本文主要是介绍【目标检测实验系列】YOLOv5模型改进:融合混合注意力机制CBAM,关注通道和空间特征,助力模型高效涨点!(内含源代码,超详细改进代码流程),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
自我介绍:本人硕士期间全程放养,目前成果:一篇北大核心CSCD录用,两篇中科院三区已见刊,一篇中科院四区在投。如何找创新点,如何放养过程厚积薄发,如何写中英论文,找期刊等等。本人后续会以自己实战经验详细写出来,还请大家能够点个关注和赞,收藏一下,谢谢大家。
1. 文章主要内容
本篇博客主要涉及混合(通道角度与空间角度)注意力机制CBAM融合到YOLOv5模型中。(通读本篇博客需要7分钟左右的时间)。
2. 详细代码改进流程
2.1 CBAM源代码(大家自己创建CBAM.py文件)
注意,博主在CBAM源码当中添加了C3与CBAM结合的代码,还有main函数的测试案例,不影响CBAM的单独使用。
import numpy as np
import torch
from torch import nn
from torch.nn import initfrom models.common import Bottleneck, Convclass ChannelAttention(nn.Module):def __init__(self, channel, reduction=16):super().__init__()self.maxpool = nn.AdaptiveMaxPool2d(1)self.avgpool = nn.AdaptiveAvgPool2d(1)self.se = nn.Sequential(nn.Conv2d(channel, channel // reduction, 1, bias=False),nn.ReLU(),nn.Conv2d(channel // reduction, channel, 1, bias=False))self.sigmoid = nn.Sigmoid()def forward(self, x):max_result = self.maxpool(x)avg_result = self.avgpool(x)max_out = self.se(max_result)avg_out = self.se(avg_result)output = self.sigmoid(max_out + avg_out)return outputclass SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super().__init__()self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size // 2)self.sigmoid = nn.Sigmoid()def forward(self, x):max_result, _ = torch.max(x, dim=1, keepdim=True)avg_result = torch.mean(x, dim=1, keepdim=True)result = torch.cat([max_result, avg_result], 1)output = self.conv(result)output = self.sigmoid(output)return outputclass CBAMBlock(nn.Module):def __init__(self, channel=512, reduction=16, kernel_size=7):super().__init__()self.ca = ChannelAttention(channel=channel, reduction=reduction)self.sa = SpatialAttention(kernel_size=kernel_size)def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):b, c, _, _ = x.size()out = x * self.ca(x)out = out * self.sa(out)return outclass C3CBAM(nn.Module):def __init__(self, c1, c2, n=1, shortcut=True, g=1,e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion #iscyysuper(C3CBAM, self).