本文主要是介绍LLMs:《A Survey of Large Language Models大语言模型综述》的翻译与解读(一)之序言(挑战+LM四阶段+LLM与PLM的三大区别)、概述(两个代表性扩展定律/涌现能力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
LLMs:《A Survey of Large Language Models大语言模型综述》的翻译与解读(一)之序言(挑战+LM四阶段+LLM与PLM的三大区别)、概述(两个代表性扩展定律/涌现能力三种典型/六大关键技术+GPT系列技术演进)、资源(开源模型/闭源API+六类语料库+三种框架库)
导读:LLMs(LLM)是指具有数十亿甚至数百亿参数的 Transformer 语言模型,近年来取得了巨大的进展,对 AI 研究产生了重大影响。
>> LLM 具有某些新兴的能力,例如遵循自然语言指令的能力和逐步推理的能力,这些能力随着模型规模的增加而突然出现。
>> 开发高质量的 LLM 需要处理好的数据集、复杂的模型架构设计和大规模分布式训练技术。数据质量和训练技巧对模型性能有重要影响。
>> 指令调整和人类价值调整是两个重要的方法来调整预训练的 LLM,前者提升 LLM 的能力,后者使 LLM 行为符合人类期望。
>> 通过设计提示,LLM 可以解决各种下游任务。常用的提示技术包括语境学习和思维链提示。
>> LLM 在语言生成、知识利用和复杂推理等多个方面展现了强大能力,但也存在一些问题,如虚假文本生成和缺乏最新知识等。
>> LLM 在医疗、法律、金融等多个领域都展现出应用前景,但也存在一些风险和挑战。
>> 理解 LLM 的基本原理、改进模型训练方法、提高提示设计和确保模型安全仍有待进一步研究。
博主总结核心点如下
1、语言建模的四个阶段:SLM→NLM→PLM→LLM
2、LLM与PLM的三个主要区别:LLM的涌现能力+LLM的使用方式(提示技术)+系统性工程问题
3、LLMs涌现能力(小模型超过一定阈值才出现)的三种典型:上下文学习ICL(GPT-3正式引入)、指令跟随IFT(自然语言的指令微调+新任务指令→带来泛化)、逐步推理(基于CoT的提示策略)
4、LLMs的关键技术:规模扩展(Chinchilla【拥有更多训练tokens】优于Gopher【具有更大模型】+数据缩放应伴随着数据清洗过程)、训练技巧(分布式训练【并行策略DeepSpeed和Megatron-LM】+优化技巧【重启+混合精度】)、指令调优(【CoT】诱导潜在能力→涌现能力)、对齐调优(InstructGPT【RLHF】)、加持外部工具插件(计算器/外部引擎等)
5、能力的飞跃:GPT2→GPT-3:引入ICL+自然文本来理解任务+带来涌现能力+PLM飞向LLM的高光时刻
6、改进GPT-3的两种方法
T1、基于GitHub代码数据微调训练(如Codex/GPT-3.5)
T2、人类对齐(如RLHF指令调优【PPO+减轻有毒内容】,如InstructGPT,三个方向【训练AI系统使用人类反馈、协助人类评估、对齐研究】)7、常用的六类语料库+三种代码库
(1)、Books书籍类:BookCorpus(1.1W本,如GPT-1/GPT-2)、Project Gutenberg(7W本,如MT-NLG/LLaMA)、Books1_2(未公开,如GPT-3)
(2)、CommonCrawl开源网络爬虫数据库类(PB级别):过滤后的四类常用数据集(C4多语言版【45T】/CC-Stories故事的形式【31G】/CC-News新闻语料【120G】/RealNews新闻语料【76G】)
(3)、Reddit Links社交媒体平台类:WebText高赞链接语料库(未公开但有替代品OpenWebText)、 PushShift(实时更新)
(4)、Wikipedia百科全书类:比如GPT-3/LaMDA/LLaMA
(5)、Code类:GitHub公共代码存储库、StackOverflow代码问答平台、BigQuery(谷歌的不同编程语言的代码片段,如CodeGen模型)
(6)、Others其他类:Pile(800G+22个多样化的高质量子集,如CodeGen/Megatron-Turing NLG)、ROOTS(1.6T+59种不同的语言【自然语言和编程语言】,如BLOOM)7、2+5+大高性能库
(1)、DL基础库:Transformers(Hugging Face开发)、DeepSpeed(微软开发DL分布式训练优化库【内存优化{ZeRO+梯度检查点}+管道并行】,如MT-NLG/BLOOM )
(2)、高性能分布式库:Megatron-LM(NVIDIA开发DL分布式训练库【MP/DP+AMP+FlashAttention】)、JAX(Google开发高性能ML库)
(3)、高性能分布式库:Colossal-AI(新加坡云计算公司HPC开发+基于PyTorch+并行策略)、BMTrain(清华大学OpenBMB开发分布式训练高效库+Flan-T5/GLM)、FastMoE(针对MoE的训练库+基于PyTorch)
(4)、其它如PyTorch、TensorFlow、MXNet、PaddlePaddle、MindSpore、OneFlow
LLMs:大型语言模型发展综述—序言(挑战+LM四阶段+LLM与PLM的三大区别)、概述(两个代表性扩展定律/涌现能力三种典型/六大关键技术+GPT系列技术演进)、资源(开源模型/闭源API+六类语料库+三种框架库)、预训练(数据集+架构+模型训练)、适应LLMs(指令调优+对齐微调+参数高效微调+内存高效的模型自适应)、三大使用(ICT+CoT+PCT)、能力评估三种类型(基本+高级+基准)、提示设计实践指南、五大应用场景、未来六大方向
目录
相关文章
LLMs:《A Survey of Large Language Models大型语言模型概览》的翻译与解读(一)之序言(挑战+LM四阶段+LLM与PLM的三大区别)、概述(两个代表性扩展定律/涌现能力三种典型/六大关键技术+GPT系列技术演进)、资源(开源模型/闭源API+六类语料库+三种框架库)
LLMs:《A Survey of Large Language Models大型语言模型概览》的翻译与解读(二)之预训练(数据集+架构+模型训练)
LLMs:《A Survey of Large Language Models大型语言模型概览》的翻译与解读(三)之适应LLMs(指令调优+对齐微调+参数高效微调+内存高效的模型自适应)
LLMs:《A Survey of Large Language Models大型语言模型概览》的翻译与解读(四)之三大使用(ICT+CoT+PCT)、能力评估三种类型(基本+高级+基准)、提示设计实践指南、五大应用场景、总结与未来方向
《A Survey of Large Language Models》的翻译与解读
Abstract摘要
1 Introduction序言(挑战+LM四阶段+LLM与PLM的三大区别)
(1)、AI实现人类语言交流是一个长期的研究挑战
(2)、语言建模的四个阶段:SLM→NLM→PLM→LLM
统计语言模型(SLM)—1990s:基于马尔可夫假设(如n元LM模型),受维度诅咒→提出平滑策略缓解数据稀疏问题
神经语言模型(NLM)—2003:RNN(序列建模)→NNLM引入词分布式表示→word2vec(浅层神经网络)学习词的分布式表示(被证明非常有效)
预训练语言模型(PLM)-2017:Transformer(self-attention+高度可并行)+ELMo(预训练BiLSTM获得动态单词表征)→BERT(Transformer+开启两阶段学习范式【预训练+微调】)→GPT-2/BART
大型语言模型(LLM)—2020:扩展规模(但基于相似的框架和预训练任务)带来涌现能力(如GPT-3或PALM)→ChatGPT
(3)、LLM与PLM的三个主要区别:LLM的涌现能力+LLM的使用方式(提示技术)+系统性工程问题
AI领域因为LLM的快速发展而革命性迭代:NLP领域、IR领域、CV领域
LLM的基本原则仍未得到充分探索:涌现能力分析、LLM高昂成本+多来自工业界→训练细节闭源、仍需要有效控制LLM潜在风险
LLM的四大方面:预训练、适应性、使用性、能力评估
(4)、本文章的结构:侧重于开发和使用LLM的技术和方法
2 Overview概述(两个代表性扩展定律/涌现能力三种典型/六大关键技术+GPT系列技术演进)
2.1 Background for LLMs—LLMs的背景
Scaling Laws for LLMs.——LLMs的两个代表性扩展定律:KM缩放定律(NDC三公式幂律关系+偏模型更大预算)、Chinchilla缩放定律(偏数据更大预算)→有些能力(比如上下文学习)模型大小超过一定阈值时才能被观察到
Emergent Abilities of LLMs—LLMs涌现能力(小模型超过一定阈值才出现)的三种典型:上下文学习ICL(GPT-3正式引入)、指令跟随IFT(自然语言的指令微调+新任务指令→带来泛化)、逐步推理(基于CoT的提示策略)
Key Techniques for LLMs——LLMs的关键技术:规模扩展(Chinchilla【拥有更多训练tokens】优于Gopher【具有更大模型】+数据缩放应伴随着数据清洗过程)、训练技巧(分布式训练【并行策略DeepSpeed和Megatron-LM】+优化技巧【重启+混合精度】)、指令调优(【CoT】诱导潜在能力→涌现能力)、对齐调优(InstructGPT【RLHF】)、加持外部工具插件(计算器/外部引擎等)
2.2 Technical Evolution of GPT-series Models—GPT系列模型的技术演进
GPT模型成功的两个关键:decoder-only Transformer+扩大LM的规模
Early Explorations早期探索:
OpenAI早期的RNN
GPT-1:明确生成式+确定建模基本原理【NSP任务】+采用decoder-only Transformer架构+无监督预训练+监督微调
GPT-2—无监督多任务学习器:基于WebText数据集+参数扩至1.5B+无监督语言建模ULM代替明确微调(ULM来解决各种任务+统一视为单词预测问题)+采用概率式的多任务求解(输入和任务信息为条件去预测输出)
Capacity Leap能力的飞跃:GPT2→GPT-3:引入ICL+自然文本来理解任务+带来涌现能力+PLM飞向LLM的高光时刻
Capacity Enhancement容量增强——改进GPT-3的两种方法
T1、基于GitHub代码数据微调训练(如Codex/GPT-3.5)
T2、人类对齐(如RLHF指令调优【PPO+减轻有毒内容】,如InstructGPT,三个方向【训练AI系统使用人类反馈、协助人类评估、对齐研究】)
The Milestones of Language Models语言模型的里程碑
ChatGPT(语言模型的里程碑):InstructGPT的姊妹模型+专门优化对话+支持插件+卓越能力(知识储备+数学推理+多轮追踪+对齐人类)
GPT-4:多模态+6个月的迭代对齐(RLHF+额外的安全奖励信号)+多种干预策略来降幻觉和隐私(红队测试)+完善的DL基础设施+新机制(可预测的缩放→少量的计算来准确预测最终性能)
3 Resources Of Llms—Llms的资源(开源模型/闭源API+六类语料库+三种代码库)
3.1 Publicly Available Model Checkpoints or APIs——公开可用的模型检查点或API
10B~Models with Tens of Billions of Parameters—数百亿参数的模型(开源非常多)
指令调优(Flan-T5)、代码生成(CodeGen)、多语言任务(mT0)
LLaMA的两个优化方向(微调、增量预训练)、Falcon(注重数据清洗)
预训练硬件(数百上千的GPU)—LLaMA采用2048个A100、FLOPS衡量
LLaMA研究工作的演化图
100B~Models with Hundreds of Billions of Parameters数千亿参数的模型(少数开源)
OPT、跨语言泛化(BLOOM)、双语(GLM及其中文聊天模型ChatGLM2-6B)
预训练硬件(上千的GPU)—OPT采用992个A100、GLM采用96节点*8个A100
LLaMA Model Family——LLaMA模型系列
LLaMA系列:基于LLaMA架构的优化(指令微调/持续预训练)、非英语场景优化(扩展词表+基于目标语言数据微调)
Alpaca:LLaMA +52K指令数据(text-davinci-003生成)
Alpaca-LoRA:Alpaca+LoRA 微调、Koala 、BELLE
Public API of LLMs——LLMs的公共API:比如OpenAI的GPT-3/GPT-4系列、Codex
3.2 Commonly Used Corpora常用的六类语料库
(1)、Books书籍类:BookCorpus(1.1W本,如GPT-1/GPT-2)、Project Gutenberg(7W本,如MT-NLG/LLaMA)、Books1_2(未公开,如GPT-3)
(2)、CommonCrawl开源网络爬虫数据库类(PB级别):过滤后的四类常用数据集(C4多语言版【45T】/CC-Stories故事的形式【31G】/CC-News新闻语料【120G】/RealNews新闻语料【76G】)
(3)、Reddit Links社交媒体平台类:WebText高赞链接语料库(未公开但有替代品OpenWebText)、 PushShift(实时更新)
(4)、Wikipedia百科全书类:比如GPT-3/LaMDA/LLaMA
(5)、Code类:GitHub公共代码存储库、StackOverflow代码问答平台、BigQuery(谷歌的不同编程语言的代码片段,如CodeGen模型)
(6)、Others其他类:Pile(800G+22个多样化的高质量子集,如CodeGen/Megatron-Turing NLG)、ROOTS(1.6T+59种不同的语言【自然语言和编程语言】,如BLOOM)
总结:实践中需要混合不同数据源的语料库(如C4+OpenWebText+Pile):
GPT-3-175B :CommonCrawl+WebText2+Books1_2+Wikipedia(300B的tokens混合数据)
PaLM-540B:社交媒体对话+过滤网页+书籍+Github+多语言维基百科和新闻(780B的tokens数据)
LLaMA-6B/32B:CommonCrawl+C4+Github+Wikipedia+books+ArXiv+StackExchange(1T/1.4T的tokens数据)
3.3 Library Resource库资源—2+5+大高性能库
(1)、DL基础库:Transformers(Hugging Face开发)、DeepSpeed(微软开发DL分布式训练优化库【内存优化{ZeRO+梯度检查点}+管道并行】,如MT-NLG/BLOOM )
(2)、高性能分布式库:Megatron-LM(NVIDIA开发DL分布式训练库【MP/DP+AMP+FlashAttention】)、JAX(Google开发高性能ML库)
(3)、高性能分布式库:Colossal-AI(新加坡云计算公司HPC开发+基于PyTorch+并行策略)、BMTrain(清华大学OpenBMB开发分布式训练高效库+Flan-T5/GLM)、FastMoE(针对MoE的训练库+基于PyTorch)
(4)、其它如PyTorch、TensorFlow、MXNet、PaddlePaddle、MindSpore、OneFlow
相关文章
LLMs:《A Survey of Large Language Models大型语言模型概览》的翻译与解读(一)之序言(挑战+LM四阶段+LLM与PLM的三大区别)、概述(两个代表性扩展定律/涌现能力三种典型/六大关键技术+GPT系列技术演进)、资源(开源模型/闭源API+六类语料库+三种框架库)
https://yunyaniu.blog.csdn.net/article/details/131565801
LLMs:《A Survey of Large Language Models大型语言模型概览》的翻译与解读(二)之预训练(数据集+架构+模型训练)
https://yunyaniu.blog.csdn.net/article/details/131692995
LLMs:《A Survey of Large Language Models大型语言模型概览》的翻译与解读(三)之适应LLMs(指令调优+对齐微调+参数高效微调+内存高效的模型自适应)
https://yunyaniu.blog.csdn.net/article/details/131693008
LLMs:《A Survey of Large Language Models大型语言模型概览》的翻译与解读(四)之三大使用(ICT+CoT+PCT)、能力评估三种类型(基本+高级+基准)、提示设计实践指南、五大应用场景、总结与未来方向
https://yunyaniu.blog.csdn.net/article/details/131692988
《A Survey of Large Language Models》的翻译与解读
| 地址 | 论文:https://arxiv.org/abs/2303.18223 |
| 时间 | 2023年6月29日 |
| 作者 | Wayne Xin Zhao, Kun Zhou*, Junyi Li*, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie and Ji-Rong Wen |
Abstract摘要
本文介绍了大语言模型(LLMs)的研究进展(尤其是ChatGPT),包括其背景、关键发现、主流技术以及未来发展方向,重点关注LLM的四个主要方面:预训练、适应调优、利用和容量评估。总结了开发LLMs的可用资源,并讨论了未来发展方向中的尚存问题。这份调查报告为研究人员和工程师提供了一个最新的LLMs文献综述资源。
| Ever since the Turing Test was proposed in the 1950s, humans have explored the mastering of language intelligence by machine. Language is essentially a complex, intricate system of human expressions governed by grammatical rules. It poses a significant challenge to develop capable artificial intelligence (AI) algorithms for comprehending and grasping a language. As a major approach, language modeling has been widely studied for language understanding and generation in the past two decades, evolving from statistical language models to neural language models. Recently, pre-trained language models (PLMs) have been proposed by pre-training Transformer models over large-scale corpora, showing strong capabilities in solving various natural language processing (NLP) tasks. Since the researchers have found that model scaling can lead to an improved model capacity, they further investigate the scaling effect by increasing the parameter scale to an even larger size. Interestingly, when the parameter scale exceeds a certain level, these enlarged language models not only achieve a significant performance improvement, but also exhibit some special abilities (e.g., in-context learning) that are not present in small-scale language models (e.g., BERT). To discriminate the language models in different parameter scales, the research community has coined the term large language models (LLM) for the PLMs of significant size (e.g., containing tens or hundreds of billions of parameters). Recently, the research on LLMs has been largely advanced by both academia and industry, and a remarkable progress is the launch of ChatGPT (a powerful AI chatbot developed based on LLMs), which has attracted widespread attention from society. The technical evolution of LLMs has been making an important impact on the entire AI community, which would revolutionize the way how we develop and use AI algorithms. Considering this rapid technical progress, in this survey, we review the recent advances of LLMs by introducing the background, key findings, and mainstream techniques. In particular, we focus on four major aspects of LLMs, namely pre-training, adaptation tuning, utilization, and capacity evaluation. Furthermore, we also summarize the available resources for developing LLMs and discuss the remaining issues for future directions. This survey provides an up-to-date review of the literature on LLMs, which can be a useful resource for both researchers and engineers. | 自从图灵测试在1950年代提出以来,人们一直在探索机器掌握语言智能的方法。语言本质上是由语法规则控制的人类表达复杂、复杂的r人人类表达系统。开发有能力的人工智能(AI)算法来理解和掌握语言是一项重大挑战。 在过去的二十年里,语言建模作为语言理解和生成的一种主要方法得到了广泛的研究,从统计语言模型发展到神经语言模型。 近年来,通过对大规模语料库上的Transformer模型进行预训练,提出了预训练语言模型(PLMs),显示出较强的解决各种NLP(NLP)任务的能力。由于研究人员发现模型扩展可以导致模型容量的提高,他们进一步研究了通过将参数规模增加到更大的规模来扩展效应。有趣的是,当参数规模超过一定水平时,这些扩大的语言模型不仅可以显著提高性能,而且还表现出了一些在小规模语言模型(如BERT)中不存在的特殊能力(如上下文学习)。为了区分不同参数规模的语言模型,研究界已经为具有重要规模(例如包含数十亿或数百亿个参数)的PLMs创造了大型语言模型(LLM)这个术语。 最近,学术界和工业界对LLMs的研究取得了巨大进展,一个显著的进展是ChatGPT的推出(基于LLMs开发的强大AI聊天机器人),这引起了社会的广泛关注。LLMs的技术进步对整个AI社区产生了重要影响,它将彻底改变我们开发和使用AI算法的方式。 考虑到这种快速的技术进步,在本调查中,我们通过介绍背景、主要发现和主流技术,回顾了LLMs的最新进展。特别是,我们关注LLMs的四个主要方面,即预训练、适配微调、利用和能力评估。此外,我们还总结了开发LLMs的可用资源,并讨论了未来发展方向的其它问题。本调查提供了LLMs文献的最新评论,可供研究人员和工程师使用。 |
