本文主要是介绍【点云处理之狂读论文经典篇2】——Multi-view Convolutional Neural Networks for 3D Shape Recognition,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MVCNN:一种用于3D形状识别的多视图卷积神经网络
- 摘要
- 1. 引言
- 2. 相关工作
- 3. 方法
- 3.1 Input: A Multi-view Representation
- 3.2 Recognition with Multi-view Representations
- 3.3 Multi-view CNN: Learning to Aggregate Views
- 4. 实验
- 4.1 3D Shape Classification and Retrieval
- 4.2 Sketch Recognition: Jittering Revisited
- 4.3 Sketch-based 3D Shape Retrieval
- 5. 结论
- 论文写作亮点
摘要
- 本文通过一组视角投影下的2D渲染图来学习识别3D形状。
- 首先提出一个标准的CNN架构用于独立训练3D形状的渲染图,实验结果表明,单张渲染图的的识别效果已经很好了。
- 增加渲染图的数量,识别效果会更好。
- 还提出了一个新的CNN框架,能够结合3D形状的多个视角图为一个紧凑的特征向量,识别效果更好。
- 相同的框架可以被用于识别人画的形状轮廓。
- 代码详见http://vis-www.cs.umass.edu/mvcnn.
1. 引言
- 本文以3D ShapeNets为基础,探究非体素表示的方法。
- 本文使用的多视图的处理方法效果要比直接处理3D形状好太多了,这是因为用2D表示的方法要比3D更加高效。
- 体素表示方法在处理的过程中耗时长、占用内存大、分辨率低、几何信息损失严重。
- 可以用于classification和retrieval。
- 在将3D形状投影为2D图像后,可以对2D图像进行数据增强,实验效果更好。
2. 相关工作
特征提取器
- 3D表示方法:polygon meshes, voxel-based discretizations, point clouds, or implicit surfaces
- 多视图表示方法
