是确定2D像素点在3D空间中的确切坐标。这个过程可以分解为以下几个步骤:
-
确定3D坐标:一旦我们通过 "Lift" 步骤获得了2D像素点的深度信息,结合这个点的2D像素坐标、相机的内部参数(内参),以及相机相对于车辆的位置和方向(外参),我们就可以计算出该像素点在车辆坐标系中的3D坐标。
-
投影到俯视图:接着,系统将这些3D坐标投影到一个统一的BEV图中。这个BEV图是以车辆为中心的,通常覆盖一个200x 200的区域。
-
过滤感兴趣域外的点:在创建俯视图时,系统会过滤掉那些不在感兴趣区域(比如车辆周围200 x 200范围)内的点。
-
处理重叠的特征:在俯视图中,同一个3D坐标可能对应多个不同的特征,这可能是因为:
- 单张2D图像中不同像素点被投影到了俯视图的同一位置。
- 来自不同相机的图像中,不同像素点被投影到了俯视图的同一位置。
- 视锥点云转换到BEV后:每个点都会被分配到BEV的柱子里面,这个柱子就是BEV空间每个grid都对应一个[dx, dy, 高]的立方体,这样每一个grid的特征就是在里面所有点对应的图像特征求和。
-
sum-pooling方法:为了处理这种重叠,作者使用了一种叫做 "sum-pooling" 的方法,累积求和方法。这种方法将同一位置的所有特征汇总起来,计算出一个新的综合特征。
-
生成最终特征图:通过上述过程,系统最终生成了一个200x200像素大小的特征图,其中每个像素包含C个特征(在源码中,C通常设为64)。
-
计算损失:最后接个一个BevEncode的模块,将200x200xC的特征生成200x200x1的特征用于loss的计算。
补充一下:视锥体池化 Frustum Pooling ——累积求和
首先通过“bin id”对所有点进行排序。然后,对所有特征执行累积求和操作。
在累积求和池化中,系统会减去bin部分边界处的累积求和值。这样做可以更有效地计算每个特征区域内的总和。
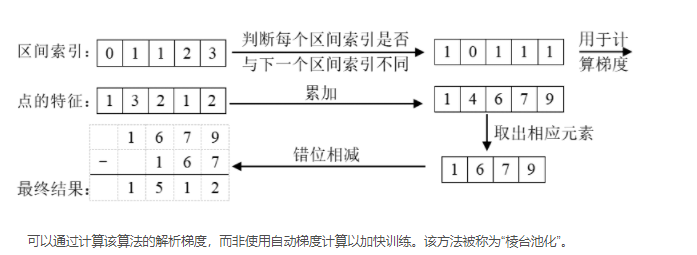
这种方法的一个关键优势是它不需要依赖于自动梯度(autograd)方法来进行反向传播。
相反,它可以导出整个模块的分析梯度。这意味着在训练过程中,数据的反向传播更加高效,从而将训练速度提高了大约2倍。
“Frustum Pooling”层的主要作用是处理来自多个图像的视锥体,并将它们转换为与相机数量无关的固定维度C×H×W的张量。在这里,视锥体是指由每个相机产生的3D数据区域。
通过“Frustum Pooling”,无论有多少相机(n个),最终的特征表示都会被转换成固定的维度,这使得处理多相机系统时更加高效和统一。
计算得出像素对应的在车身坐标系中的3D坐标,示例代码:
def get_geometry(self, rots, trans, intrins, post_rots, post_trans):"""Determine the (x,y,z) locations (in the ego frame)of the points in the point cloud.Returns B x N x D x H/downsample x W/downsample x 3"""B, N, _ = trans.shape# undo post-transformation# B x N x D x H x W x 3# post_trans和post_rots为图像增强中使用到的仿射变换参数,因为此处要对视锥中的对应点做同样变换points = self.frustum - post_trans.view(B, N, 1, 1, 1, 3)points = torch.inverse(post_rots).view(B, N, 1, 1, 1, 3, 3).matmul(points.unsqueeze(-1))# cam_to_ego 像素坐标系->相机坐标系->车身坐标系points = torch.cat((points[:, :, :, :, :, :2] * points[:, :, :, :, :, 2:3],points[:, :, :, :, :, 2:3]), 5)combine = rots.matmul(torch.inverse(intrins))points = combine.view(B, N, 1, 1, 1, 3, 3).matmul(points).squeeze(-1)points += trans.view(B, N, 1, 1, 1, 3)# 得到原先2D的坐标点的位置在车身坐标系下的3D位置return points生成3D转为BEV图,示例代码:
