涨点专题

爆改YOLOv8|利用SCConv改进yolov8-即轻量又涨点
1,本文介绍 SCConv(空间和通道重构卷积)是一种高效的卷积模块,旨在优化卷积神经网络(CNN)的性能,通过减少空间和通道的冗余来降低计算资源的消耗。该模块由两个核心组件构成: 空间重构单元(SRU):通过分离和重构的方式,SRU 有效减少空间冗余。 通道重构单元(CRU):利用分割-变换-融合策略,CRU 旨在降低通道冗余 关于SCConv的详细介绍可以看论文:SCConv: S

YoloV10改进策略:下采样改进|自研下采样模块(独家改进)|疯狂涨点|附结构图
文章目录 摘要自研下采样模块及其变种第一种改进方法 YoloV10官方测试结果改进方法测试结果总结 摘要 本文介绍我自研的下采样模块。本次改进的下采样模块是一种通用的改进方法,你可以用分类任务的主干网络中,也可以用在分割和超分的任务中。已经有粉丝用来改进ConvNext模型,取得了非常好的效果,配合一些其他的改进,发一篇CVPR、ECCV之类的顶会完全没有问题。 本次我将这个模

YOLOv8改进实战 | 注意力篇 | 引入基于跨空间学习的高效多尺度注意力EMA,小目标涨点明显
YOLOv8专栏导航:点击此处跳转 前言 YOLOv8 是由 YOLOv5 的发布者 Ultralytics 发布的最新版本的 YOLO。它可用于对象检测、分割、分类任务以及大型数据集的学习,并且可以在包括 CPU 和 GPU 在内的各种硬件上执行。 YOLOv8 是一种尖端的、最先进的 (SOTA) 模型,它建立在以前成功的 YOLO 版本的基础上,并引入了新的功能和改进

爆改YOLOv8|利用yolov10的PSA注意力机制改进yolov8-高效涨点
1,本文介绍 PSA是一种改进的自注意力机制,旨在提升模型的效率和准确性。传统的自注意力机制需要计算所有位置对之间的注意力,这会导致计算复杂度高和训练时间长。PSA通过引入极化因子来减少需要计算的注意力对的数量,从而降低计算负担。极化因子是一个向量,通过与每个位置的向量点积,确定哪些位置需要计算注意力。这种方法可以在保持模型准确度的前提下,显著减少计算量,从而提升自注意力机制的效率。 关于PS

YOLOv10涨点改进轻量化双卷积DualConv,完成涨点且计算量和参数量显著下降
本文独家改进:双卷积由组卷积和异构卷积组成,执行3x3 和 1x1 卷积运算Q代替其他卷积核仅执行 1x1 卷积。 DualIConv 显着降低了深度神经网络的计算成本和参数数量,同时在某些情况下令人惊讶地实现了比原始模型略高的精度。 我们使用 DualConv 将轻量级 MobileNetV2 的参数数量进一步减少了 54% 目录 1)替换原始的Conv 2,YOLOv10介绍 1.1

YOLOv10涨点改进:改进检测头(Partial_C_v10Detect)检测头结构创新,实现涨点
目录 1,YOLOv10介绍 1.1 C2fUIB介绍 1.2 PSA介绍 1.3 SCDown 1.Partial C v10Detect原理介绍 1.1 Partial Convolution 3.v10Detect二次创新引入到yolov10 3.1 修改ultralytics/nn/modules/head.py 第一处修改:PConv加入以下代码 1,

YOLOv10独家涨点改进:轻量化双卷积DualConv,有效减少参数和涨点
目录 1 C2fUIB介绍 2.DualConv原理 3.如何将Dualconv将入到YOLOv10 3.1 新建ultralytics/nn/Conv/DualConv.py 3.2 注册ultralytics/nn/tasks.py 论文 https://arxiv.org/pdf/2405.14458 代码 GitHub - THU-MIG/yolov10: YO

