本文主要是介绍【2021-CVPR-3D人体姿态估计】Graph Stacked Hourglass Networks for 3D Human Pose Estimation,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Graph Stacked Hourglass Networks for 3D Human Pose Estimation
题目:《用于3D人体姿态的图堆叠沙漏网络》
作者:

来源:CVPR 2021
研究内容:
单人-单视图-有监督
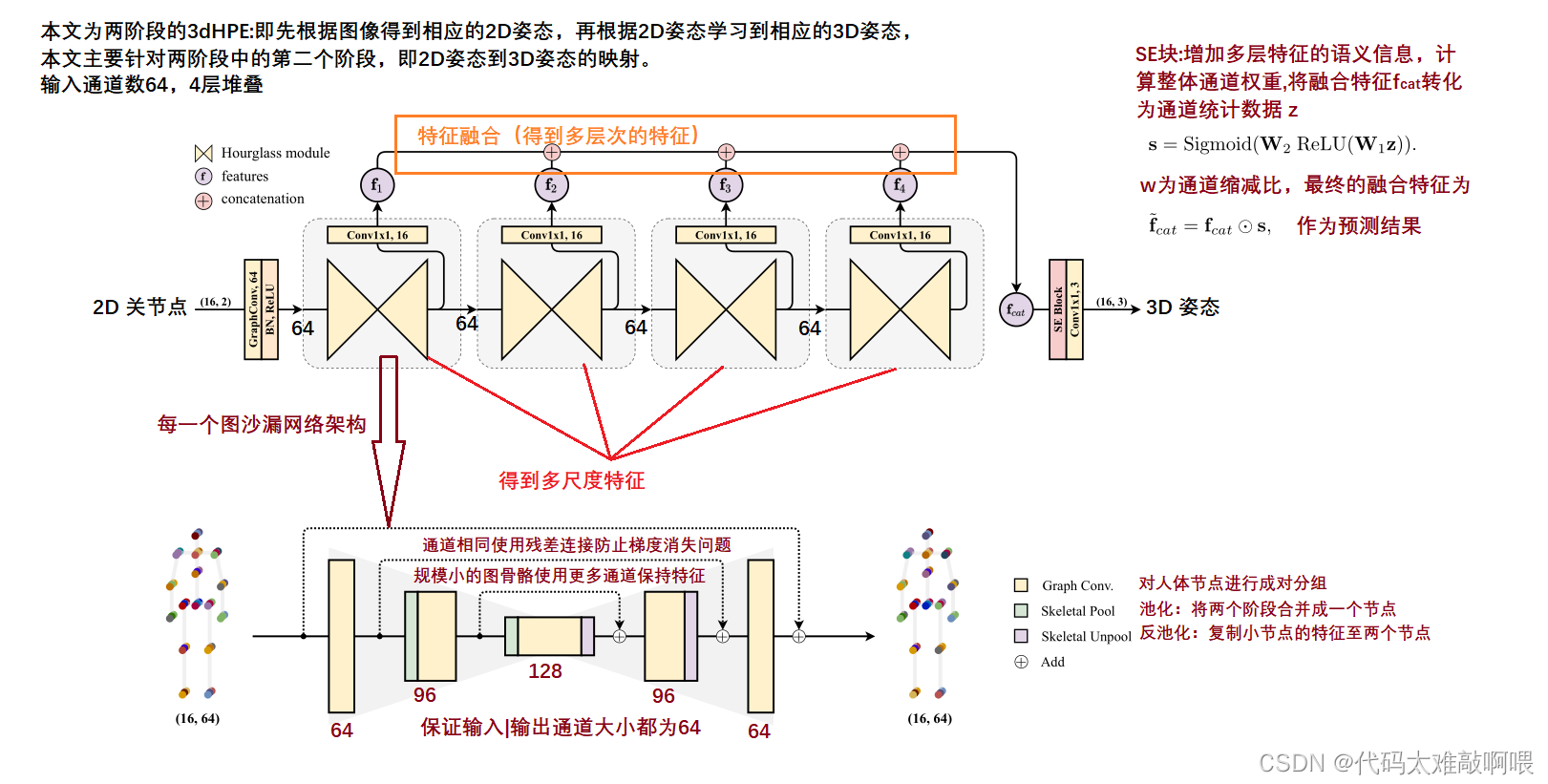
创新点:
•提出适用于多尺度人体骨骼特征提取的Graph Hourglass模块,包括考虑人体骨骼结构的新型池化和解池操作——骨骼池化和骨骼Unpool(反池化)
•其次,我们引入了图堆叠沙漏网络(Graph Stacked Hourglass Networks, GraphSH),由提出的图沙漏模块组成,该模块在架构的不同深度包含多层次的特征表示。
现有技术:
图卷积(只能在一个单一尺度上对特征进行处理,难以提取表征空间的局部和全局空间信息,限制了模型的表征能力,没有利用模型的深度特点)。
通常对于图像特征提取,分为

由于图结构的不规范性,其不能直接使用图像特征提取的方法,本文提出图堆叠沙漏网络、改为适用于图结构模型的
因人体骨架的拓扑结构特点,可以被视为图结构,因此越来越多的实验选用图卷积(GCN)
(本文中“图堆叠网络”的“堆叠”是指重复提取特征,以此提高模型性能)
数据集:
Human3.6M数据集是在三维人体姿态估计任务中使用最广泛的数据集。它利用运动捕捉获取被测对象的三维姿态信息,并通过4个不同方向的摄像机记录相应的视频图像信息。根据所提供的摄像机参数,我得到每一帧图像中对应的2D联合坐标的ground truth。该数据集通过记录11名专业演员表演的15种不同动作,如吃饭、走路等,提供了360万张图像。本实验中,主要使用Human3.6M进行训练和测试。其评价指标为:MPJPE协议1和MPJPE协议2。
MPI-INF-3DHP测试集提供了三种不同场景的图像:有绿屏的工作室(GS)、没有绿屏的工作室(noGS)和户外场景(outdoor)。本文使用这个数据集来测试网络的泛化性能。其评价指标为:3DPCK和AUC。
这篇关于【2021-CVPR-3D人体姿态估计】Graph Stacked Hourglass Networks for 3D Human Pose Estimation的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