1 Introduction序言(挑战+LM四阶段+LLM与PLM的三大区别)
(1)、AI实现人类语言交流是一个长期的研究挑战
| “The limits of my language mean the limits of my world.” —Ludwig Wittgenstein | "我的语言的极限意味着我的世界的极限。"-路德维希·维特根施坦(英国哲学家) |
| LANGUAGE is a prominent ability in human beings to express and communicate, which develops in early childhood and evolves over a lifetime [1, 2]. Machines, however, cannot naturally grasp the abilities of understand-ing and communicating in the form of human language, unless equipped with powerful artificial intelligence (AI) algorithms. It has been a longstanding research challenge to achieve this goal, to enable machines to read, write, and communicate like humans [3]. | 语言是人类一种突出的表达和交流能力,这种能力从幼儿时期开始发展,并在一生中不断发展[1,2]。然而,除非配备强大的人工智能(AI)算法,否则机器无法自然地掌握以人类语言形式进行理解和交流的能力。要实现这一目标,使机器能够像人类一样阅读、写作和交流,一直是一个长期的研究挑战[3]。 |
(2)、语言建模的四个阶段:SLM→NLM→PLM→LLM
| Technically, language modeling (LM) is one of the major approaches to advancing language intelligence of machines. In general, LM aims to model the generative likelihood of word sequences, so as to predict the probabilities of future (or missing) tokens. The research of LM has received extensive attention in the literature, which can be divided into four major development stages: | 从技术上讲,语言建模(LM)是提高机器语言智能的主要方法之一。一般来说,LM旨在对单词序列的生成似然进行建模,从而预测未来(或缺失)标记的概率。LM的研究在文献中得到了广泛的关注,它可以分为四个主要的发展阶段: |
| Fig. 1: The trends of the cumulative numbers of arXiv papers that contain the keyphrases “language model” (since June 2018) and “large language model” (since October 2019), respectively. The statistics are calculated using exact match by querying the keyphrases in title or abstract by months. We set different x-axis ranges for the two keyphrases, because “language models” have been explored at an earlier time. We label the points corresponding to important landmarks in the research progress of LLMs. A sharp increase occurs after the release of ChatGPT: the average number of published arXiv papers that contain “large language model” in title or abstract goes from 0.40 per day to 8.58 per day (Figure 1(b)). | 图1:分别包含关键词“语言模型”(2018年6月至今)和“大型语言模型”(2019年10月至今)的arXiv论文累计数量变化趋势。统计信息是通过按月查询标题或摘要中的关键短语来使用精确匹配计算的。我们为两个关键短语设置了不同的x轴范围,因为“语言模型”在较早的时候已经被探索过。我们标记了LLMs的研究进展中重要里程碑对应的点。ChatGPT发布后出现了急剧的增长:在标题或摘要中包含“大型语言模型”的arXiv论文的平均发表数量从每天0.40篇增加到每天8.58篇(图1(b))。 |
统计语言模型(SLM)—1990s:基于马尔可夫假设(如n元LM模型),受维度诅咒→提出平滑策略缓解数据稀疏问题
| Statistical language models (SLM). SLMs [4–7] are developed based on statistical learning methods that rose in the 1990s. The basic idea is to build the word prediction model based on the Markov assumption, e.g., predicting the next word based on the most recent context. The SLMs with a fixed context length n are also called n-gram language models, e.g., bigram and trigram language models. SLMs have been widely applied to enhance task performance in information retrieval (IR) [8, 9] and natural language processing (NLP) [10–12]. However, they often suffer from the curse of dimensionality: it is difficult to accurately estimate high-order language models since an exponential number of transition probabilities need to be estimated. Thus, specially designed smoothing strategies such as back-off estimation [13] and Good–Turing estimation [14] have been introduced to alleviate the data sparsity problem. | 统计语言模型(SLM): 统计语言模型(SLM)。SLM [4-7]是基于1990年兴起的统计学习方法建立的。其基本思想是建立基于马尔可夫假设的单词预测模型,例如,根据最近的上下文预测下一个单词。具有固定上下文长度n的SLM也称为n元语言模型,如双元语言模型和三元语言模型。SLM得到广泛应用来提高信息检索(IR)[8,9]以及NLP(NLP)[10-12]任务性能。然而,他们通常受句法维度诅咒的影响:很难准确估计高阶的语言模型,因为需要估计一个指数数量的转移概率。因此,特别设计的平滑策略如回落估计[13]和Good-Turing 估计[14]被引入以缓解数据稀疏问题。 |
神经语言模型(NLM)—2003:RNN(序列建模)→NNLM引入词分布式表示→word2vec(浅层神经网络)学习词的分布式表示(被证明非常有效)
| Neural language models (NLM). NLMs [15–17] character-ize the probability of word sequences by neural networks,e.g., recurrent neural networks (RNNs). As a remarkable contribution, the work in [15] introduced the concept of distributed representation of words and built the word predic-tion function conditioned on the aggregated context features (i.e., the distributed word vectors). By extending the idea of learning effective features for words or sentences, a general neural network approach was developed to build a unified solution for various NLP tasks [18]. Further, word2vec [19, 20] was proposed to build a simplified shal-low neural network for learning distributed word represen-tations, which were demonstrated to be very effective across a variety of NLP tasks. These studies have initiated the use of language models for representation learning (beyond word sequence modeling), having an important impact on the field of NLP. | 神经语言模型(NLM)。NLM[15-17]通过神经网络表征词序列的概率,例如:,递归神经网络(RNN)。作为一个显著的贡献,[15]中的工作引入了词的分布式表示的概念,并建立了基于聚合上下文特征(即分布式词向量)的词预测函数。通过扩展学习单词或句子的有效特征的思想,开发了一种通用的神经网络方法来为各种NLP任务构建统一的解决方案[18]。此外,word2vec[19,20]被提出构建一个简化的浅层神经网络,用于学习单词的有效分布式表示,并被证明在各种NLP任务中非常有效。这些研究开创了语言模型在表征学习中的应用(超越了词序列建模),对NLP领域产生了重要影响。 |
预训练语言模型(PLM)-2017:Transformer(self-attention+高度可并行)+ELMo(预训练BiLSTM获得动态单词表征)→BERT(Transformer+开启两阶段学习范式【预训练+微调】)→GPT-2/BART
| Pre-trained language models (PLM). As an early at-tempt, ELMo [21] was proposed to capture context-aware word representations by first pre-training a bidirectional LSTM (biLSTM) network (instead of learning fixed word representations) and then fine-tuning the biLSTM network according to specific downstream tasks. Further, based on the highly parallelizable Transformer architecture [22] with self-attention mechanisms, BERT [23] was proposed by pre-training bidirectional language models with specially de-signed pre-training tasks on large-scale unlabeled corpora. These pre-trained context-aware word representations are very effective as general-purpose00semantic features, which have largely raised the performance bar of NLP tasks. This study has inspired a large number of follow-up work, which sets the “pre-training and fine-tuning” learning paradigm. Following this paradigm, a great number of studies on PLMs have been developed, intr00oducing either different architectures [24, 25] (e.g., GPT-2 [26] and BART [24]) or improved pre-training strategies [27–29]. In this paradigm, it often requires fine-tuning the PLM for adapting to different downstream tasks. | 预训练语言模型(PLM)。作为早期的尝试,ELMo[21]被提出通过首先预训练一个双向LSTM (biLSTM)网络(而不是学习固定的单词表示),然后根据特定的下游任务对biLSTM网络进行微调,来捕获上下文感知的单词表示。此外,[23]提出基于高度可并行的Transformer [22] 结构及自注意力机制,通过在大量不标记语料上预训练双向语言模型和特别设计的预训练任务来构建BERT。这些预先训练的上下文感知词表示作为通用语义特征是非常有效的,这在很大程度上提高了NLP任务的性能标准。该研究启发了大量的后续工作,建立了“预训练+微调”的学习范式。遵循这一范式,已经开展了大量关于PLM的研究,引入了不同的架构[24,25](例如GPT-2[26]和BART[24])或改进的预训练策略[27-29]。在此范例中,通常需要对PLM进行微调以适应不同的下游任务。 |
大型语言模型(LLM)—2020:扩展规模(但基于相似的框架和预训练任务)带来涌现能力(如GPT-3或PALM)→ChatGPT
| Large language models (LLM). Researchers find that scaling PLM (e.g., scaling model size or data size) often leads to an improved model capacity on downstream tasks (i.e., following the scaling law [30]). A number of studies have explored the performance limit by training an ever larger PLM (e.g., the 175B-parameter00GPT-3 and the 540B-parameter PaLM). Although scaling is mainly conducted in model size (with similar architectures and pre-training tasks), these large-sized PLMs display different behaviors from smaller PLMs (e.g., 330M-parameter BERT andT1.5B-parameter GPT-2) and show surprising abilities (called emer-gent abilities [31]) in solving a series of complex tasks. For example, GPT-3 can solve few-shot tasks through in-context learning, whereas GPT-2 cannot do well. Thus, the research community coins the term “large language models (LLM)”1 for these large-sized PLMs [32–35], which attract increasing research attention (See Figure 1). A remarkable application of LLMs is ChatGPT2 that adapts the LLMs from the GPT series for dialogue, which presents an amazing conversation ability with humans. We can observe a sharp increase of the arXiv papers that are related to LLMs after the release of ChatGPT in Figure 1. | 大型语言模型。研究人员发现,扩展PLM(例如缩放模型大小或数据大小)通常会改善下游任务的模型容量(即遵循缩放定律[30])。许多研究已经通过训练更大的PLM(例如,175b参数的GPT-3和540b参数的PaLM)来探索性能极限。虽然扩展主要是在模型大小上进行的(具有相似的架构和预训练任务),但这些大型plm与较小的plm(例如330m参数的BERT和1.5 b参数的GPT-2)表现出不同的行为,并且在解决一系列复杂任务时表现出惊人的能力(称为emergent 涌现能力[31])。例如,GPT-3可以通过上下文学习解决少量任务,而GPT-2则做得不好。因此,研究界将这些大型plm称为“大型语言模型(LLM)”1[32-35],引起了越来越多的研究关注(见图1)。LLM的一个显著应用是ChatGPT,它将GPT系列中的LLM用于对话,呈现出与人类惊人的对话能力。如图1所示,我们可以看到ChatGPT发布后,与llm相关的arXiv论文急剧增加。 |
(3)、LLM与PLM的三个主要区别:LLM的涌现能力+LLM的使用方式(提示技术)+系统性工程问题
| In the existing literature, PLMs have been widely dis-cussed and surveyed [36–39], while LLMs are seldom re-viewed in a systematic way. To motivate our survey, we first highlight three major differences between LLMs and PLMs. First, LLMs display some surprising emergent abilities that may not be observed in previous smaller PLMs. These abili-ties are key to the performance of language models on com-plex tasks, making AI algorithms unprecedently powerful and effective. Second, LLMs would revolutionize the way that humans develop and use AI algorithms. Unlike small PLMs, the major approach to accessing LLMs is through the prompting interface (e.g., GPT-4 API). Humans have to understand how LLMs work and format their tasks in a way that LLMs can follow. Third, the development of LLMs no longer draws a clear distinction between research and en-gineering. The training of LLMs requires extensive practical experiences in large-scale data processing and distributed parallel training. To develop capable LLMs, researchers have to solve complicated engineering issues, working with engineers or being engineers. | 在现有文献中,PLM已经被广泛讨论和调查[36-39],而LLM很少以系统的方式进行回顾。为了激发我们的调查,我们首先强调LLM与PLM之间的三个主要区别。 首先,LLM展示了一些惊人的涌现能力,这些能力可能在以前较小的PLM中没有观察到。这些能力对于语言模型在复杂任务中的性能至关重要,使得AI算法具有前所未有的强大和有效。 其次,LLM将革命性地改变人类开发和使用AI算法的方式。与小型PLM不同,访问LLM的主要方法是通过提示接口(例如GPT-4 API)。人类必须理解LLM的工作原理,并以LLM可以遵循的方式格式化其任务。 第三,LLM的开发不再明确区分研究和工程。LLM的训练需要大规模数据处理和分布式并行训练的广泛实践经验。为了开发能力强大的LLM,研究人员必须解决复杂的工程问题,与工程师合作或成为工程师。 |
AI领域因为LLM的快速发展而革命性迭代:NLP领域、IR领域、CV领域