def voxel_pooling(self, geom_feats, x):B, N, D, H, W, C = x.shapeNprime = B*N*D*H*W# flatten xx = x.reshape(Nprime, C)# flatten indicesgeom_feats = ((geom_feats - (self.bx - self.dx/2.)) / self.dx).long()geom_feats = geom_feats.view(Nprime, 3)batch_ix = torch.cat([torch.full([Nprime//B, 1], ix,device=x.device, dtype=torch.long) for ix in range(B)])geom_feats = torch.cat((geom_feats, batch_ix), 1)# filter out points that are outside boxkept = (geom_feats[:, 0] >= 0) & (geom_feats[:, 0] < self.nx[0])\& (geom_feats[:, 1] >= 0) & (geom_feats[:, 1] < self.nx[1])\& (geom_feats[:, 2] >= 0) & (geom_feats[:, 2] < self.nx[2])x = x[kept]geom_feats = geom_feats[kept]# get tensors from the same voxel next to each other# 将所有的feature基于坐标位置进行排序,在俯视图上相同坐标的feature的ranks值相同ranks = geom_feats[:, 0] * (self.nx[1] * self.nx[2] * B)\+ geom_feats[:, 1] * (self.nx[2] * B)\+ geom_feats[:, 2] * B\+ geom_feats[:, 3]sorts = ranks.argsort()x, geom_feats, ranks = x[sorts], geom_feats[sorts], ranks[sorts]# cumsum trickif not self.use_quickcumsum:x, geom_feats = cumsum_trick(x, geom_feats, ranks)else:x, geom_feats = QuickCumsum.apply(x, geom_feats, ranks)# griddify (B x C x Z x X x Y)final = torch.zeros((B, C, self.nx[2], self.nx[0], self.nx[1]), device=x.device)final[geom_feats[:, 3], :, geom_feats[:, 2], geom_feats[:, 0], geom_feats[:, 1]] = x# collapse Zfinal = torch.cat(final.unbind(dim=2), 1)return finaldef cumsum_trick(x, geom_feats, ranks):x = x.cumsum(0)kept = torch.ones(x.shape[0], device=x.device, dtype=torch.bool)kept[:-1] = (ranks[1:] != ranks[:-1])x, geom_feats = x[kept], geom_feats[kept]# 获得同一坐标的所有feature的sumx = torch.cat((x[:1], x[1:] - x[:-1]))return x, geom_feats参考文章:
Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D - 知乎
BEV感知系列:LSS-Lift, Splat, Shoot(论文+代码) - 知乎
[paper] lift,splat,shooting 论文浅析_pillar pooling-CSDN博客
三、Shooting 执行任务
Lift-Splat已经输出了由N个相机图像编码的BEV features,接下来就是再接上Head来实现特定的任务,这部分由Shoot来实现。
Shooting是指在BEV特征图上进行相关任务操作,比如检测、分割、轨迹预测等。
LSS在Shooting部分实现端到端的运动规划。
总结
LSS全称是Lift-Splat-Shoot,它先从车辆周围的多个摄像头拍摄到的图像进行特征提取,在特征图中估计出每个点的深度,然后把这些点“提升”到3D空间中。
接着,这些3D信息被放置到一个网格上,最后将这些信息“拍扁”到一个平面视图上,形成BEV特征图。
- Lift,是提升的意思,2D → 3D特征转换模块,将二维图像特征生成3D特征,涉及到深度估计。
- Splat,是展开的意思,3D → BEV特征编码模块,把3D特征“拍扁”得到BEV特征图。
- Shooting,是指在BEV特征图上进行相关任务操作,比如检测、分割、轨迹预测等。
在3D世界中,要确定一个对象的确切位置,仅有2D像素坐标是不够的。我们还需要知道这个像素点距离相机的深度(即它有多远)。
在没有深度相机这类设备的情况下,LSS系统通过为每个像素点生成一系列可能的深度值来估计深度信息,简称为“深度离散预估”。
一旦我们通过 "Lift" 步骤获得了2D像素点的深度信息,结合这个点的2D像素坐标、相机的内部参数(内参),以及相机相对于车辆的位置和方向(外参),我们就可以计算出该像素点在车辆坐标系中的3D坐标。
接着,系统将这些3D坐标投影到一个统一的BEV图中。
分享完成~
这篇关于【BEV感知 LSS方案】Lift-Splat-Shoot(LSS)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