【YOLOv10轻量级涨点改进:block优化 | 华为诺亚2023极简的神经网络模型 VanillaNet】
本文属于原创独家改进:一种极简的神经网络模型VanillaNet,以极简主义的设计为理念,网络中仅仅包含最简单的卷积计算,去掉了残差和注意力模块 计算量参数量比较,8.4 GFLOPs降低至6.1 GFLOPs YOLOv10n summary: 385 layers, 2709380 parameters, 2709364 gradients, 8.4 GFLOPsYOLOv10n-Van
YOLOv10涨点改进|引入BoTNet结构与CA注意力机制,打造高效轻量级检测器
📚 专栏地址:《YOLOv10算法改进实战》 👉 独家改进,对现有YOLOv10进行二次创新,提升检测精度,适合科研创新度十足,强烈推荐 🌟 统一使用 YOLOv10 代码框架,结合不同模块来构建不同的YOLO目标检测模型。 💥 本博客包含大量的改进方式,降低改进难度,改进点包含【Backbone特征主干】、【Neck特征融合】、【Head检测头】、【注意力机制】、【IoU损失函数
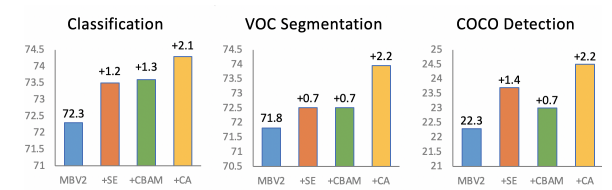
【CNN】——涨点模块SE,CBAM,CA对比
code:https://github.com/chenjun2hao/dler.collection 涨点模块的对比 对比测试 SE通道注意力CBAM通道注意+空间注意力Coordinate Attention,个人认为是一种通道注意力+x方向空间+y方向空间注意力机制。其思路很像Strip Pooling 1. 参数对比 这里采用同样的输入,同样的输入,输出通道,同样的中间过渡
![【YOLOv8改进[CONV]】使用MSBlock二次创新C2f模块实现轻量化 + 含全部代码和详细修改方式 + 手撕结构图 + 轻量化 + 涨点](https://img-blog.csdnimg.cn/direct/8d649bf7673c4feb8ee5a9aecf11c909.png)
【YOLOv8改进[CONV]】使用MSBlock二次创新C2f模块实现轻量化 + 含全部代码和详细修改方式 + 手撕结构图 + 轻量化 + 涨点
本文将使用MSBlock二次创新C2f模块实现轻量化,助力YOLOv8目标检测效果的实践,文中含全部代码、详细修改方式以及手撕结构图。助您轻松理解改进的方法,实现有效涨点。 改进前和改进后的参数对比: 目录 一 MSBlock 二 使用MSBlock二次创新C2f模块实现轻量化 1 整体修改 ① 添加C2f_MSBlock.py文件 ② 修改ultralytics/nn/task

YOLOv10涨点改进:原创自研 | GhostNet融合 | 从廉价的操作中生成更多的特征图
文章目录 GhostNet理论基础实验部分 改进方案新增yolov10s-ghost.yaml文件代码运行 GhostNet理论基础 Ghost Module是一种模型压缩的方法,即在保证网络精度的同时减少网络参数和计算量,从而提升计算速度(speed),降低延时(latency)。Ghost 模块可以代替现有卷积网络中的每一个卷积层。基于Ghost模块,论文作者堆叠Ghos
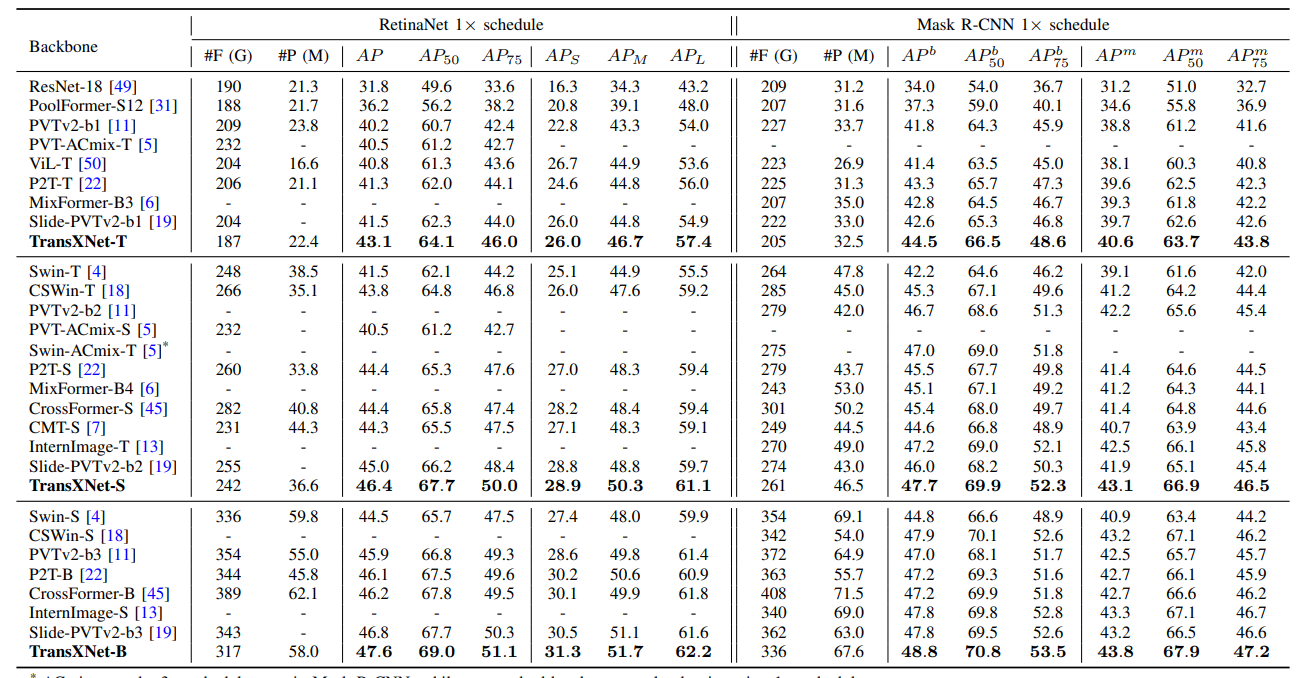
涨点神器!全局注意力+位置注意力,打造更强深度学习模型
全局注意力结合位置注意力是学术界与工业界共同的研究热点,它可以有效提升深度学习模型的性能,助力涨点。 这种结合策略充分利用全局注意力(擅长捕捉序列或图像中的长距离依赖)和位置注意力(专注于序列中元素的具体位置)各自的优势,让模型在处理数据时同时考虑元素的内容及其在序列中的位置。这不仅提高了模型的表达能力,还能在保持计算效率的同时增强模型对复杂模式的理解和预测能力。 比如全局位置自注意力网络GP
【YOLOv8改进[Conv]】使用YOLOv9中的Adown模块改进Conv模块的实践 + 含全部代码和修改方式 + 有效涨点
本文中进行使用YOLOv9中的Adown模块改进Conv模块的实践 ,文中包含全部代码和修改方式 ,有效涨点。 目录 一 YOLOv9 1 信息丢失问题 2 PGI ① 信息瓶颈 ② 可逆函数<