- 传统3D表示方法:histograms or bag-of-features(surface normals and curvatures [15], distances, angles, triangle areas or tetrahedra volumes gathered at sampled surface points [25], properties of spherical functions defined in volumetric grids [16], local shape diameters measured at densely sampled surface points [4], heat kernel signatures on polygon meshes [2, 19], or extensions of the SIFT and SURF feature descriptors to 3D voxel grids [17].)
- 传统多视图表示方法:若干
CNN
与本文最相近的工作是对两个拼接的视图作为输入。而本文是以多个视图为输入聚合信息特征,不需要排序,输出的是一个紧凑的特征,利用图像和3D形状进行训练。
大多数的方法都是通过比较、拼接多个视图的特征进行处理,而本文是通过view-pooling layer聚合特征的。
3. 方法
本文的核心思想就是开发一个基于视图的3D形状特征提取方法,得到一个可训练、信息丰富的3D形状表示,可以在recognition 和 retrieval任务中进行应用。
简单地对每个视图进行单独处理,或者是拼接处理很不科学,需要找到一种可以处理多个视图特征的方法。本文使用了包含view-pooling layer的通用CNN从多个视角图中结合信息。
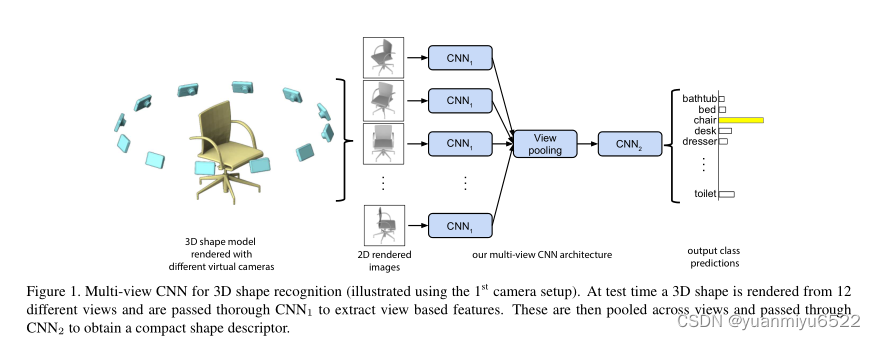
3.1 Input: A Multi-view Representation
使用Phong reflection model[27]生成polygon mesh形状(顶点)的视角图。
视点(虚拟相机位置)的选择很重要,本文有两种配置方法:
- 假设3D形状垂直放置,围绕着mesh,每30°放置一个虚拟相机,共12个位置,相机指向3D形状的质心。
- 假设3D形状的方向未知,那就用更多的图片去覆盖3D形状的表面。通过在包围形状的二十面体的20个顶点处放置20个虚拟相机生成视角图,所有的相机都指向形状的质心。每个相机从4个视角拍摄图片,分别以通过质心和相机的直线为轴旋转0°,90°,180°和270°,共生成80张图片。
生成视角图所耗费的时间很少。
3.2 Recognition with Multi-view Representations
在本小节中,直接使用现有的特征提取方法分别对每个视图进行特征提取,然后将这些特征进行整合。