__init__()c_ = int(c2 * e) # hidden channelsself.cbam = CBAMBlock(c1)self.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)# self.m = nn.Sequential(*[CB2d(c_) for _ in range(n)])self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])def forward(self, x):out = torch.cat((self.m(self.cv1(self.cbam(x))), self.cv2(self.cbam(x))), dim=1)out = self.cv3(out)return outif __name__ == '__main__':input = torch.randn(50, 512, 7, 7)cbam = C3CBAM(512, 512)output = cbam(input)print(output.shape)需要注意到: 源代码CBAMBlock类只需要传入一个输入的通道数channel,与YOLOv5的C3结构融合后,则C3CBAM需要传入输入和输出通道数,但大家仔细发现在C3CBAM的这行代码self.cbam =CBAMBlock(c1),实际的CBAM也只是需要传入输入的通道数即可。大家可以通过main函数进行测试。另外,在C3CBAM中,其中cv1和cv2方法里面的参数x都先通过了cbam注意力机制,这里大家可以自定义的设置。
2.2 建立一个yolov5-cbam.yaml文件
注意到,这里博主直接使用C3CBAM代替Backbone部分的四个C3结构,另外注意nc改为自己数据集的类别数。当然,CBAM结构可以自由的放到网络当中的任何结构,但需要特别注意放了之后层次的更替问题,如有不懂,可以查看我之前写的一篇博客(以及评论区注意点):【目标检测实验系列】通过全局上下文注意力机制Global Context Block(GC)融合到YOLOv5案例,吃透简单即插即用注意力机制代码修改要点,举一反三!(超详细改进代码流程)
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 4 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8 小目标- [30,61, 62,45, 59,119] # P4/16 中目标- [116,90, 156,198, 373,326] # P5/32 大目标# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2 output_channel, kernel_size, stride, padding[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3CBAM, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3CBAM, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3CBAM, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3CBAM, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]3.3 将C3CBAM引入到yolo.py文件中
在下图的位置处,引入相关的类即可。
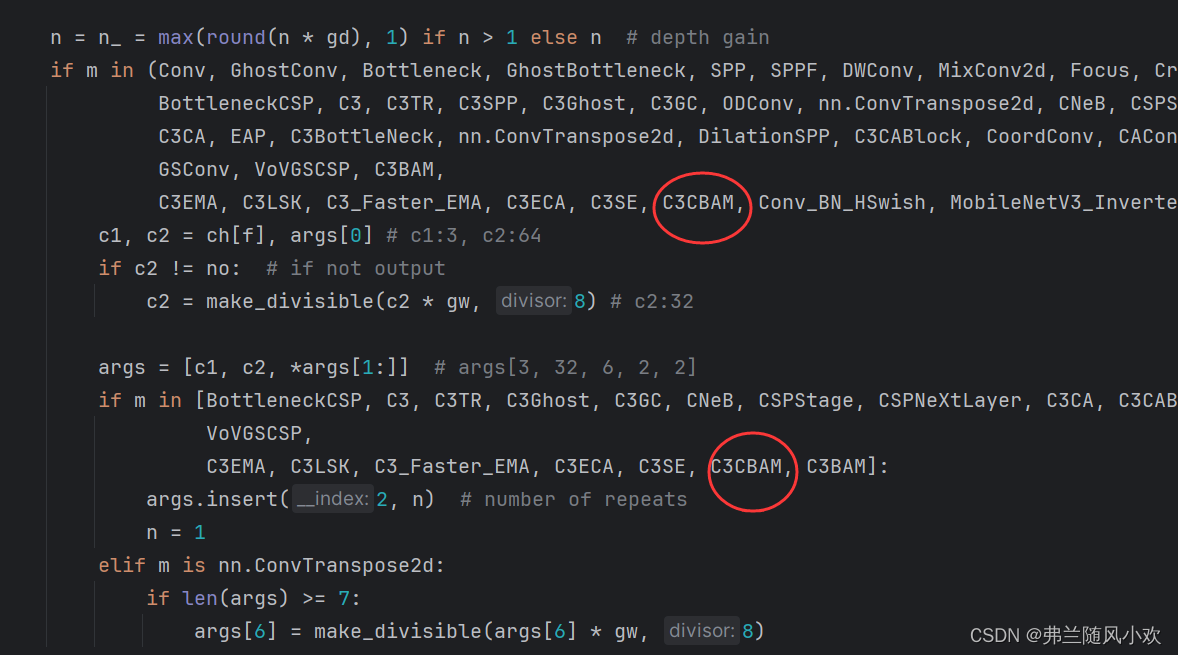
3.4 修改train.py启动文件
修改配置文件为yolov5-cbam.yaml即可,如下图所示:
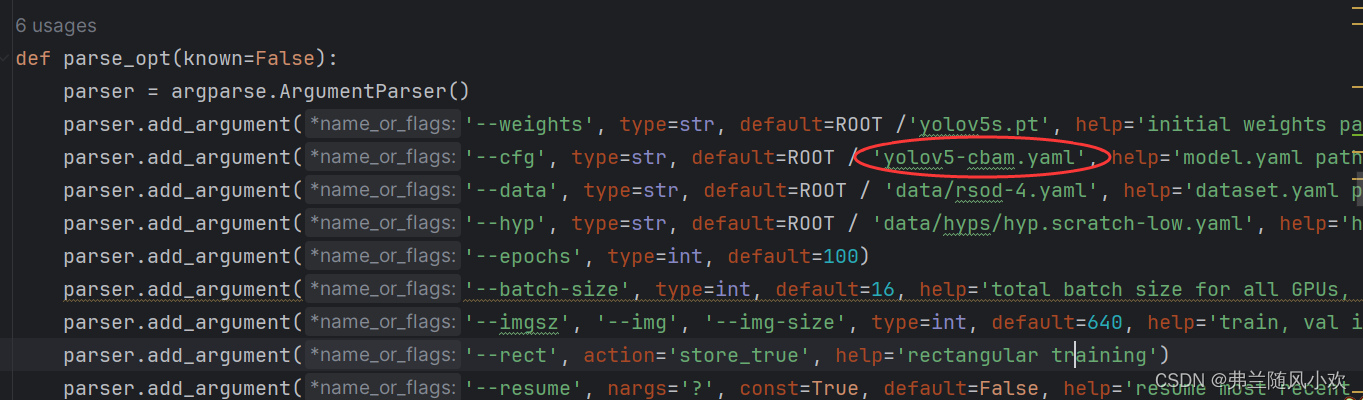
4. 总结
本篇博客主要介绍了CBAM融合到YOLOv5模型,通过关注通道和空间特征,助力模型高效涨点。另外,在修改过程中,要是有任何问题,评论区交流;如果博客对您有帮助,请帮忙点个赞,收藏一下;后续会持续更新本人实验当中觉得有用的点子,如果很感兴趣的话,可以关注一下,谢谢大家啦!
这篇关于【目标检测实验系列】YOLOv5模型改进:融合混合注意力机制CBAM,关注通道和空间特征,助力模型高效涨点!(内含源代码,超详细改进代码流程)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