YoloV8改进策略:蒸馏改进|MimicLoss|使用蒸馏模型实现YoloV8无损涨点|特征蒸馏
摘要 在本文中,我们成功应用蒸馏策略以实现YoloV8小模型的无损性能提升。我们采用了MimicLoss作为蒸馏方法的核心,通过对比在线和离线两种蒸馏方式,我们发现离线蒸馏在效果上更为出色。因此,为了方便广大读者和研究者应用,本文所描述的蒸馏方法仅保留了离线蒸馏方案。此外,我们还提供了相关论文的译文,旨在帮助大家更深入地理解蒸馏方法的原理和应用。 YOLOv8n summary (fused)

最新Adaptive特征融合策略,涨点又高效,想发表论文可以参考
自适应特征融合是一种非常高效的数据处理方法,它比传统的特征更能适应不同的数据和任务需求,也因此拥有广泛的应用前景,是深度学习领域的研究热点。 这种方法通过动态选择和整合来自不同层次或尺度的特征信息,不仅显著提升了模型性能,实现了快速涨点的效果,还优化了特征的使用效率,帮助我们加快实验迭代的速度。 尤其是ASFF方法,ASFF通过学习每个空间位置上不同层级特征的重要程度,自适应地过滤掉携带矛盾信
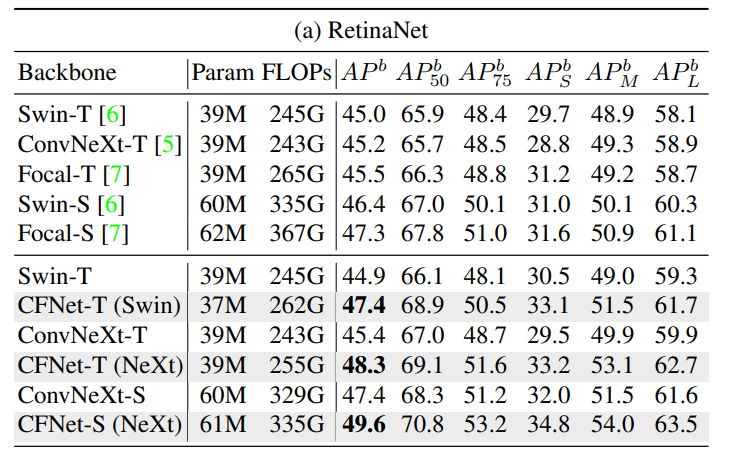
涨点神器:即插即用特征融合模块!超低参数,性能依旧SOTA
在写论文时,一些通用性模块可以在不同的网络结构中重复使用,这简化了模型设计的过程,帮助我们加快了实验的迭代速度。 比如在视觉任务中,即插即用的特征融合模块可以无缝集成到现有网络中,以灵活、简单的方式提升神经网络的性能。这类模块通过专注于数据的关键点和模式,帮助模型更有效地学习特征,从而提高在各种视觉任务中的准确度和效率。 以南航提出的AFF模块、港大等提出的即插即用轻量级模块AdaptForm