| Nowadays, LLMs are posing a significant impact on the AI community, and the advent of ChatGPT and GPT-4 leads to the rethinking of the possibilities of artificial general intelligence (AGI). OpenAI has published a technical article entitled “Planning for AGI and beyond”, which discusses the short-term and long-term plans to approach AGI [40],and a more recent paper has argued that GPT-4 might be considered as an early version of an AGI system [41]. The research areas of AI are being revolutionized by the rapid progress of LLMs. In the field of NLP, LLMs can serve as a general-purpose language task solver (to some extent), and the research paradigm has been shifting towards the use of LLMs. In the field of IR, traditional search engines are challenged by the new information seeking way through AI chatbots (i.e., ChatGPT), and New Bing3 presents an initial attempt that enhances the search results based on LLMs. In the field of CV, the researchers try to develop ChatGPT-like vision-language models that can better serve multimodal dialogues [42–45], and GPT-4 [46] has supported multi-modal input by integrating the visual information. This new wave of technology would potentially lead to a prosperous ecosystem of real-world applications based on LLMs. For instance, Microsoft 365 is being empowered by LLMs (i.e., Copilot) to automate the office work, and OpenAI supports the use of plugins in ChatGPT for implementing special functions. | 如今,LLM对AI社区产生了重大影响,ChatGPT和GPT-4的出现导致重新思考人工智能(AGI)的可能性。OpenAI发表了一篇名为“Planning for AGI and beyond”的技术文章,讨论了接近AGI的短期和长期计划[40],最近的一篇论文认为GPT-4可能被视为AGI系统的早期版本[41]。 AI研究领域正在通过LLM的快速进展而发生革命。在NLP领域,LLM可以作为通用语言任务求解器(在某种程度上),研究范式已经转向使用LLM。在IR领域,传统搜索引擎受到通过AI 聊天机器人(即ChatGPT)寻求新信息的方式的挑战,新的Bing3提供了一种基于LLM增强搜索结果的初始尝试。在CV领域,研究人员试图开发类似于ChatGPT的视觉语言模型,以更好地服务于多模态对话[42-45],而GPT-4 [46]通过整合视觉信息支持多模态输入。这股新技术浪潮有可能导致基于LLM的真实世界应用的繁荣生态系统。例如,微软365正在通过LLM(即Copilot)赋能办公自动化,并且OpenAI支持在ChatGPT中使用插件来实现特殊功能。 |
LLM的基本原则仍未得到充分探索:涌现能力分析、LLM高昂成本+多来自工业界→训练细节闭源、仍需要有效控制LLM潜在风险
| Despite the progress and impact, the underlying prin-ciples of LLMs are still not well explored. Firstly, it is mysterious why emergent abilities occur in LLMs, instead of smaller PLMs. As a more general issue, there lacks a deep, detailed investigation of the key factors that contribute to the superior abilities of LLMs. It is important to study when and how LLMs obtain such abilities [47]. Although there are some meaningful discussions about this problem [31, 47], more principled investigations are needed to uncover the “secrets“ of LLMs. Secondly, it is difficult for the research community to train capable LLMs. Due to the huge de-mand of computation resources, it is very costly to carry out repetitive, ablating studies for investigating the effect of various strategies for training LLMs. Indeed, LLMs are mainly trained by industry, where many important training details (e.g., data collection and cleaning) are not revealed to the public. Thirdly, it is challenging to align LLMs with human values or preferences. Despite the capacities, LLMs are also likely to produce toxic, fictitious, or harmful con-tents. It requires effective and efficient control approaches to eliminating the potential risk of the use of LLMs [46]. | 尽管取得了进展和影响,LLM的基本原则仍未得到充分探索。 首先,不清楚为什么涌现能力出现在LLM中,而不是较小的PLM。作为更一般的问题,缺乏深入,详细的调查,以了解对LLM的优越能力有所贡献的关键因素。研究LLM何时以及如何获得这些能力非常重要[47]。虽然有一些有意义的讨论[31, 47],但需要更有原则的调查来揭示LLM的“秘密”。 其次,研究界很难训练能力强大的LLM。由于计算资源的巨大需求,为了调查各种llm训练策略的效果,进行重复的、有针对性的研究是非常昂贵的。实际上,LLM主要是由工业界进行训练,许多重要的训练细节(例如数据收集和清洗)并未向公众公开。 第三,将LLM与人类价值观或偏好相一致是具有挑战性的。尽管具有能力,LLM也可能产生有害、虚构或有害的内容。需要有效和高效的控制方法来消除使用LLM的潜在风险[46]。 |
LLM的四大方面:预训练、适应性、使用性、能力评估
| Faced with both opportunities and challenges, it needs more attention on the research and development of LLMs. In order to provide a basic understanding of LLMs, this survey conducts a literature review of the recent advances in LLMs from four major aspects, including pre-training (how to pre-train a capable LLM), adaptation (how to effectively adapt pre-trained LLMs for better use), utilization (how to use LLMs for solving various downstream tasks) and capability evaluation (how to evaluate the abilities of LLMs and existing empirical findings). We thoroughly comb the literature and summarize the key findings, techniques, and methods of LLMs. | 面临机遇和挑战,需要更多关注LLM的研究和开发。为了对LLM有一个基本的了解,本调查从四个主要方面进行了文献综述,包括预训练(如何预训练能力强大的LLM)、适应性(如何有效地适应预训练的LLM以获得更好的使用)、利用(如何使用LLM解决各种下游任务)和能力评估(如何评估LLM的能力和现有实证研究结果)。我们彻底梳理文献,总结法LLM的主要发现、技术和方法。 |
(4)、本文章的结构:侧重于开发和使用LLM的技术和方法
| For this survey, we also create a GitHub project website by collecting the supporting resources for LLMs, at the link https://github.com/RUCAIBox/LLMSurvey. We are also aware of several related review articles on PLMs or LLMs [32, 36, 38, 39, 43, 48–54]. These papers either discuss PLMs or some specific (or general) aspects of LLMs. Compared with them, we focus on the techniques and methods to develop and use LLMs and provide a relatively comprehensive reference to important aspects of LLMs. | 为了这项调查,我们还创建了一个GitHub项目网站,收集了支持LLM的资源,链接为https://github.com/RUCAIBox/LLMSurvey ↗。我们也知道有几篇关于PLM或LLM的相关综述的文章[32, 36, 38, 39, 43, 48-54]。这些论文要么讨论PLM,要么讨论LLM的一些特定(或一般)方面。与它们相比,我们侧重于开发和使用LLM的技术和方法,并为LLM的重要方面提供相对全面的参考。 |
| The remainder of this survey is organized as follows: Section 2 introduces the background for LLMs and the evo-lution of GPT-series models, followed by the summarization of available resources for developing LLMs in Section 3. Sections 4, 5, 6, and 7 review and summarize the recent progress from the four aspects of pre-training, adaptation, utilization, and capacity evaluation, respectively. Then, Sec-tion 8 discusses the practical guide for prompt design, and Section 9 reviews the applications of LLMs in several representative domains. Finally, we conclude the survey in Section 10 by summarizing the major findings and discuss the remaining issues for future work. | 本调查的其余部分组织如下:第2节介绍了LLM的背景和GPT系列模型的演变,然后在第3节总结了开发法LLM的可用资源。第4节、第5节、第6节和第7节分别从训练前、适应、利用和能力评估四个方面回顾和总结了最近的进展。然后,第8节讨论了提示设计的实践指南,第9节回顾了LLM在几个代表性领域的应用。最后,我们在第10节中总结了调查的主要发现,并讨论了未来工作中有待解决的问题。 |
2 Overview概述(两个代表性扩展定律/涌现能力三种典型/六大关键技术+GPT系列技术演进)
| In this section, we present an overview about the back-ground of LLMs and then summarize the technical evolu-tion of the GPT-series models. | 本部分介绍了LLMs的背景,并总结了GPT系列模型的技术发展。 |
2.1 Background for LLMs—LLMs的背景
| Typically, large language models (LLMs) refer to Transformer language models that contain hundreds of billions (or more) of parameters4, which are trained on massive text data [32], such as GPT-3 [55], PaLM [56], Galactica [35], and LLaMA [57]. LLMs exhibit strong capacities to un-derstand natural language and solve complex tasks (via text generation). To have a quick understanding of how LLMs work, this part introduces the basic background for LLMs, including scaling laws, emergent abilities and key techniques. | 通常,大型语言模型(LLMs)是指包含数百亿(或更多)参数的Transformer语言模型,这些模型在大规模文本数据[32]上进行训练,例如GPT-3 [55]、PaLM [56]、Galactica [35]和LLaMA [57]。LLMs表现出强大的自然语言理解能力和解决复杂任务(通过文本生成)的能力。为了快速了解LLMs如何工作,本部分介绍LLMs的基本背景,包括扩展定律、涌现能力和关键技术。 |
Scaling Laws for LLMs.——LLMs的两个代表性扩展定律:KM缩放定律(NDC三公式幂律关系+偏模型更大预算)、Chinchilla缩放定律(偏数据更大预算)→有些能力(比如上下文学习)模型大小超过一定阈值时才能被观察到
| Scaling Laws for LLMs. Currently, LLMs are mainly built upon the Transformer architecture [22], where multi-head attention layers are stacked in a very deep neural network. Existing LLMs adopt similar Transformer architectures and pre-training objectives (e.g., language modeling) as small language models. However, LLMs significantly extend the model size, data size, and total compute (orders of mag-nification). Extensive research has shown that scaling can largely improve the model capacity of LLMs [26, 55, 56]. Thus, it is useful to establish a quantitative approach to characterizing the scaling effect. Next, we introduce two representative scaling laws for Transformer language mod-els [30, 34]. | 目前,LLMs主要基于Transformer架构[22]构建,其中多头自注意力层堆叠在一个非常深的神经网络中。现有的LLMs采用类似的Transformer架构和预训练目标(例如语言建模),就像小型语言模型一样。然而,LLMs显著扩展了模型大小、数据大小和总计算量(数量级)。广泛的研究表明,缩放可以大大提高LLMs的模型容量[26,55,56]。因此,建立一种量化方法来表征扩展效应是有用的。接下来,我们介绍Transformer语言模型的两个代表性缩放定律[30,34]。 |
| KM scaling law5. In 2020, Kaplan et al. [30] (the OpenAI team) firstly proposed to model the power-law relationship of model performance with respective to three major factors, namely model size (N), dataset size (D), and the amount of training compute (C), for neural language models. Given a compute budget c, they empirically presented three basic formulas for the scaling law6: where L(·) denotes the cross entropy loss in nats. The three laws were derived by fitting the model performance with varied data sizes (22M to 23B tokens), model sizes (768M to 1.5B non-embedding parameters) and training compute, under some assumptions (e.g., the analysis of one factor should be not bottlenecked by the other two factors). They showed that the model performance has a strong depen-dence relation on the three factors. | KM缩放定律。2020年,Kaplan等人[30](OpenAI团队)首次提出了神经语言模型的性能与三个主要因素(即模型大小(N)、数据集大小(D)和训练计算量(C))之间的幂律关系建模。给定计算预算c,他们根据不同的数据大小(2200万到230亿个标记)、模型大小(768M到15B个非嵌入参数)和训练计算量,提出了三个基本公式来描述缩放定律6: 其中L(·) 表示用nats计算的交叉熵损失。这三个定律是通过拟合模型性能与不同数据大小、模型大小和训练计算量的关系得出的,在一些假设条件下(例如,一种因素的分析不应被其他两种因素所限制)。他们表明,模型性能与这三个因素有着很强的依赖关系。 |
| Chinchilla scaling law. As another representative study,Hoffmann et al. [34] (the Google DeepMind team) proposed an alternative form for scaling laws to instruct the compute-optimal training for LLMs. They conducted rigorous exper-iments by varying a larger range of model sizes (70M to 16B) and data sizes (5B to 500B tokens), and fitted a similar scaling law yet with different coefficients as below [34]: where E = 1.69, A = 406.4, B = 410.7, α = 0.34 and β = 0.28. By optimizing the loss L(N, D) under the con-straint C ≈ 6ND, they showed that the optimal allocation of compute budget to model size and data size can be derived as follows: where a = α , b = β and G is a scaling coefficient that can be computed by A, B, α and β. | Chinchilla缩放定律。作为另一个代表性研究,Hoffmann等人[34](Google DeepMind团队)提出了另一种缩放定律形式,以指导LLMs的计算最优训练。他们通过变化更大范围的模型大小(70M到16B)和数据大小(5B到500B个标记)进行了严格的实验,并拟合了以下类似的缩放定律,但系数不同[34]: 其中E = 1.69,A = 406.4,B = 410.7,α = 0.34,β = 0.28。通过在约束条件C≈6ND下优化损失L(N,D),他们表明可以导出将计算预算分配给模型大小和数据大小的最优分配方式,如下所示: 其中a = α,b = β,G是一个缩放系数,可由A、B、α和β计算得出。 |
| As analyzed in [34], given an increase in compute budget, the KM scaling law favors a larger budget allocation in model size than the data size, while the Chinchilla scaling law argues that the two sizes should be increased in equal scales, i.e., having similar values for a and b in Equation (3). Though with some restricted assumptions, these scaling laws provide an intuitive understanding of the scaling ef-fect, making it feasible to predict the performance of LLMs during training [46]. However, some abilities (e.g., in-context learning [55]) are unpredictable according to the scaling law, which can be observed only when the model size exceeds a certain level (as discussed below). | 正如[34]所分析的那样,随着计算预算的增加,KM缩放定律更偏向于在模型大小上分配更大的预算量,而Chinchilla缩放定律更偏向于在数据大小上分配更大的预算。 尽管有一些限制性的假设,但这些标度定律提供了对标度效应的直观理解,使得预测llm在训练过程中的表现成为可能[46]。然而,根据缩放定律,有些能力(例如上下文学习[55])是不可预测的,只有当模型大小超过一定水平时才能观察到(如下所述)。 |
Emergent Abilities of LLMs—LLMs涌现能力(小模型超过一定阈值才出现)的三种典型:上下文学习ICL(GPT-3正式引入)、指令跟随IFT(自然语言的指令微调+新任务指令→带来泛化)、逐步推理(基于CoT的提示策略)