- Hand-crafted descriptors(Fisher vectors with multi-scale SIFT)——PCA + Gaussian kernel升维
- CNN activation features(VGG-M)——pre-trained + fine-tuned
Classification
使用one-vs-rest线性SVM,在得到12视图的结果后,进行相加,取最高的结果。
Retrieval
多对多的特征相似性计算:
d ( x , y ) = ∑ j min i ∥ x i − y j ∥ 2 2 n y + ∑ i min j ∥ x i − y j ∥ 2 2 n x d(\mathbf{x}, \mathbf{y})=\frac{\sum_{j} \min _{i}\left\|\mathbf{x}_{i}-\mathbf{y}_{j}\right\|_{2}}{2 n_{y}}+\frac{\sum_{i} \min _{j}\left\|\mathbf{x}_{i}-\mathbf{y}_{j}\right\|_{2}}{2 n_{x}} d(x,y)=2ny∑jmini∥xi−yj∥2+2nx∑iminj∥xi−yj∥2
其中,形状 x \mathbf{x} x有 n x n_{x} nx个图像特征,形状 y \mathbf{y} y有 n y n_{y} ny个图像特征。特征之间的距离用 ℓ 2 \ell_{2} ℓ2计算, i.e. ∥ x i − y j ∥ 2 \left\|\mathbf{x}_{i}-\mathbf{y}_{j}\right\|_{2} ∥xi−yj∥2。
- 首先计算一个2D图像特征 x i \mathbf{x}_{i} xi和 y \mathbf{y} y的最短距离 d ( x i , y ) = min j ∥ x i − y j ∥ 2 d\left(\mathbf{x}_{i}, \mathbf{y}\right)=\min _{j}\left\|\mathbf{x}_{i}-\mathbf{y}_{j}\right\|_{2} d(xi,y)=minj∥xi−yj∥2
- 然后给出所有2D图像 x i \mathbf{x}_{i} xi到 y \mathbf{y} y的距离 ∑ \sum ∑
- 最后取平均值
- 使用双向保证对称性
3.3 Multi-view CNN: Learning to Aggregate Views
上一节中使用的聚合方法不方便,效率也不高。在本节中,要找到一种既综合所有视图的特征信息又紧凑的表示形式。