YOLOv9全网最新改进系列::YOLOv9完美融合双卷积核(DualConv)来构建轻量级深度神经网络,目标检测模型有效涨点神器!!!
YOLOv9全网最新改进系列::YOLOv9完美融合双卷积核(DualConv)来构建轻量级深度神经网络,目标检测模型有效涨点神器!!! YOLOv9原文链接戳这里,原文全文翻译请关注B站Ai学术叫叫首er B站全文戳这里! 详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先! YOLOv9全网最新改进系
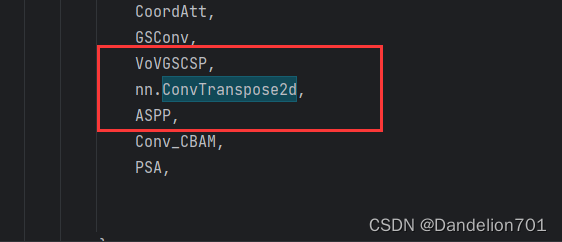
YOLOV5更换转置卷积,助力涨点!
由于转置卷积是nn库自带的,所以我们直接找到models文件夹中的yolo.py文件中的 parse_model函数,再在如下图的地方添加转置卷积模块 # YOLOv5 🚀 by Ultralytics, AGPL-3.0 license"""YOLO-specific modules.Usage:$ python models/yolo.py --cfg yolov5s.yam

YOLOV5中加入CA注意力机制,助力涨点!
首先找到models文件夹中的common.py文件,加入如下模块 #########CA###############class h_sigmoid(nn.Module):def __init__(self, inplace=True):super(h_sigmoid, self).__init__()self.relu = nn.ReLU6(inplace=inplace)def f


YOLOv8优改系列二:YOLOv8融合ATSS标签分配策略,实现网络快速涨点
💥 💥💥 💥💥 💥💥 💥💥神经网络专栏改进完整目录:点击 💗 只需订阅一个专栏即可享用所有网络改进内容,每周定时更新 文章内容:针对YOLOv8的Neck部分融合ATSS标签分配策略,实现网络快速涨点!!! 推荐指数(满分五星):⭐️⭐️⭐️⭐️⭐️ 涨点指数(满分五星):⭐️⭐️⭐️⭐️⭐️ ✨目录 一、ATSS介绍二、核心代码修改2.1 修改loss文件2.2
YoloV7改进策略:下采样改进|自研下采样模块(独家改进)|疯狂涨点|附结构图
摘要 本文介绍我自研的下采样模块。本次改进的下采样模块是一种通用的改进方法,你可以用分类任务的主干网络中,也可以用在分割和超分的任务中。已经有粉丝用来改进ConvNext模型,取得了非常好的效果,配合一些其他的改进,发一篇CVPR、ECCV之类的顶会完全没有问题。 本次我将这个模块用来改进YoloV7,实现大幅度涨点。 自研下采样模块及其变种 第一种改进方法 将输入分成两个分支,一个分支

YOLOv9改进策略 | 添加注意力篇 | LSKAttention大核注意力机制助力极限涨点 (附多个位置添加教程)
一、本文介绍 本文给大家带来的改进机制是LSKAttention大核注意力机制应用于YOLOv9。它的主要思想是将深度卷积层的2D卷积核分解为水平和垂直1D卷积核,减少了计算复杂性和内存占用。接着,我们介绍将这一机制整合到YOLOv9的方法,以及它如何帮助提高处理大型数据集和复杂视觉任务的效率和准确性。本文还将提供代码实现细节和使用方法,展示这种改进对目标检测等方面的效果。通过实验YOLOv
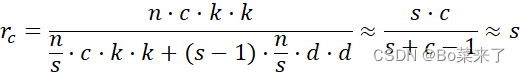
即插即用的涨点模块之变体卷积(Ghost卷积)详解及代码,可应用于检测、分割、分类等各种算法领域
目录 前言 一、GhostConv结构 二、GhostConv计算流程 三、GhostConv参数 四、代码详解 前言 GhostNet: More Features from Cheap Operations 来源:CVPR2020 官方代码:https://github.com/huawei-noah/ghostnet Ghost 模块是一种针对卷积神经

YOLOv9改进策略 | 添加注意力篇 | 挤压和激励单元SENetV2助力YOLOv9细节涨点(全网独家首发)
一、本文介绍 本文给大家带来的改进机制是SENetV2,其是一种通过调整卷积网络中的通道关系来提升性能的网络结构。SENet并不是一个独立的网络模型,而是一个可以和现有的任何一个模型相结合的模块(可以看作是一种通道型的注意力机制但是相对于SENetV1来说V2又在全局的角度进行了考虑)。在SENet中,所谓的挤压和激励(Squeeze-and-Excitation)操作是作为一个单元添加到传