| Emergent Abilities of LLMs. In the literature [31], emergent abilities of LLMs are formally defined as “the abilities that are not present in small models but arise in large models”, which is one of the most prominent features that distin-guish LLMs from previous PLMs. It further introduces a notable characteristic when emergent abilities occur [31]: performance rises significantly above random when the scale reaches a certain level. By analogy, such an emergent pattern has close connections with the phenomenon of phase transition in physics [31, 58]. In principle, emergent abilities can be defined in relation to some complex tasks [31, 59], while we are more concerned with general abilities that can be applied to solve a variety of tasks. Here, we briefly introduce three typical emergent abilities for LLMs and representative models that possess such an ability7. | 在文献[31]中,LLMs的涌现能力被正式定义为“在小模型中不存在但在大模型中出现的能力”,这是区分LLMs与以前的PLMs最显著的特征之一。 它进一步引入了突发能力发生时的一个显著特征[31]:当规模达到一定水平时,性能显著高于随机。 由此类推,这种涌现模式与物理学中的相变现象有着密切的联系[31,58]。原则上,涌现能力可以定义为一些复杂的任务[31,59],而我们更关心的是可以解决各种任务的一般能力。在这里,我们简要地介绍了llm的三种典型的突发能力和具有这种能力的代表性模型。 |
| In-context learning. The in-context learning (ICL) ability is formally introduced by GPT-3 [55]: assuming that the language model has been provided with a natural language instruction and/or several task demonstrations, it can gen-erate the expected output for the test instances by com-pleting the word sequence of input text, without requiring additional training or gradient update8. Among the GPT-series models, the 175B GPT-3 model exhibited a strong ICL ability in general, but not the GPT-1 and GPT-2 models. Such an ability also depends on the specific downstream task. For example, the ICL ability can emerge on the arithmetic tasks (e.g., the 3-digit addition and subtraction) for the 13B GPT-3, but 175B GPT-3 even cannot work well on the Persian QA task [31]. | 上下文学习。上下文学习(ICL)能力由GPT-3 [55]正式引入:假设已经为语言模型提供了自然语言指令和/或几个任务演示,它可以通过完成输入文本的单词序列来生成测试实例的预期输出,而无需额外的训练或梯度更新8。在GPT系列模型中,175B GPT-3模型通常具有较强的ICL能力,但GPT-1和GPT-2模型则没有这种能力。这种能力还取决于具体的下游任务。例如,ICL能力可以在算术任务(例如3位数的加减法)中出现,而13B GPT-3可以表现出这种能力,但175B GPT-3却无法良好地处理波斯语QA任务[31]。 |
| Instruction following. By fine-tuning with a mixture of multi-task datasets formatted via natural language descrip-tions (called instruction tuning), LLMs are shown to perform well on unseen tasks that are also described in the form of instructions [28, 61, 62]. With instruction tuning, LLMs are enabled to follow the task instructions for new tasks without using explicit examples, thus having an improved generalization ability. According to the experiments in [62], instruction-tuned LaMDA-PT [63] started to significantly outperform the untuned one on unseen tasks when the model size reached 68B, but not for 8B or smaller model sizes. A recent study [64] found that a model size of 62B is at least required for PaLM to perform well on various tasks in four evaluation benchmarks (i.e., MMLU, BBH, TyDiQA and MGSM), though a much smaller size might suffice for some specific tasks (e.g., MMLU). | 指令跟随。通过使用自然语言描述格式化的多任务数据集的混合进行微调(称为指令微调),LLMs被证明在形式化指令描述的未见任务上表现良好[28, 61, 62]。通过指令微调,LLMs可以在不使用明确示例的情况下遵循新任务的任务指令,从而具有改进的泛化能力。根据[62]中的实验,当模型尺寸达到68B时,指令调优的lambda - pt[63]在看不见的任务上开始显著优于未调优的lambda - pt,而在8B或更小的模型尺寸下则没有。最近的一项研究[64]发现,PaLM至少需要62B的模型尺寸才能在四个评估基准(即MMLU, BBH, TyDiQA和MGSM)中的各种任务上表现良好,尽管对于某些特定任务(例如MMLU),可能需要更小的模型大小。 |
| Step-by-step reasoning. For small language models, it is usually difficult to solve complex tasks that involve multiple reasoning steps, e.g., mathematical word problems. In contrast, with the chain-of-thought (CoT) prompting strategy [33], LLMs can solve such tasks by utilizing the prompting mechanism that involves intermediate reasoning steps for deriving the final answer. This ability is speculated to be potentially obtained by training on code [33, 47]. An empirical study [33] has shown that CoT prompting can bring performance gains (on arithmetic reasoning bench-marks) when applied to PaLM and LaMDA variants with a model size larger than 60B, while its advantage over the standard prompting becomes more evident when the model size exceeds 100B. Furthermore, the performance improvement with CoT prompting seems to be also varied for different tasks, e.g., GSM8K > MAWPS > SWAMP for PaLM [33]. | 逐步推理。对于小型语言模型,通常很难解决涉及多个推理步骤的复杂任务,例如数学文字问题。相比之下,通过思维链(CoT)提示策略[33],LLMs可以通过使用包含中间推理步骤的提示机制来获得最终答案来解决这类任务。这种能力被认为可以通过训练代码来获得[33, 47]。一项实证研究[33]表明,当应用于模型大小大于60B的PaLM和LaMDA变体时,CoT提示可以带来性能提升(在算术推理基准测试中),而当模型大小超过100B时,其优势比标准提示更为明显。此外,对于不同的任务,例如PaLM [33]的GSM8K> MAWPS> SWAMP,使用CoT提示似乎也具有不同的性能改进程度。 |
Key Techniques for LLMs——LLMs的关键技术:规模扩展(Chinchilla【拥有更多训练tokens】优于Gopher【具有更大模型】+数据缩放应伴随着数据清洗过程)、训练技巧(分布式训练【并行策略DeepSpeed和Megatron-LM】+优化技巧【重启+混合精度】)、指令调优(【CoT】诱导潜在能力→涌现能力)、对齐调优(InstructGPT【RLHF】)、加持外部工具插件(计算器/外部引擎等)
| Key Techniques for LLMs. It has been a long way that LLMs evolve into the current state: general and capable learners. In the development process, a number of impor-tant techniques are proposed, which largely improve the capacity of LLMs. Here, we briefly list several important techniques that (potentially) lead to the success of LLMs, as follows. | LLMs的演变历程是漫长的,但最终它们成为了通用和有能力的学习者。在开发过程中,提出了许多重要的技术,这些技术在很大程度上提高了LLMs的容量(能力)。在这里,我们简要列出了几种重要的技术,这些技术(潜在地)导致了LLMs的成功,如下所述。 |
| Scaling. As discussed in previous parts, there exists an evident scaling effect in Transformer language mod-els: larger model/data sizes and more training compute typically lead to an improved model capacity [30, 34]. As two representative models, GPT-3 and PaLM explored the scaling limits by increasing the model size to 175B and 540B, respectively. Since compute budget is usually limited, scaling laws can be further employed to conduct a more compute-efficient allocation of the compute resources. For example, Chinchilla (with more training tokens) outper-forms its counterpart model Gopher (with a larger model size) by increasing the data scale with the same compute budget [34]. In addition, data scaling should be with careful cleaning process, since the quality of pre-training data plays a key role in the model capacity. | 扩展。如前面所述,Transformer语言模型存在明显的扩展效应:更大的模型/数据大小和更多的训练计算通常会导致模型容量的提高。作为两个代表性模型,GPT-3和PaLM通过将模型大小分别增加到了175B和540B,探索了缩放的极限。由于计算预算通常是有限的,缩放定律可以进一步用于更有效地分配计算资源。例如,在相同的计算预算下,Chinchilla(具有更多的训练tokens)通过增加数据规模来优于其对应的模型Gopher(具有更大的模型规模)[34]。此外,由于预训练数据的质量在模型容量中起着关键作用,因此数据缩放应该伴随着仔细的清理过程。 |
| Training. Due to the huge model size, it is very challenging to successfully train a capable LLM. Distributed training algorithms are needed to learn the network param-eters of LLMs, in which various parallel strategies are of-ten jointly utilized. To support distributed training, several optimization frameworks have been released to facilitate the implementation and deployment of parallel algorithms, such as DeepSpeed [65] and Megatron-LM [66–68]. Also, op-timization tricks are also important for training stability and model performance, e.g., restart to overcome training loss spike [56] and mixed precision training [69]. More recently, GPT-4 [46] proposes to develop special infrastructure and optimization methods that reliably predict the performance of large models with much smaller models. | 训练。由于模型尺寸巨大,成功训练一个有能力的LLM是非常具有挑战性的。需要分布式训练算法来学习LLMs的网络参数,其中通常同时使用各种并行策略。 为了支持分布式训练,已经发布了几个优化框架来促进并行算法的实现和部署,如DeepSpeed[65]和Megatron-LM[66-68]。此外,优化技巧对于训练稳定性和模型性能也很重要,例如,重新启动以克服训练损失峰值[56]和混合精度训练[69]。最近,GPT-4[46]提出开发特殊的基础设施和优化方法,用更小的模型可靠地预测大型模型的性能。 |
| Ability eliciting. After being pre-trained on large-scale corpora, LLMs are endowed with potential abilities as general-purpose task solvers. These abilities might not be explicitly exhibited when LLMs perform some specific tasks. As the technical approach, it is useful to design suitable task instructions or specific in-context learning strategies to elicit such abilities. For instance, chain-of-thought prompting has been shown to be useful to solve complex reasoning tasks by including intermediate reasoning steps. Furthermore, we can perform instruction tuning on LLMs with task descriptions expressed in natural language, for improving the generalizability of LLMs on unseen tasks. These eliciting techniques mainly correspond to the emergent abilities of LLMs, which may not show the same effect on small lan-guage models. | 诱导潜在能力。在大规模语料库上预训练后,LLMs被赋予了潜在的能力作为通用任务求解器。这些能力在LLMs执行某些特定任务时可能不会明确展示。作为一种技术方法,设计适当的任务说明或特定上下文学习策略以引导这些能力是有用的。例如,思维链提示已被证明可以通过包含中间推理步骤来解决复杂的推理任务。此外,我们可以使用自然语言表达的任务描述对LLMs进行指令调优,以提高LLMs在未见任务上的泛化性。这些引出技术主要与LLMs的涌现能力相对应,这可能不会在小型语言模型中显示出相同的效果。 |
| Alignment tuning. Since LLMs are trained to capture the data characteristics of pre-training corpora (including both high-quality and low-quality data), they are likely to generate toxic, biased, or even harmful content for humans. It is necessary to align LLMs with human values, e.g., helpful, honest, and harmless. For this purpose, InstructGPT [61] designs an effective tuning approach that enables LLMs to follow the expected instructions, which utilizes the tech-nique of reinforcement learning with human feedback [61, 70]. It incorporates human in the training loop with elaborately designed labeling strategies. ChatGPT is indeed developed on a similar technique to InstructGPT, which shows a strong alignment capacity in producing high-quality, harmless re-sponses, e.g., rejecting to answer insulting questions. | 对齐调优。由于LLMs是为了捕获预训练语料库的数据特征(包括高质量和低质量数据)而训练的,因此它们很可能会对人类产生有毒、有偏见甚至有害的内容。有必要使LLMs与人类价值观保持一致,例如,乐于助人,诚实和无害。为此,InstructGPT[61]设计了一种有效的调优方法,使LLMs能够遵循预期的指令,该方法利用了带有人类反馈的强化学习技术RLHF[61,70]。它将人类与精心设计的标签策略结合在训练循环中。ChatGPT确实是在与InstructGPT类似的技术基础上开发的,后者在产生高质量、无害的响应方面显示出强大的对齐能力,例如,拒绝回答侮辱性的问题。 |
| Tools manipulation. In essence, LLMs are trained as text generators over massive plain text corpora, thus performing less well on the tasks that are not best expressed in the form of text (e.g., numerical computation). In addition, their capacities are also limited to the pre-training data, e.g., the inability to capture up-to-date information. To tackle these issues, a recently proposed technique is to employ external tools to compensate for the deficiencies of LLMs [71, 72]. For example, LLMs can utilize the calculator for accurate computation [71] and employ search engines to retrieve unknown information [72]. More recently, ChatGPT has enabled the mechanism of using external plugins (existing or newly created apps)9, which are by analogy with the “eyes and ears” of LLMs. Such a mechanism can broadly expand the scope of capacities for LLMs. | 加持外部工具。从本质上讲,LLMs被训练为大量纯文本语料库上的文本生成器,因此在不能最好地以文本形式表达的任务(例如,数值计算)上表现不佳。此外,它们的能力也只限于训练前的数据,例如,无法获取最新信息。为了解决这些问题,最近提出的一种技术是使用外部工具来弥补LLMs的不足[71,72]。例如,LLMs可以利用计算器进行精确计算[71],利用搜索引擎检索未知信息[72]。最近,ChatGPT启用了使用外部插件(现有或新创建的应用程序)的机制9,类比于LLMs的“眼睛和耳朵”。这种机制可以广泛扩展LLMs的能力范围。 |
| In addition, many other factors (e.g., the upgrade of hardware) also contribute to the success of LLMs. Currently, we limit our discussion to the major technical approaches and key findings for developing LLMs. | 此外,许多其他因素(例如硬件升级)也有助于LLMs的成功。目前,我们的讨论仅限于开发LLMs的主要技术方法和关键发现。 |
2.2 Technical Evolution of GPT-series Models—GPT系列模型的技术演进
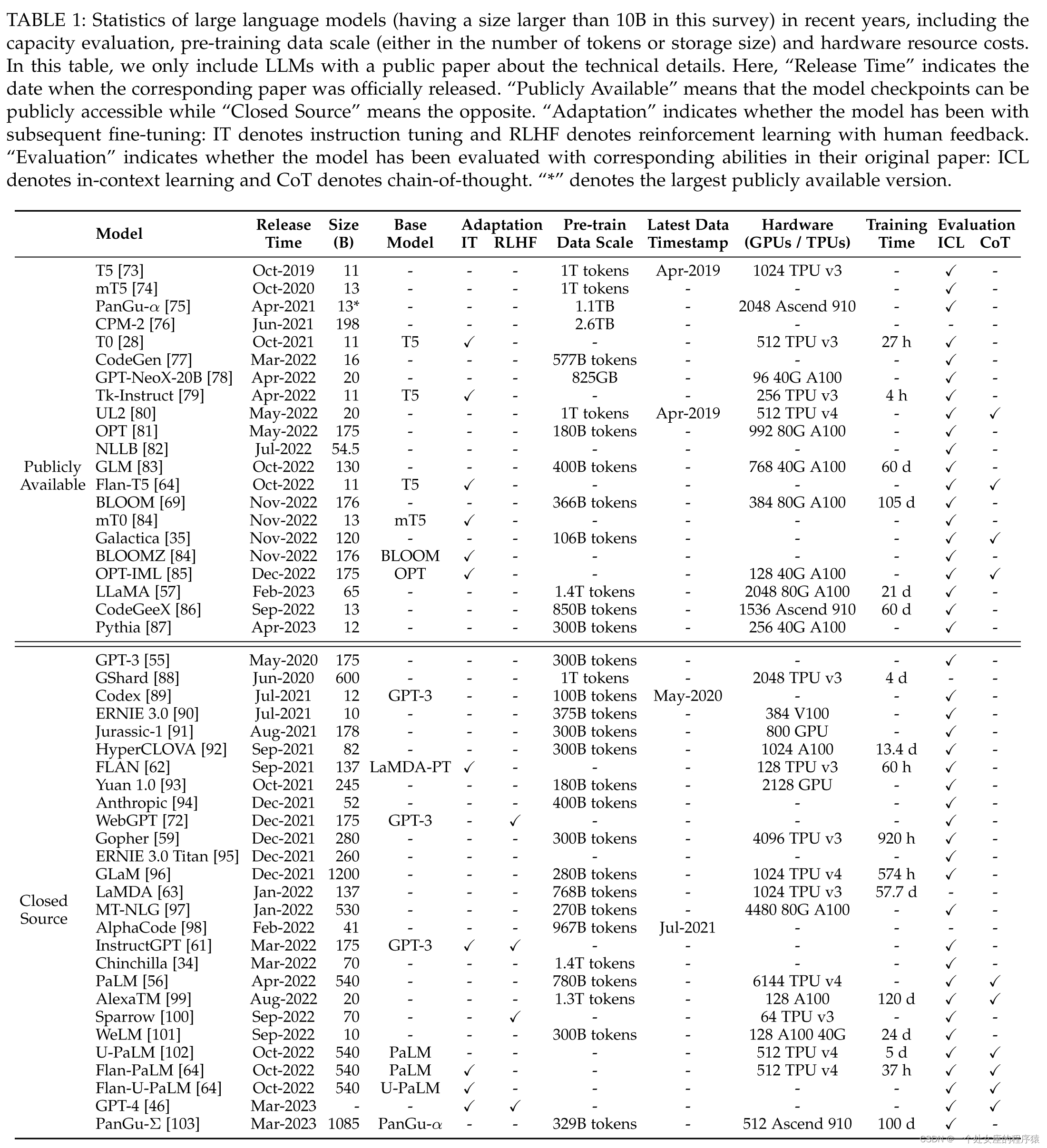