Multi-view CNN(MVCNN)
如图1所示:
- 多视图分别进入网络的第一部分CNN 1 _1 1,CNN 1 _1 1所有分支的参数相同,
- 再在view-pooling layer进行聚合,该层取元素最大化操作(注意取最大值的维度与最大池化不一样),这个层可以放在主干网络的任意位置。但是,通过实验证明,放在第5层效果最好。
- 最后通过网络的剩余部分CNN 2 _2 2
这样性能佳,速度快。
Low-rank Mahalanobis metric
主要是针对Retrieval任务。训练一个权重 W W W ,可以将原先的特征向量 ϕ ∈ R d \phi \in \mathbb{R}^{d} ϕ∈Rd投影到 W ϕ ∈ R p W \phi \in \mathbb{R}^{p} Wϕ∈Rp空间中,其中 p < d p<d p<d,便于计算特征间的 ℓ 2 \ell_{2} ℓ2距离,实验中 p = 128 p=128 p=128。
4. 实验
4.1 3D Shape Classification and Retrieval
数据集:ModelNet,包含127,915和3D模型,属于662个类别。其中40个类别已经被标注好了,包含12,311个形状,训练集和测试集的划分与3D ShapeNet保持一致。
对比方法:
- 3D ShapeNets
- pherical Harmonics descriptor (SPH)
- LightField descriptor (LFD)
- Fisher vectors
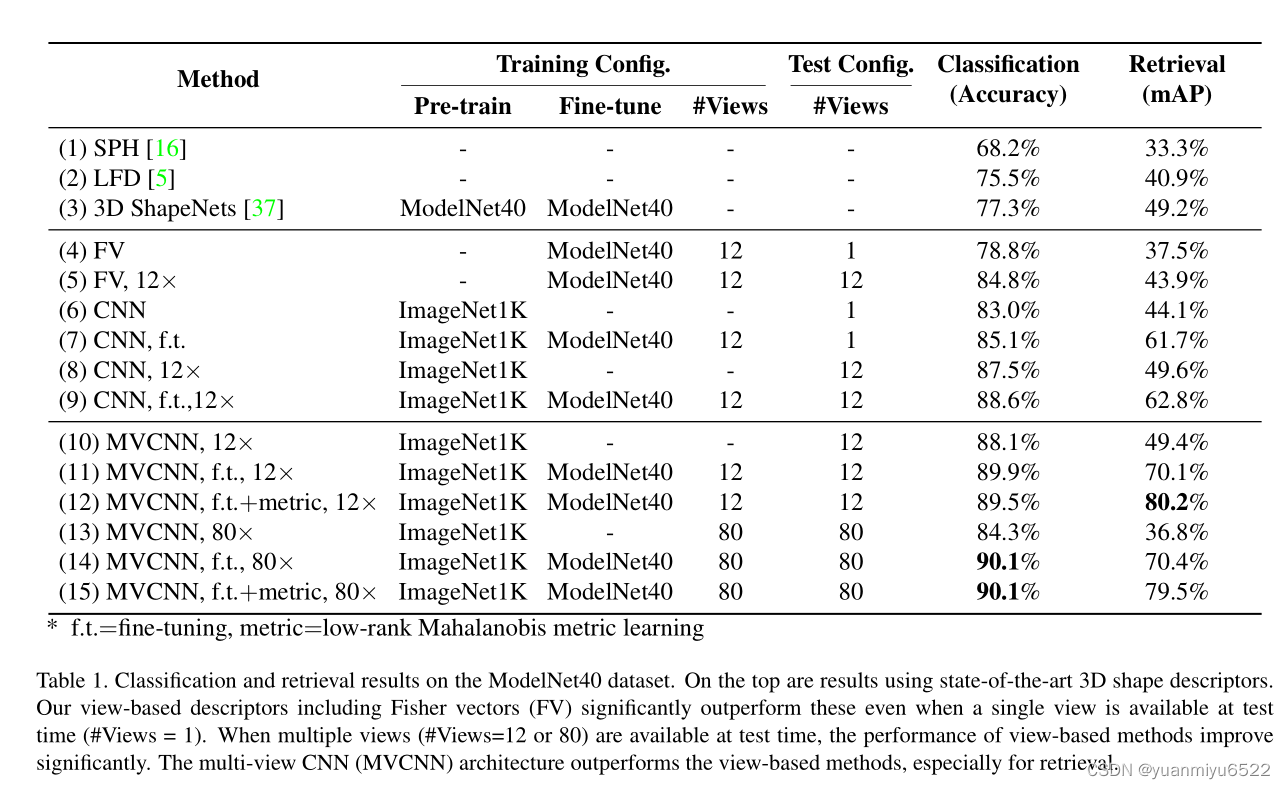
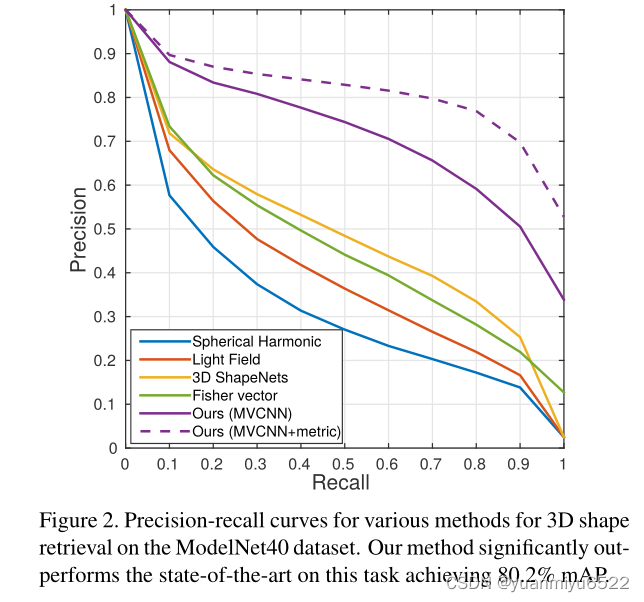
结论:
- 使用3D形状的投影视图的2D表示还是很有效的。
- 使用在ImageNet上预训练的主干网络能够提高任务的精度。
- MVCNN更强,没得说。
- low-rank Mahalanobis的使用对于retrieval任务来说更是锦上添花。
- view pooling layer放在第5层效果最好。
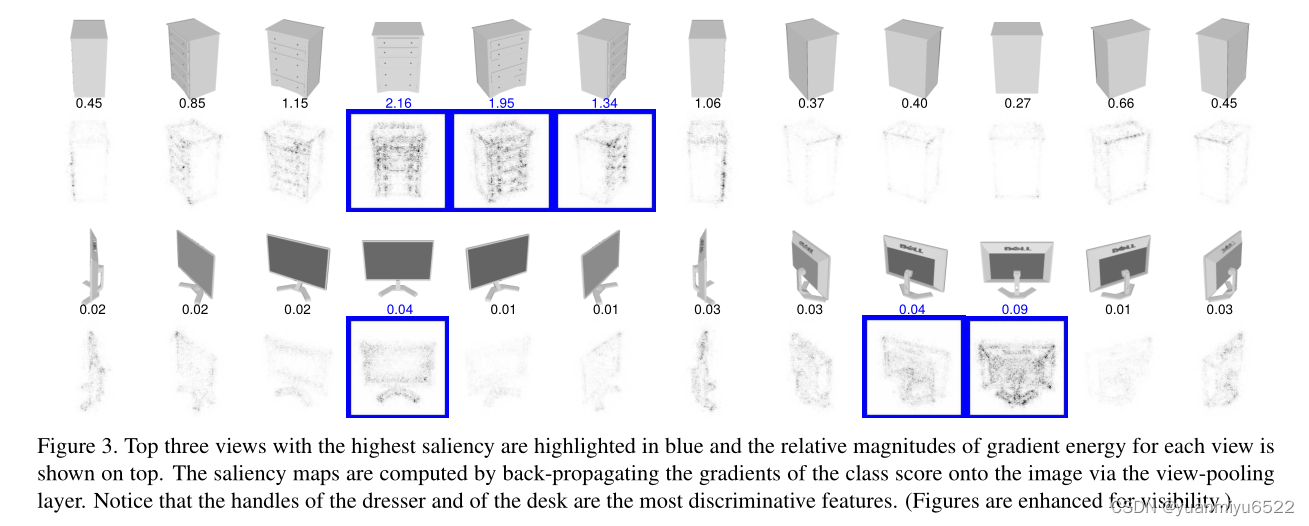
Saliency map among views
对于每个3D形状 S S S,其表示都对应着 K K K个2D视图 { I 1 , I 2 … I K } \left\{I_{1}, I_{2} \ldots I_{K}\right\} {I1,I2…IK}。我们想要对2D视图中的像素进行排名,看看他们对网络的输出分 F c F_{c} Fc的影响(第八层,相对于 c c c类别)。Saliency maps被定义为对 F c F_{c} Fc求导:
[ w 1 , w 2 … w K ] = [ ∂ F c ∂ I 1 ∣ S , ∂ F c ∂ I 2 ∣ S … ∂ F c ∂ I K ∣ S ] \left[w_{1}, w_{2} \ldots w_{K}\right]=\left[\left.\frac{\partial F_{c}}{\partial I_{1}}\right|_{S},\left.\left.\frac{\partial F_{c}}{\partial I_{2}}\right|_{S} \ldots \frac{\partial F_{c}}{\partial I_{K}}\right|_{S}\right] [w1,w2…wK]=[∂I1∂Fc∣∣∣∣S,∂I2∂Fc∣∣∣∣S…∂IK∂Fc∣∣∣∣S]
对于MVCNN而言, w w w可以在所有网络参数固定的情况下使用反向传播进行计算,然后可以重新排列以形成单个视图的Saliency maps。
4.2 Sketch Recognition: Jittering Revisited
就是2D图像的数据增强。
数据集:human sketch dataset,包含了20000个手工绘制的草图,250种类型。
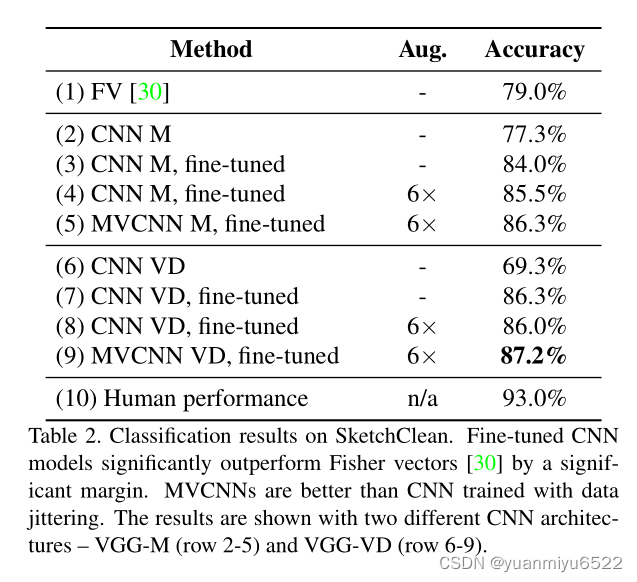
4.3 Sketch-based 3D Shape Retrieval
数据集:
- SketchClean, 193个草图,10类
- ModelNet40,790个CAD模型,10类
3D模型的处理过程:
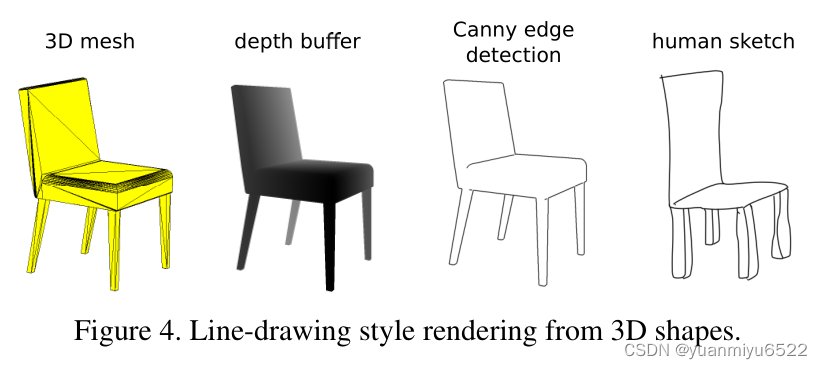
然后和手工画的草图进行特征比较,根据公式1排序。
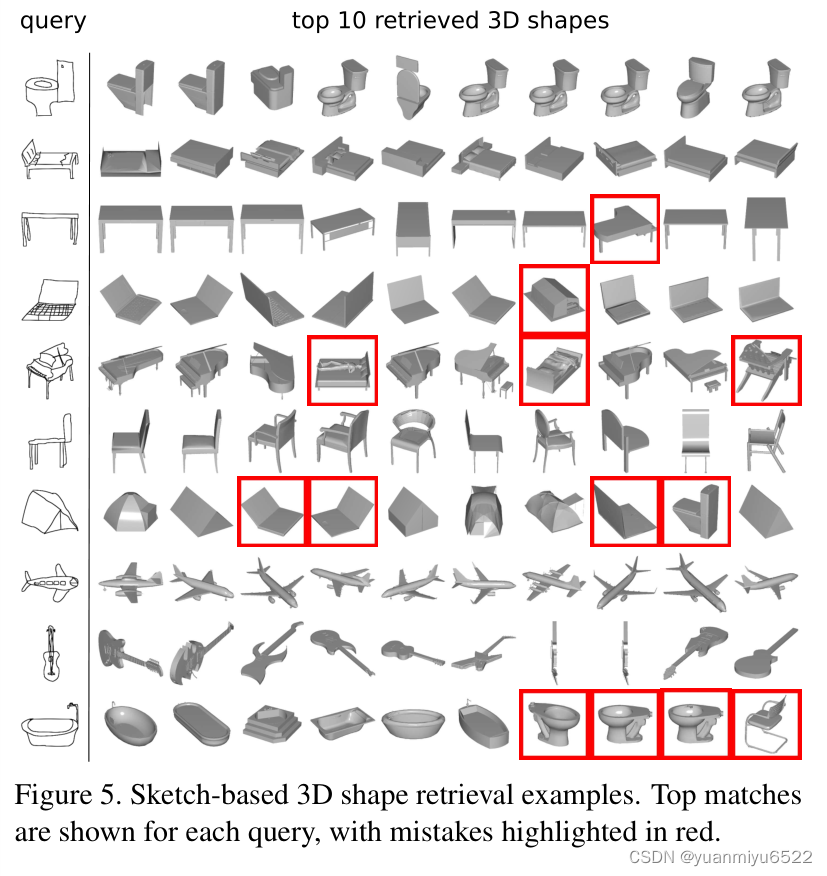
最后得到的精度为36.1%
5. 结论
- 对多视图的特征结合来说,哪些视图的信息最多?多少张视图最适合?可以实时选择最合适的视图吗?
- 对于真实3D形状来说,多维视图方法还管用吗?
论文写作亮点
- A large corpus of
- silhouette n. 轮廓
这篇关于【点云处理之狂读论文经典篇2】——Multi-view Convolutional Neural Networks for 3D Shape Recognition的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