| TABLE 1: Statistics of large language models (having a size larger than 10B in this survey) in recent years, including the capacity evaluation, pre-training data scale (either in the number of tokens or storage size) and hardware resource costs. In this table, we only include LLMs with a public paper about the technical details. Here, “Release Time” indicates the date when the corresponding paper was officially released. “Publicly Available” means that the model checkpoints can be publicly accessible while “Closed Source” means the opposite. “Adaptation” indicates whether the model has been with subsequent fine-tuning: IT denotes instruction tuning and RLHF denotes reinforcement learning with human feedback. “Evaluation” indicates whether the model has been evaluated with corresponding abilities in their original paper: ICL denotes in-context learning and CoT denotes chain-of-thought. “*” denotes the largest publicly available version. | 表1:近年来大型语言模型(本次调查规模大于10B)的统计数据,包括容量评估、预训练数据规模(token数量或存储大小)和硬件资源成本。在这个表中,我们只包括有关于技术细节的公开论文的LLMs。此处的 “发布时间”为相应论文正式发布的日期。 “公开可用”意味着模型检查点可以公开访问,而“闭源”意味着相反的情况。 “调整”表示模型是否进行了后续的微调:IT表示指令调优,RLHF表示有人类反馈的强化学习。 “评估”表示模型是否在其原始论文中被评估过相应的能力:ICL表示上下文学习,CoT表示思维链。 “*”表示最大的公开可用版本。 |
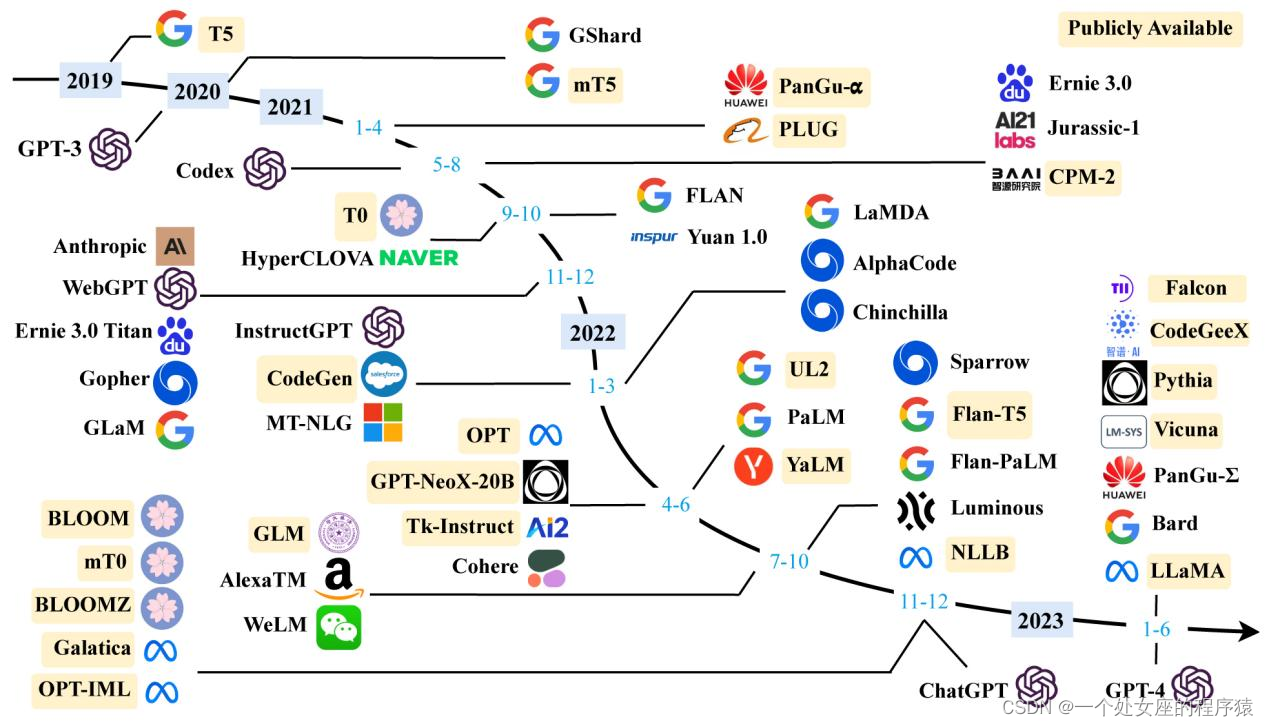
| Fig. 2: A timeline of existing large language models (having a size larger than 10B) in recent years. The timeline was established mainly according to the release date (e.g., the submission date to arXiv) of the technical paper for a model. If there was not a corresponding paper, we set the date of a model as the earliest time of its public release or announcement. We mark the LLMs with publicly available model checkpoints in yellow color. Due to the space limit of the figure, we only include the LLMs with publicly reported evaluation results. | 图2:近年来现有大型语言模型(规模大于10B)的时间轴。时间轴主要根据模型的技术论文的发布日期(例如,提交到arXiv的日期)来确定。如果没有相应的论文,我们将模型的日期设置为其公开发布或公告的最早时间。我们用黄色标记公开可用的模型检查点的LLMs。由于篇幅限制,我们只包括公开报告评估结果的LLMs。 |
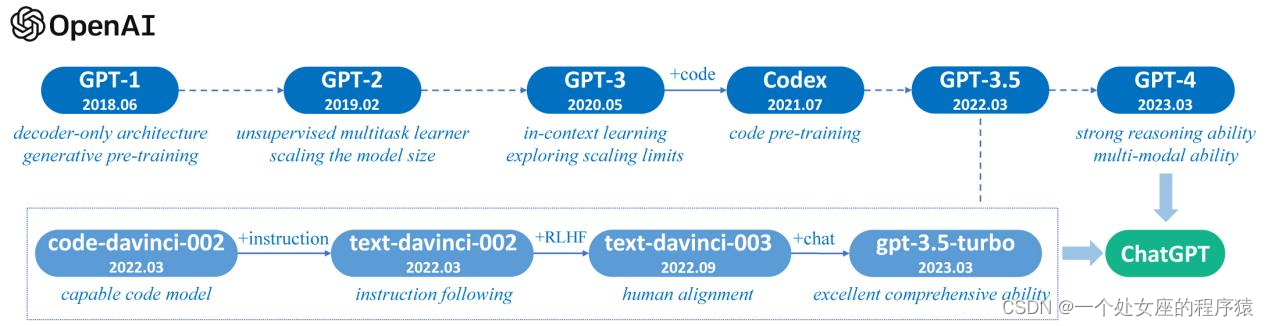
| Fig. 3: A brief illustration for the technical evolution of GPT-series models. We plot this figure mainly based on the papers, blog articles and official APIs from OpenAI. Here, solid lines denote that there exists an explicit evidence (e.g., the official statement that a new model is developed based on a base model) on the evolution path between two models, while dashed lines denote a relatively weaker evolution relation. | 图3:GPT系列模型的技术演进简要说明。我们主要根据OpenAI的论文、博客文章和官方API绘制这张图。这里,实线表示两个模型之间存在明确的演进路径(例如,官方声明新模型是基于基础模型开发的),而虚线表示相对较弱的演进关系。 |
GPT模型成功的两个关键:decoder-only Transformer+扩大LM的规模
| Due to the excellent capacity in communicating with hu-mans, ChatGPT has ignited the excitement of the AI com-munity since its release. ChatGPT is developed based on the powerful GPT model with specially optimized conversation capacities. Considering the ever-growing interest in Chat-GPT and GPT models, we add a special discussion about the technical evolution of the GPT-series models, to briefly summarize the progress how they have been developed in the past years. The basic principle underlying GPT models is to compress the world knowledge into the decoder-only Transformer model by language modeling, such that it can recover (or memorize) the semantics of world knowledge and serve as a general-purpose task solver. Two key points to the success are (I) training decoder-onlly Transformer language models that can accurately predict the next word and (II) scaling up the size of language models. Overall, the research of OpenAI on LLMs can be roughly divided into the following stages10. | 由于ChatGPT具有与人类良好的沟通能力,自发布以来就引发了人工智能社区的兴奋。ChatGPT是基于强大的GPT模型开发的,具有特别优化的对话能力。考虑到人们对Chat-GPT和GPT模型日益增长的兴趣,我们特别讨论了GPT系列模型的技术演变,简要总结了它们在过去几年的发展进展。GPT模型的基本原则是通过语言建模将世界知识压缩到decoder-only Transformer模型中,这样它就可以恢复(或记忆)世界知识的语义,并充当通用任务求解器。成功的两个关键点是: (1)、训练能够准确预测下一个单词的decoder-only Transformer语言模型和 (2)、扩LLMs的规模。 总体而言,OpenAI在LLMs 上的研究大致可以分为以下几个阶段。 |
Early Explorations早期探索:
OpenAI早期的RNN
| Early Explorations. According to one interview with Ilya Sutskever11 (a co-founder and chief scientist of OpenAI), the idea of approaching intelligent systems with language models was already explored in the early days of Ope-nAI, while it was attempted with recurrent neural net-works (RNN) [104]. With the advent of Transformer, OpenAI developed two initial GPT models, namely GPT-1 [105] and GPT-2 [26], which can considered as the foundation to more powerful models subsequently i.e., GPT-3 and GPT-4. | 早期的探索。根据对Ilya Sutskever (OpenAI的联合创始人兼首席科学家)的一次采访,用语言模型接近智能系统的想法在OpenAI的早期就已经被探索过,而那是尝试使用递归神经网络(RNN)[104]实现的。随着Transformer的出现,OpenAI开发了两个最初的GPT模型,即GPT-1 [105]和GPT-2 [26],可以认为它们是后来更强大的模型(即GPT-3和GPT-4)的基础。 |
GPT-1:明确生成式+确定建模基本原理【NSP任务】+采用decoder-only Transformer架构+无监督预训练+监督微调
| GPT-1. In 2017, the Transformer model [22] was intro-duced by Google, and the OpenAI team quickly adapted their language modeling work to this new neural network architecture. They released the first GPT model in 2018, e., GPT-1 [105], and coined the abbreviation term GPT as the model name, standing for Generative Pre-Training. GPT-1 was developed based on a generative, decoder-only Transformer architecture, and adopted a hybrid approach of unsupervised pretraining and supervised fine-tuning. GPT-1 has set up the core architecture for the GPT-series models and established the underlying principle to model natural language text, i.e., predicting the next word. | GPT-1。2017年,谷歌推出了Transformer模型[22],OpenAI团队很快将他们的语言建模工作调整到这种新的神经网络架构上。他们在2018年发布了第一个GPT模型,即GPT-1 [105],并创造了GPT这个缩写术语作为模型名称,代表生成预训练。GPT-1是基于一种生成式的、decoder-only Transformer架构开发的,并采用了无监督预训练和监督微调的混合方法。GPT-1为GPT系列模型奠定了核心架构,并建立了自然语言文本建模的基本原理,即预测下一个单词。 |
GPT-2—无监督多任务学习器:基于WebText数据集+参数扩至1.5B+无监督语言建模ULM代替明确微调(ULM来解决各种任务+统一视为单词预测问题)+采用概率式的多任务求解(输入和任务信息为条件去预测输出)
| GPT-2. Following a similar architecture of GPT-1,GPT-2 [26] increased the parameter scale to 1.5B, which was trained with a large webpage dataset WebText. As claimed in the paper of GPT-2, it sought to perform tasks via unsupervised language modeling, without explicit fine-tuning using labeled data. To motivate the approach, they introduced a probabilistic form for multi-task solving,e., p(output|input, task) (similar approaches have been adopted in [106]), which predicts the output conditioned on the input and task information. To model this conditional probability, language text can be naturally employed as a unified way to format input, output and task information. In this way, the process of solving a task can be cast as a word prediction problem for generating the solution text. Further, they introduced a more formal claim for this idea: “Since the (task-specific) supervised objective is the same as the unsupervised (language modeling) objective but only evaluated on a subset of the sequence, the global minimum of the unsupervised objective is also the global minimum of the supervised objective (for various tasks)” [26]12. A basic understanding of this claim is that each (NLP) task can be considered as the word prediction problem based on a subset of the world text. Thus, unsupervised language modeling could be capable in solving various tasks, if it was trained to have sufficient capacity in recovering the world text. These early discussion in GPT-2’s paper echoed in the interview of Ilya Sutskever by Jensen Huang: “What the neural network learns is some representation of the process that produced the text. This text is actually a projection of the world...the more accurate you are in predicting the next word, the higher the fidelity, the more resolution you get in this process...”13. | GPT-2。在遵循GPT-1相似的架构的同时,GPT-2 [26]将参数规模增加到了1.5B,使用了大型网页数据集WebText进行训练。正如GPT-2的论文中所述,它试图通过无监督的语言建模来执行任务,而不使用标记数据进行明确的微调。为了支持这种方法,他们引入了一种概率形式的多任务求解,即p(output|input, task)(类似的方法已经在[106]中采用),该方法以输入和任务信息为条件预测输出。要建模这个条件概率,语言文本可以自然地用作格式化输入、输出和任务信息的统一方式。通过这种方式,解决任务的过程可以被视为生成解决方案文本的单词预测问题。此外,他们为这个想法引入了一个更正式的声明:“因为(特定于任务的)监督目标与无监督的(语言建模)目标相同,但只在序列的子集上进行评估,所以无监督目标的全局最小值也是各种任务的监督目标的全局最小值(对于各种任务)”[26]12。对这个说法的基本理解是,每个(NLP)任务可以被视为基于世界文本子集的单词预测问题。因此,如果对无监督语言建模进行训练,使其具有足够的恢复世界文本的能力,则无监督语言建模可以解决各种任务。GPT-2论文中的这些早期讨论在Jensen Huang对Ilya Sutskever的采访中也有所体现:“神经网络学到的是生成文本的过程的某种表示。这个文本实际上是世界的一个投影...你在预测下一个单词时越准确,你就会获得更高的保真度,这个过程的分辨率就会更高...”13。 |
Capacity Leap能力的飞跃:GPT2→GPT-3:引入ICL+自然文本来理解任务+带来涌现能力+PLM飞向LLM的高光时刻
| Capacity Leap. Although GPT-2 is intended to be an “un-supervised multitask learner”, it overall has an inferior performance compared with supervised fine-tuning state-of-the-art methods. Because it has a relatively small model size, it has widely fine-tuned in downstream tasks, espe-cially the dialog tasks [107, 108]. Based on GPT-2, GPT-3 demonstrates a key capacity leap by scaling of the (nearly same) generative pre-training architecture. | 虽然GPT-2被设计为“无监督多任务学习器”,但与监督微调的最先进方法相比,它的整体表现较差。由于它的模型规模相对较小,它在下游任务中广泛进行微调,尤其是在对话任务中[107,108]。基于GPT-2,GPT-3通过(几乎相同的)生成式预训练架构的扩展,展示了一个关键的能力飞跃。 |
| GPT-3. GPT-3 [55] was released in 2020, which scaled the model parameters to an ever larger size of 175B. In the GPT-3’s paper, it formally introduced the concept of in-context learning (ICL)14, which utilizes LLMs in a few-shot or zero-shot way. ICL can teach (or instruct) LLMs to understand the tasks in the form of natural language text. With ICL, the pre-training and utilization of LLMs converge to the same language modeling paradigm: pre-training pre-dicts the following text sequence conditioned on the context, while ICL predicts the correct task solution, which can be also formatted as a text sequence, given the task description and demonstrations. GPT-3 not only demonstrates very ex-cellent performance in a variety of NLP tasks, but also on a number of specially designed tasks that require the abilities of reasoning or domain adaptation. Although the GPT-3’s paper does not explicitly discuss the emergent abilities of LLMs, we can observe large performance leap that might transcend the basic scaling law [30], e.g., larger models have significantly stronger ICL ability (illustrated in the original Figure 1.2 of the GPT-3’s paper [55]). Overall, GPT-3 can be viewed as a remarkable landmark in the journey evolving from PLMs to LLMs. It has empirically proved that scaling the neural networks to a significant size can lead to a huge increase in model capacity. | GPT-3在2020年发布,将模型参数扩展到了175B的规模。在GPT-3的论文中,它正式引入了上下文学习(ICL)14的概念,它以少量或零样本的方式利用LLM。ICL可以教导(或指导)LLM以自然语言文本的形式理解任务。通过ICL,LLM的预训练和利用收敛于相同的语言建模范式:预训练预测基于上下文的以下文本序列,而ICL预测正确的任务解决方案,该解决方案也可以格式化为文本序列,给定任务描述和演示。GPT-3不仅在各种NLP任务中表现出非常出色的性能,而且在一些需要推理或领域适应能力的特殊设计任务中也表现出色。虽然GPT-3的论文没有明确讨论LLM的涌现能力,但我们可以观察到庞大的性能飞跃,可能超越基本的缩放定律[30],例如,更大的模型具有显着更强的ICL能力(在GPT-3的原始图1.2中说明)[55]。总体而言,GPT-3可以被视为从PLM到LLM演变历程中的一个显著里程碑。它在经验上证明,将神经网络扩展到显着的规模可以导致模型能力的巨大增加。 |
Capacity Enhancement容量增强——改进GPT-3的两种方法
| Capacity Enhancement. Due to the strong capacities, GPT- 3 has been the base model to develop even more capable LLMs for OpenAI. Overall, OpenAI has explored two major approaches to further improving the GPT-3 model, i.e., train-ing on code data and alignment with human preference, which are detailed as follows. | 由于GPT-3具有强大的能力,它已经成为为OpenAI开发更强大的LLMs 的基础模型。总体而言,OpenAI探索了两种主要方法来进一步改进GPT-3模型,即对代码数据上进行训练和与人类偏好的对齐,具体如下。 |
T1、基于GitHub代码数据微调训练(如Codex/GPT-3.5)
| Training on code data. A major limitation of the original GPT-3 model (pre-trained on plain text) lies in the lack of the reasoning ability on complex tasks, e.g., completing the code and solving math problems. To enhance this ability, Codex [89] was introduced by OpenAI in July 2021, which was a GPT model fine-tuned on a large corpus of GitHub code. It demonstrated that Codex can solve very difficult programming problems, and also lead to a significant per-formance improvement in solving math problems [109]. Further, a contrastive approach [110] to training text and code embedding was reported in January 2022, which was shown to improve a series of related tasks (i.e., linear-probe classification, text search and code search). Actually, the GPT-3.5 models are developed based on a code-based GPT model (i.e., code-davinci-002), which indicates that training on code data is a very useful practice to improve the model capacity of GPT models, especially the reasoning ability. Furthermore, there is also a speculation that train-ing on code data can greatly increase the chain-of-thought prompting abilities of LLMs [47], while it is still worth further investigation with more thorough verification. | 1、在代码数据上进行训练。原始GPT-3模型(在纯文本上进行预训练)的一个主要限制在于缺乏对复杂任务的推理能力,例如完成代码和解决数学问题。为增强这种能力,OpenAI在2021年7月引入了Codex [89],这是一种在大型GitHub代码语料库上进行微调的GPT模型。研究表明,Codex可以解决非常困难的编程问题,并在解决数学问题时显著提高性能[109]。此外,2022年1月报道了一种用于训练文本和代码嵌入的对比方法[110],该方法被证明可以改进一系列相关任务(即,线性探针分类、文本搜索和代码搜索)。实际上,GPT-3.5模型是基于基于代码的GPT模型(即code- davincii -002)开发的,这表明对代码数据的训练是提高GPT模型的建模能力,尤其是推理能力的非常有用的实践。此外,也有人推测,对代码数据进行训练可以大大提高LLMs的思维链提示能力[47],但这仍值得进一步研究,需要更彻底的验证。 |
T2、人类对齐(如RLHF指令调优【PPO+减轻有毒内容】,如InstructGPT,三个方向【训练AI系统使用人类反馈、协助人类评估、对齐研究】)
| Human alignment. The related research of human alignment can be dated back to the year 2017 (or earlier) for OpenAI: a blog article entitled “learning from human preferences”15 was posted on the OpenAI blog describing a work that applied reinforcement learning (RL) to learn from the preference comparisons annotated by humans [70](similar to the reward training step in the aligning algorithm of InstructGPT in Figure 9). Shortly after the release of this RL paper [70], the paper of the Proximal Policy Optimiza-tion (PPO) [111] was published in July 2017, which now has been the foundational RL algorithm for learning from hu-man preferences [61]. Later in January 2020, GPT-2 was fine-tuned using the aforementioned RL algorithms [70, 111], which leveraged human preferences to improve the capac-ities of GPT-2 on NLP tasks. In the same year, another work [112] trained a summarization model for optimizing human preferences in a similar way. Based on these prior work, InstructGPT [61] was proposed in January 2022 to improve the GPT-3 model for human alignment, which formally established a three-stage reinforcement learning from human feedback (RLHF) algorithm. Note that it seems that the wording of “instruction tuning” has seldom been used in OpenAI’s paper and documentation, which is substituted by supervised fine-tuning on human demonstrations (i.e., the first step of the RLHF algorithm [61]). In addition to improving the instruction following capacity, the RLHF algorithm is particularly useful to mitigate the issues of generating harm or toxic content for LLMs, which is key to the safe deploy-ment of LLMs in practice. OpenAI describes their approach to alignment research in a technical article [113], which has summarized three promising directions: “training AI systems to use human feedback, to assist human evaluation and to do alignment research”. | 2、人类对齐。OpenAI对人类对齐的相关研究可以追溯到2017年(或更早):OpenAI博客上发表了一篇题为“从人类偏好中学习”的博客文章[70],描述了一项应用强化学习(RL)从人类标注的偏好比较中学习的工作[70](类似于图9中InstructGPT对齐算法中的奖励训练步骤)。在这篇RL论文发表后不久[70],近端策略优化(PPO)的论文[111]于2017年7月发表。它现在已经成为从人类偏好中学习的基础RL算法[61]。随后在2020年1月,使用上述RL算法[70,111]微调了GPT-2,该算法利用人类偏好来提高GPT-2在NLP任务中的能力。同年,另一项研究[112]以类似的方式训练了一个优化人类偏好的摘要模型。在这些前期工作的基础上,2022年1月提出了InstructGPT[61],用于改进GPT-3人体对准模型,该模型正式建立了一种基于人类反馈的三阶段强化学习(RLHF)算法。请注意,OpenAI的论文和文档中似乎很少使用“指令调优”的措辞,取而代之的是对人类演示的监督微调(即RLHF算法的第一步[61])。除了提高指令跟随能力外,RLHF算法特别有助于减轻LLM生成有害或有毒内容的问题,这是LLM在实践中安全部署的关键。OpenAI在一篇技术文章[113]中描述了他们的对齐研究方法,其中总结了三个有前途的方向:“训练AI系统使用人类反馈,协助人类评估和进行对齐研究”。 |
| These enhancement techniques lead to the improved GPT-3 models with stronger capacities, which are called GPT-3.5 models by OpenAI (see the discussion about the OpenAI API in Section 3.1). | 这些增强技术导致了更具强大能力的GPT-3模型,OpenAI将其称为GPT-3.5模型(请参阅第3.1节中关于OpenAI API的讨论)。 |
The Milestones of Language Models语言模型的里程碑
| The Milestones of Language Models. Based on all the ex-ploration efforts, two major milestones have been achieved by OpenAI, namely ChatGPT [114] and GPT-4 [46], which have largely raised the capacity bar of existing AI systems. | 语言模型的里程碑。基于所有的探索努力,OpenAI取得了两个重要的里程碑,分别是ChatGPT[114]和GPT-4[46],这两个模型在很大程度上提高了现有AI系统的能力水平。 |
ChatGPT(语言模型的里程碑):InstructGPT的姊妹模型+专门优化对话+支持插件+卓越能力(知识储备+数学推理+多轮追踪+对齐人类)
| ChatGPT. In November 2022, OpenAI released the conversation model ChatGPT, based on the GPT models (GPT-3.5 and GPT-4). As the official blog article intro-duced [114], ChatGPT was trained in a similar way as InstructGPT (called “a sibling model to InstructGPT” in the original post), while specially optimized for dialogue. They reported a difference between the training of ChatGPT and InstructGPT in the data collection setup: human-generated conversations (playing both the roles of user and AI) are combined with the InstructGPT dataset in a dialogue format for training ChatGPT. ChatGPT exhibited superior capaci-ties in communicating with humans: possessing a vast store of knowledge, skill at reasoning on mathematical problems, tracing the context accurately in multi-turn dialogues, and aligning well with human values for safe use. Later on, the plugin mechanism has been supported in ChatGPT, which further extends the capacities of ChatGPT with existing tools or apps. So far, it seems to be the ever most powerful chatbot in the AI history. The launch of ChatGPT has a significant impact on the AI research in the future, which sheds light on the exploration of human-like AI systems. | ChatGPT。2022年11月,OpenAI发布了基于GPT模型(GPT-3.5和GPT-4)的对话模型ChatGPT。正如官方博客文章[114]所介绍的那样,ChatGPT的训练方式与InstructGPT相似(在原始帖子中被称为“InstructGPT的姊妹模型”),但专门针对对话进行了优化。他们报告了ChatGPT和InstructGPT在数据收集设置上的训练差异:将人类生成的对话(扮演用户和AI的双重角色)与InstructGPT数据集以对话格式组合起来,用于训练ChatGPT。ChatGPT在与人类的交流中表现出卓越的能力:拥有丰富的知识储备,在数学问题的推理能力方面表现出色,在多轮对话中准确追踪上下文,并与人类价值观保持良好的一致性,以确保安全使用。后来,ChatGPT支持了插件机制,进一步扩展了ChatGPT与现有工具或应用程序的能力。到目前为止,它似乎是人工智能历史上最强大的聊天机器人。ChatGPT的推出对未来人类化AI系统的探索具有重要影响。 |
GPT-4:多模态+6个月的迭代对齐(RLHF+额外的安全奖励信号)+多种干预策略来降幻觉和隐私(红队测试)+完善的DL基础设施+新机制(可预测的缩放→少量的计算来准确预测最终性能)
| GPT-4. As another remarkable progress, GPT-4 [46] was released in March 2023, which extended the text input to multimodal signals. Overall, GPT-4 has stronger capacities in solving complex tasks than GPT-3.5, showing a large performance improvement on many evaluation tasks. A re-cent study [41] investigated the capacities of GPT-4 by con-ducting qualitative tests with human-generated problems, spanning a diverse range of difficult tasks, and showed that GPT-4 can achieve more superior performance than prior GPT models such as ChatGPT. Furthermore, GPT-4 responds more safely to malicious or provocative queries, due to a six-month iterative alignment (with an additional safety reward signal in the RLHF training). In the technical report, OpenAI has emphasized how to safely develop GPT-4 and applied a number of intervention strategies to mitigate the possible issues of LLMs, such as hallucinations, privacy and overreliance. For example, they introduced the mechanism called red teaming [115] to reduce the harm or toxic content generation. As another important aspect, GPT- 4 has been developed on a well-established deep learning infrastructure with improved optimization methods. They introduced a new mechanism called predictable scaling that can accurately predict the final performance with a small proportion of compute during model training. | GPT-4。另一个值得注意的进展是于2023年3月发布的GPT-4[46],将文本输入扩展到多模态信号。总体而言,GPT-4在解决复杂任务方面的能力比GPT-3.5更强,显示出在许多评估任务上的大幅性能提升。最近的一项研究[41]通过人类生成的问题进行了定性测试,涵盖了各种难度的任务,显示出GPT-4可以比之前的GPT模型(如ChatGPT)实现更优越的性能。此外,由于进行了为期六个月的迭代对齐(在RLHF训练中增加了额外的安全奖励信号),GPT-4对恶意或挑衅性查询的响应更加安全。在技术报告中,OpenAI强调了如何安全地开发GPT-4,并采用了多种干预策略来缓解LLMs可能出现的问题,如幻觉、隐私和过度依赖等。例如,他们引入了称为“红队测试”[115]的机制,以减少有害或毒性内容的生成。作为另一个重要方面,GPT-4是在一个完善的深度学习基础设施上开发的,改进了优化方法。他们引入了一种新的机制,称为可预测的缩放新机制,可以在模型训练期间使用少量的计算准确预测最终的性能。 |
| Despite the huge progress, there are still limitations with these superior LLMs, e.g., generating hallucinations with factual errors or potentially risky response within some specific context [46]. More limitations or issues of LLMs will be discussed in Section 7. It poses long-standing research challenges to develop more capable, safer LLMs. From the perspective of engineering, OpenAI has adopted an iterative deployment strategy [116] to develop the models and products by following a five-stage development and deployment life-cycle, which aims to effectively reduce the potential risks of using the models. In the following, we will dive into the technical details in order to have a specific understanding of how they have been developed. | 尽管有巨大的进展,这些优秀的LLMs仍然存在一些限制,例如在某些特定的上下文中产生具有事实错误或潜在风险的幻觉回应[46]。关于LLMs的更多限制或问题将在第7节中讨论。开发更具能力和安全性的LLMs是一个长期的研究挑战。从工程的角度来看,OpenAI采用了迭代部署策略[116]来开发模型和产品,遵循五个阶段的开发和部署生命周期,旨在有效地降低模型使用的潜在风险。接下来,我们将深入探讨技术细节,以便对它们是如何开发的有一个具体的了解。 |
3 Resources Of Llms—Llms的资源(开源模型/闭源API+六类语料库+三种代码库)
| It is by no means an easy job to develop or reproduce LLMs, considering the challenging technical issues and huge de-mands of computation resources. A feasible way is to learn experiences from existing LLMs and reuse publicly avail-able resources for incremental development or experimental study. In this section, we briefly summarize the publicly available resources for developing LLMs, including model checkpoints (or APIs), corpora and libraries. | 考虑到具有挑战性的技术问题和对计算资源的巨大需求,开发或复制LLMs绝非易事。一种可行的方法是从现有的LLMs中学习经验,并重复使用公开可用的资源进行增量开发或实验研究。在本节中,我们简要总结了用于开发LLMs的公开可用资源,包括模型检查点(或API)、语料库和库。 |
3.1 Publicly Available Model Checkpoints or APIs——公开可用的模型检查点或API
| Given the huge cost of model pre-training, well-trained model checkpoints are critical to the study and development of LLMs for the research community. Since the parameter scale is a key factor to consider for using LLMs, we cate-gorize these public models into two scale levels (i.e., tens of billions of parameters and hundreds of billions of parameters), which is useful for users to identify the suitable resources ac-cording to their resource budget. In addition, for inference, we can directly employ public APIs to perform our tasks, without running the model locally. Next, we introduce the publicly available model checkpoints and APIs. | 考虑到模型预训练的巨大成本,训练良好的模型检查点对于研究社区的LLMs的研究和开发至关重要。由于参数规模是使用LLMs的关键因素,我们将这些公共模型分为两个规模级别(即数百亿参数和数千亿参数),这有助于用户根据其资源预算确定合适的资源。此外,对于推理,我们可以直接使用公共API执行任务,而无需在本地运行模型。接下来,我们介绍公开可用的模型检查点和API。 |
10B~Models with Tens of Billions of Parameters—数百亿参数的模型(开源非常多)
指令调优(Flan-T5)、代码生成(CodeGen)、多语言任务(mT0)
| Models with Tens of Billions of Parameters. Most of the models in this category have a parameter scale ranging from 10B to 20B, except LLaMA [57] (containing 65B parameters in the largest version), NLLB [82] (containing 54.5B parame-ters in the largest version), and Falcon [117] (containing 40B parameters in the largest version). Other models within this range include mT5 [74], PanGu-α [75], T0 [28], GPT-NeoX-20B [78], CodeGen [77], UL2 [80], Flan-T5 [64], and mT0 [84]. Among them, Flan-T5 (11B version) can serve as a premier model for research on instruction tuning, since it explores the instruction tuning from three aspects [64]: increasing the number of tasks, scaling the model size, and fine-tuning with chain-of-thought prompting data. Be-sides, CodeGen (11B version), as an autoregressive language model designed for generating code, can be considered as a good candidate for exploring the code generation ability. It also introduces a new benchmark MTPB [77] specially for multi-turn program synthesis, which is composed by 115 expert-generated problems. To solve these problems, it re-quires LLMs to acquire sufficient programming knowledge (e.g., math, array operations, and algorithms). As for multi-lingual tasks, mT0 (13B version) might be a good candidate model, which has been fine-tuned on multilingual tasks with multilingual prompts. Furthermore, PanGu-α [75] shows good performance in Chinese downstream tasks in zero-shot or few-shot settings, which is developed based on the deep learning framework MindSpore [118]. Note that PanGu-α [75] holds multiple versions of models (up to 200B parameters), while the largest public version has 13B parameters. | 大多数此类模型的参数规模在10B到20B之间,除了LLaMA [57](最大版本包含65B参数)、NLLB [82](最大版本包含54.5B参数)和Falcon [117](最大版本包含40B参数)之外。此范围内的其他模型包括mT5 [74]、PanGu-α [75]、T0 [28]、GPT-NeoX-20B [78]、CodeGen [77]、UL2 [80]、Flan-T5 [64]和mT0 [84]。 其中,Flan-T5(11B版本)可作为研究指令调优的首选模型,因为它从三个方面探索了指令调优:增加任务数量、扩展模型规模和使用思维链提示数据进行微调[64]。 此外,CodeGen(11B版本)作为用于生成代码的自回归语言模型,可以被视为探索代码生成能力的良好候选模型。它还引入了一个新的MTPB基准[77],专门用于多轮程序合成,由115个专家生成的问题组成。为了解决这些问题,需要LLMs获得足够的编程知识(例如,数学、数组操作和算法)。 对于多语言任务,mT0(13B版本)可能是一个良好的候选模型,它已经在多语言提示下进行了微调。 此外,基于深度学习框架MindSpore [118]开发的PanGu-α [75]在零样本或少样本情况下在中文下游任务中表现良好。请注意,PanGu-α [75]拥有多个模型版本(最高可达200B参数),而最大的公共版本有13B参数。 |
LLaMA的两个优化方向(微调、增量预训练)、Falcon(注重数据清洗)
| As a popular LLM, LLaMA (65B version) [57], which contains approximately five times as many parame-ters as other models, has exhibited superior performance in tasks related to instruction following. Due to the openness and effectiveness, LLaMA has attracted significant attention from the research community, and many efforts [119–122] have been devoted to fine-tuning or continually pre-training its different model versions for implementing new models or tools. More recently, Falcon [117], as another open-source LLM, has also achieved very excellent performance on open benchmarks. It is featured by a more careful data cleaning process to prepare the pre-training data (with a publicly shared dataset RefinedWeb [123]). | 作为一种流行的LLM,LLaMA(65B版本)[57],其包含的参数大约是其他模型的5倍,在指令遵循相关任务中表现出了优越的性能。由于其开放性和有效性,LLaMA已经引起了研究社区的重视,许多工作[119-122]已经致力于微调或持续预训练其不同的模型版本,以实现新模型或工具的实现。 最近,Falcon[117]作为另一个开源LLM,也在开放基准测试中取得了非常出色的性能。它的特点是采用更加谨慎的数据清洗过程来准备预训练数据(使用公开共享的数据集RefinedWeb [123])。 |
预训练硬件(数百上千的GPU)—LLaMA采用2048个A100、FLOPS衡量
| Typically, pre-training models at this scale require hundreds or even thousands of GPUs or TPUs. For instance, GPT-NeoX-20B uses 12 supermicro servers, each equipped with 8 NVIDIA A100-SXM4-40GB GPUs, while LLaMA utilizes 2,048 A100- 80G GPUs as reported in their original publications. To accurately estimate the computation resources needed, it is suggested to use the metrics measuring the number of involved computations such as FLOPS (i.e., FLoating point number Operations Per Second) [30]. | 通常,这个规模的预训练模型需要数百甚至数千个GPU或TPU。例如,GPT-NeoX-20B使用12个超微服务器,每个服务器配备8个NVIDIA A100-SXM4-40GB GPU,而LLaMA在其原始出版物中报告使用了2048个A100-80G GPU。为了准确估计所需的计算资源,建议使用衡量涉及计算量的指标,例如FLOPS(即每秒浮点数操作次数)[30]。 |
LLaMA研究工作的演化图
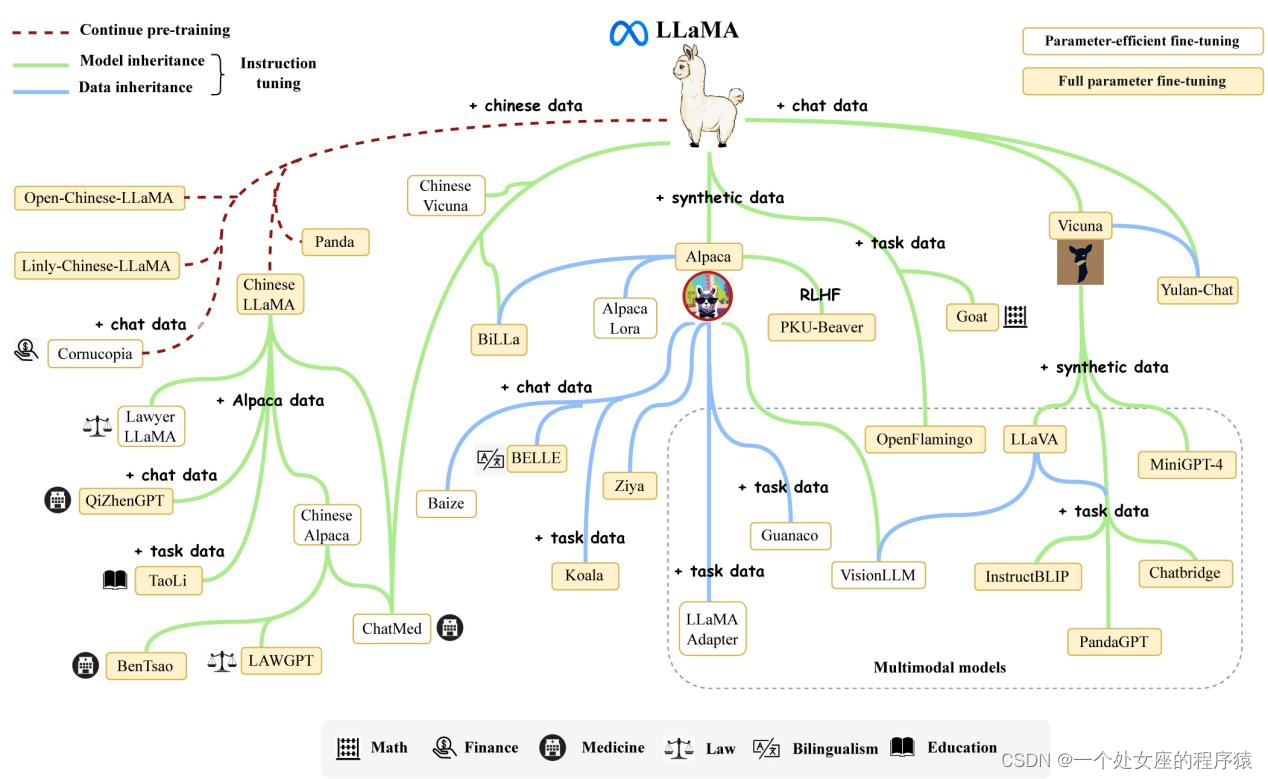
| Fig. 4: An evolutionary graph of the research work conducted on LLaMA. Due to the huge number, we cannot include all the LLaMA variants in this figure, even much excellent work. To support incremental update, we share the source file of this figure, and welcome the readers to include the desired models by submitting the pull requests on our GitHub page. | 图4:LLaMA研究工作的演化图。由于数量庞大,我们无法将所有的LLaMA变体包括在这个数字中,即使是非常优秀的作品。为了支持增量更新,我们分享了这个图的源文件,并欢迎读者通过在我们的GitHub页面上提交拉取请求来包含所需的模型。 |
100B~Models with Hundreds of Billions of Parameters数千亿参数的模型(少数开源)
OPT、跨语言泛化(BLOOM)、双语(GLM及其中文聊天模型ChatGLM2-6B)
| Models with Hundreds of Billions of Parameters. For models in this category, only a handful of models have been publicly released. For example, OPT [81], OPT-IML [85], BLOOM [69], and BLOOMZ [84] have nearly the same num-ber of parameters as GPT-3 (175B version), while GLM [83] and Galactica [35] have 130B and 120B parameters, re-spectively. Among them, OPT (175B version), with the instruction-tuned version OPT-IML, has been specially mo-tivated for open sharing, which aims to enable researchers to carry out reproducible research at scale. For research in cross-lingual generalization, BLOOM (176B version) and BLOOMZ (176B version) can be used as base models, due to the competence in multilingual language modeling tasks. As a bilingual LLM, GLM has also provided a popular small-sized Chinese chat model ChatGLM2-6B (a updated version for ChatGLM-6B), which is featured with many improvements in efficiency and capacity (e.g., quantization, 32K-length context, fast inference rate). | 在这个类别中,只有少数模型已经公开发布。例如,OPT [81]、OPT-IML [85]、BLOOM [69]和BLOOMZ [84]的参数数量几乎与GPT-3(175B版本)相同,而GLM [83]和Galactica [35]的参数数量分别为130B和120B。 其中,OPT(175B版本)及其指令调优版本OPT-IML,已经被特别激励进行开放共享,旨在使研究人员能够进行可重复的大规模研究。 对于跨语言泛化的研究,由于其在多语言语言建模任务中的能力,BLOOM(176B版本)和BLOOMZ(176B版本)可用作基础模型。 作为一种双语LLM,GLM还提供了一个流行的小型中文聊天模型ChatGLM2-6B(ChatGLM-6B的更新版本),其特点是在效率和容量方面进行了许多改进(例如量化、32K长度的上下文、快速推理速度)。 |
预训练硬件(上千的GPU)—OPT采用992个A100、GLM采用96节点*8个A100
| Models of this scale typically require thousands of GPUs or TPUs to train. For instance, OPT (175B version) used 992 A100-80GB GPUs, while GLM (130B version) used a cluster of 96 NVIDIA DGX-A100 (8x40G) GPU nodes. | 这个规模的模型通常需要数千个GPU或TPU进行训练。例如,OPT(175B版本)使用了992个A100-80GB GPU,而GLM(130B版本)使用了96个NVIDIA DGX-A100(8x40G)GPU节点。 |
LLaMA Model Family——LLaMA模型系列
LLaMA系列:基于LLaMA架构的优化(指令微调/持续预训练)、非英语场景优化(扩展词表+基于目标语言数据微调)
| LLaMA Model Family. The collection of LLaMA mod-els [57] were introduced by Meta AI in February, 2023, consisting of four sizes (7B, 13B, 30B and 65B). Since released, LLaMA has attracted extensive attention from both research and industry communities. LLaMA mod-els have achieved very excellent performance on various open benchmarks, which have become the most popu-lar open language models thus far. A large number of researchers have extended LLaMA models by either in-struction tuning or continual pretraining. In particular, in-struction tuning LLaMA has become a major approach to developing customized or specialized models, due to the relatively low computational costs. To effectively adapt LLaMA models in non-English languages, it often needs to extend the original vocabulary (trained mainly on English corpus) or fine-tune it with instructions or data in the target language. | LLaMA模型系列。LLaMA模型系列由Meta AI于2023年2月推出,包括四种规模(7B、13B、30B和65B)。 自发布以来,LLaMA已经引起了研究和工业界的广泛关注。LLaMA模型在各种开放基准测试中表现非常出色,成为迄今为止最受欢迎的开放语言模型。 大量研究人员通过指令微调或持续预训练扩展了LLaMA模型。特别是指令微调LLaMA已成为开发定制或专业化模型的主要方法,因为相对计算成本较低。为了有效地在非英语语言中适应LLaMA模型,通常需要扩展原始词汇(主要在英语语料库上训练)或使用目标语言的指令或数据进行微调。 |
Alpaca:LLaMA +52K指令数据(text-davinci-003生成)
Alpaca-LoRA:Alpaca+LoRA 微调、Koala 、BELLE
| Among these extended models, Stanford Alpaca [124] is the first open instruct-following model fine-tuned based on LLaMA (7B). It is trained by 52K instruction-following demonstrations generated via self-instruct [125] using text-davinci-003. The instruction data, named Alpaca-52K, and training code have been ex-tensively adopted in subsequent work, such as Alpaca-LoRA [126] (a reproduction of Stanford Alpaca using LoRA [127]), Koala [128], and BELLE [129]. | 在这些扩展模型中,斯坦福大学的 Alpaca [124]是第一个基于LLaMA(7B)微调的开放指令遵循模型。它通过使用text-davinci-003生成的52000个自我指令遵循演示进行训练。指令数据名为Alpaca-52K,训练代码已被广泛采用于后续的工作,如Alpaca-LoRA [126](使用LoRA [127]重现斯坦福Alpaca),Koala [128]和BELLE [129]。 |
Vicuna:LLaMA +ShareGPT收集对话→多模态+→LLaVA、MiniGPT-4、InstructBLIP、PandaGPT
| In addition, Vicuna [120] is another popular LLaMA variant, trained upon user-shared conversations collected from ShareGPT 16. Due to the excellent performance and availability of the LLaMA model family, many multimodal models incorpo-rate them as the base language models, to achieve strong language understanding and generation abilities. Compared with other variants, Vicuna is more preferred in multimodal language models, which have led to the emergence of a va-riety of popular models, including LLaVA [130], MiniGPT- 4 [131], InstructBLIP [132], and PandaGPT [133]. The re-lease of LLaMA has greatly advanced the research progress of LLMs. To summarize the research work conducted on LLaMA, we present a brief evolutionary graph in Figure 4. | 此外,Vicuna [120]是另一个流行的LLaMA变体,它基于从ShareGPT 16收集的用户共享对话进行训练。由于LLaMA模型系列的出色性能和可用性,许多多模态模型将它们作为基础语言模型,以实现强大的语言理解和生成能力。与其他变体相比,Vicuna在多模态语言模型中更受欢迎,这导致了许多流行模型的出现,包括LLaVA [130],MiniGPT-4 [131],InstructBLIP [132]和PandaGPT [133]。 LLaMA的发布极大地推动了LLM的研究进展。为了总结对LLaMA进行的研究工作,我们在图4中呈现了一个简要的演化图。 |
Public API of LLMs——LLMs的公共API:比如OpenAI的GPT-3/GPT-4系列、Codex
| Public API of LLMs. Instead of directly using the model copies, APIs provide a more convenient way for common users to use LLMs, without the need of running the model locally. As a representative inter-face for using LLMs, the APIs for the GPT-series mod-els [46, 55, 61, 89] have been widely used for both academia and industry17. OpenAI has provided seven major interfaces to the models in GPT-3 series: ada, babbage, curie, davinci (the most powerful version in GPT-3 series), text-ada-001, text-babbage-001, and text-curie-001. Among them, the first four interfaces can be further fine-tuned on the host server of OpenAI. In particular, babbage, curie, and davinci correspond to the GPT-3 (1B), GPT-3 (6.7B), and GPT-3 (175B) models, respectively [55]. In addition, there are also two APIs re-lated to Codex [89], called code-cushman-001 (a power-ful and multilingual version of the Codex (12B) [89]) and code-davinci-002. Further, GPT-3.5 series include one base model code-davinci-002 and three enhanced ver-sions, namely text-davinci-002, text-davinci-003, and gpt-3.5-turbo-0301. It is worth noting that gpt-3.5-turbo-0301 is the interface to invoke Chat-GPT. More recently, OpenAI has also released the corre-sponding APIs for GPT-4, including gpt-4, gpt-4-0314, gpt-4-32k, and gpt-4-32k-0314. Overall, the choice of API interfaces depends on the specific application scenarios and response requirements. The detailed usage can be found on their project websites18. | LLMs的公共API。与直接使用模型副本不同,API提供了一种更方便的方式供普通用户使用LLMs,无需在本地运行模型。作为使用LLMs的代表性接口,GPT系列模型的API [46, 55, 61, 89]已经被学术界和工业界广泛使用17。 OpenAI为GPT-3系列的模型提供了七个主要接口:ada、babbage、curie、davinci(GPT-3系列中最强大的版本)、text-ada-001、text-babbage-001和text-curie-001。其中,前四个接口可以在OpenAI的主机服务器上进一步微调。特别地,babbage、curie和davinci分别对应于GPT-3(1B)、GPT-3(6.7B)和GPT-3(175B)模型[55]。 此外,还有两个与Codex [89]相关的API,称为code-cushman-001(Codex(12B)的强大且多语言版本[89])和code-davinci-002。此外,GPT-3.5系列包括一个基础模型code-davinci-002和三个增强版本,即text-davinci-002、text-davinci-003和gpt-3.5-turbo-0301。值得注意的是,gpt-3.5-turbo-0301是调用Chat-GPT的接口。 最近,OpenAI还发布了与GPT-4相关的相应API,包括gpt-4、gpt-4-0314、gpt-4-32k和gpt-4-32k-0314。总体而言,API接口的选择取决于具体的应用场景和响应要求。详细的使用方法可以在它们的项目网站上找到18。 |
3.2 Commonly Used Corpora常用的六类语料库
| In contrast to earlier PLMs, LLMs which consist of a signifi-cantly larger number of parameters require a higher volume of training data that covers a broad range of content. For this need, there are increasingly more accessible training datasets that have been released for research. In this section, we will briefly summarize several widely used corpora for training LLMs. Based on their content types, we catego-rize these corpora into six groups: Books, CommonCrawl, Reddit links, Wikipedia, Code, and others. | 与早期的PLM相比,包含大量参数的LLM需要大量的训练数据,涵盖广泛的内容类型。为了满足这一需求,研究人员已经发布了越来越多的可访问的训练数据集。 在本节中,我们将简要概述用于训练LLM的几个广泛使用的语料库。根据它们的内容类型,我们将这些语料库分为六类:书籍、CommonCrawl、Reddit链接、维基百科、代码和其他。 |
(1)、Books书籍类:BookCorpus(1.1W本,如GPT-1/GPT-2)、Project Gutenberg(7W本,如MT-NLG/LLaMA)、Books1_2(未公开,如GPT-3)
| Books. BookCorpus [134] is a commonly used dataset in previous small-scale models (e.g., GPT [105] and GPT-2 [26]), consisting of over 11,000 books covering a wide range of topics and genres (e.g., novels and biographies). Another large-scale book corpus is Project Gutenberg [135], consist-ing of over 70,000 literary books including novels, essays, poetry, drama, history, science, philosophy, and other types of works in the public domain. It is currently one of the largest open-source book collections, which is used in train-ing of MT-NLG [97] and LLaMA [57]. As for Books1 [55] and Books2 [55] used in GPT-3 [55], they are much larger than BookCorpus but have not been publicly released so far. | 书籍. BookCorpus [134] 是先前小型模型(如GPT [105] 和GPT-2 [26])中常用的数据集,包含超过11,000本图书,涵盖各种主题和体裁(如小说和传记)。 另一个大型图书语料库是Project Gutenberg [135],包含超过70,000份文学图书,包括小说、论文、诗歌、戏剧、历史、科学、哲学等公共领域的作品。它是目前最大的开放源码图书集合之一,用于MT-NLG [97] 和LLaMA [57] 的训练。 至于GPT-3 [55] 中使用的Books1 [55] 和Books2 [55],它们比BookCorpus大得多,但迄今为止尚未公开发布。 |
(2)、CommonCrawl开源网络爬虫数据库类(PB级别):过滤后的四类常用数据集(C4多语言版【45T】/CC-Stories故事的形式【31G】/CC-News新闻语料【120G】/RealNews新闻语料【76G】)
| CommonCrawl. CommonCrawl [144] is one of the largest open-source web crawling databases, containing a petabyte-scale data volume, which has been widely used as training data for existing LLMs. As the whole dataset is very large, existing studies mainly extract subsets of web pages from it within a specific period. However, due to the widespread existence of noisy and low-quality information in web data, it is necessary to perform data preprocessing before usage. Based on CommonCrawl, there are four filtered datasets that are commonly used in existing work: C4 [73], CC-Stories [136], CC-News [27], and RealNews [137]. The Colos-sal Clean Crawled Corpus (C4) includes five variants19, namely en (806G), en.noclean (6T), realnewslike (36G), web-textlike (17G), and multilingual (38T). The en version has been utilized for pre-training T5 [73], LaMDA [63], Go-pher [59], and UL2 [80]. The multilingual C4, also called mC4, has been used in mT5 [74]. CC-Stories (31G) is com-posed of a subset of CommonCrawl data, in which the contents are made in a story-like way. Because the original source of CC-Stories is not available now, we include a re-production version, CC-Stories-R [145], in Table 2. Moreover, two news corpora extracted from CommonCrawl, i.e., RE-ALNEWS (120G) and CC-News (76G), are also commonly used as the pre-training data. | CommonCrawl. CommonCrawl [144] 是最大的开源网络爬虫数据库之一,包含一个PB规模的数据量,被广泛用作现有LLM的训练数据。由于整个数据集非常庞大,现有研究主要从特定时期提取Web页面的子集进行使用。然而,由于网络数据中普遍存在噪声和低质量信息,因此在使用之前必须对数据进行预处理。 基于CommonCrawl,有四个过滤后的数据集在现有工作中被广泛使用:C4 [73],CC-Stories [136],CC-News [27] 和RealNews [137]。C4[73] 是一个多语言版本的过滤文本数据集,包括英语(806G)、en.noclean(6T)、realnewslike(36G)、web-textlike(17G)和multilingual(38T)。英语版本已用于预训练T5 [73] 、LaMDA [63] 、Go-pher [59] 和UL2 [80]。名为mC4的多语言C4也用于mT5 [74] 的训练。 CC-Stories (31G) 是由CommonCrawl数据构成的子集,其中内容以故事的形式呈现。由于CC-Stories原始来源目前不可用,我们在表2中包含了一个重现版本CC-Stories-R [145]。 此外,从CommonCrawl提取的两个新闻语料库RE-ALNEWS (120G) 和CC-News (76G) 也通常作为预训练数据使用。 |
(3)、Reddit Links社交媒体平台类:WebText高赞链接语料库(未公开但有替代品OpenWebText)、 PushShift(实时更新)
| Reddit Links. Reddit is a social media platform that enables users to submit links and text posts, which can be voted on by others through “upvotes” or “downvotes”. Highly up-voted posts are often considered useful, and can be utilized to create high-quality datasets. WebText [26] is a well-known corpus composed of highly upvoted links from Reddit, but it is not publicly available. As a surrogate, there is a readily ac-cessible open-source alternative called OpenWebText [138]. Another corpus extracted from Reddit is PushShift.io [139], a real-time updated dataset that consists of historical data from Reddit since its creation day. Pushshift provides not only monthly data dumps but also useful utility tools to support users in searching, summarizing, and conducting preliminary investigations on the entire dataset. This makes it easy for users to collect and process Reddit data. | Reddit Links. Reddit是一个社交媒体平台,用户可以提交链接和文本帖子,其他人可以通过“点赞”或“踩”对其进行投票。高赞的帖子通常被认为是有用的,可以用于创建高质量的数据集。WebText [26] 是由来自Reddit的高赞链接组成的著名语料库,但目前不公开可用。作为替代方案,有一个容易访问的开源替代品叫OpenWebText [138]。 另一个从Reddit提取的语料库是PushShift.io [139],这是一个实时更新的数据集,自其创建之日起就包含了来自Reddit的历史数据。Pushshift不仅提供每月数据转储,还提供了有用的实用工具,以支持用户在对整个数据集进行搜索、摘要和初步调查时使用。这使得用户收集和处理Reddit数据变得容易。 |
(4)、Wikipedia百科全书类:比如GPT-3/LaMDA/LLaMA
| Wikipedia. Wikipedia [140] is an online encyclopedia con-taining a large volume of high-quality articles on diverse topics. Most of these articles are composed in an expository style of writing (with supporting references), covering a wide range of languages and fields. Typically, the English-only filtered versions of Wikipedia are widely used in most LLMs (e.g., GPT-3 [55], LaMDA [63], and LLaMA [57]). Wikipedia is available in multiple languages, so it can be used in multilingual settings. | Wikipedia. Wikipedia是一个在线百科全书,包含大量关于各种主题的高质量文章。其中大部分文章采用说明性写作风格(带支持性参考文献),涵盖广泛的语言和领域。通常,英语过滤版本的维基百科在大多数LLM中被广泛使用(例如,GPT-3 [55],LaMDA [63]和LLaMA [57])。维基百科提供多种语言版本,因此可用于多语言环境。 |
(5)、Code类:GitHub公共代码存储库、StackOverflow代码问答平台、BigQuery(谷歌的不同编程语言的代码片段,如CodeGen模型)
| Code. To collect code data, existing work mainly crawls open-source licensed codes from the Internet. Two major sources are public code repositories under open-source li-censes (e.g., GitHub) and code-related question-answering platforms (e.g., StackOverflow). Google has publicly re-leased the BigQuery dataset [141], which includes a substan-tial number of open-source licensed code snippets in various programming languages, serving as a representative code dataset. CodeGen has utilized BIGQUERY [77], a subset of the BigQuery dataset, for training the multilingual version of CodeGen (CodeGen-Multi). | 代码。为了收集代码数据,现有工作主要从互联网上爬取开源许可证下的开放源码代码。两个主要来源是公共代码存储库(如GitHub)和与代码相关的问答平台(如StackOverflow)。 谷歌已公开发布了BigQuery数据集[141],其中包括大量用不同编程语言编写的开源许可证下的代码片段,成为代表性的代码数据集。 CodeGen已利用BIGQUERY [77],BigQuery数据集的一个子集,用于训练CodeGen的多语言版本(CodeGen-Multi)。 |
(6)、Others其他类:Pile(800G+22个多样化的高质量子集,如CodeGen/Megatron-Turing NLG)、ROOTS(1.6T+59种不同的语言【自然语言和编程语言】,如BLOOM)
| Others. The Pile [142] is a large-scale, diverse, and open-source text dataset consisting of over 800GB of data from multiple sources, including books, websites, codes, scientific papers, and social media platforms. It is constructed from 22 diverse high-quality subsets. The Pile dataset is widely used in models with different parameter scales, such as GPT-J (6B) [146], CodeGen (16B) [77], and Megatron-Turing NLG (530B) [97]. ROOTS [143] is composed of various smaller datasets (totally 1.61 TB of text) and covers 59 different languages (containing natural languages and pro-gramming languages), which have been used for training BLOOM [69]. | 其他。Pile [142]是一个大规模、多样化且开源的文本数据集,由来自多个来源的超过800GB的数据组成,包括书籍、网站、代码、科学论文和社交媒体平台。它由22个多样化的高质量子集构成。Pile数据集广泛应用于具有不同参数规模的模型中,如GPT-J (6B)[146]、CodeGen (16B)[77]和Megatron-Turing NLG (530B)[97]。ROOTS [143]由各种较小的数据集(总共1.61 TB文本)组成,覆盖59种不同的语言(包括自然语言和编程语言),已被用于训练BLOOM [69]。 |
总结:实践中需要混合不同数据源的语料库(如C4+OpenWebText+Pile):
| In practice, it commonly requires a mixture of different data sources for pre-training LLMs (see Figure 5), instead of a single corpus. Therefore, existing studies commonly mix several ready-made datasets (e.g., C4, OpenWebText, and the Pile), and then perform further processing to obtain the pre-training corpus. Furthermore, to train the LLMs that are adaptive to specific applications, it is also important to extract data from relevant sources (e.g., Wikipedia and BigQuery) for enriching the corresponding information in pre-training data. | 在实践中,通常需要混合不同数据源来预训练LLMs(参见图5),而不是单一语料库。因此,现有研究通常会混合几个现成的数据集(如C4、OpenWebText和Pile),然后进行进一步处理以获得预训练语料库。 此外,为了训练适应特定应用的LLMs,从相关来源提取数据以丰富预训练数据中的相关信息也很重要。 |
GPT-3-175B :CommonCrawl+WebText2+Books1_2+Wikipedia(300B的tokens混合数据)
PaLM-540B:社交媒体对话+过滤网页+书籍+Github+多语言维基百科和新闻(780B的tokens数据)
LLaMA-6B/32B:CommonCrawl+C4+Github+Wikipedia+books+ArXiv+StackExchange(1T/1.4T的tokens数据)
| To have a quick reference of the data sources used in existing LLMs, we present the pre-training corpora of three representative LLMs: GPT-3 (175B) [55] was trained on a mixed dataset of 300B tokens, including CommonCrawl [144], WebText2 [55], Books1 [55], Books2 [55], and Wikipedia [140]. PaLM (540B) [56] uses a pre-training dataset of 780B tokens, which is sourced from social media conversations, filtered webpages, books, Github, multilingual Wikipedia, and news. LLaMA [57] extracts training data from various sources, including CommonCrawl, C4 [73], Github, Wikipedia, books, ArXiv, and StackExchange. The training data size for LLaMA (6B) and LLaMA (13B) is 1.0T tokens, while 1.4T tokens are used for LLaMA (32B) and LLaMA (65B). | 为了快速了解现有LLMs所使用的数据源,我们展示了三个代表性LLMs的预训练语料库: GPT-3 (175B) [55] 基于一个包含CommonCrawl [144]、WebText2 [55]、Books1 [55]、Books2 [55]和Wikipedia [140]的300B令牌混合数据集进行训练; PaLM (540B) [56] 使用一个基于社交媒体对话、过滤网页、书籍、Github、多语言维基百科和新闻的780B令牌预训练数据集; LLaMA [57] 从CommonCrawl、C4 [73]、Github、Wikipedia、books、ArXiv和StackExchange等来源提取训练数据。LLaMA (6B)和LLaMA (13B)的训练数据大小为1.0T令牌,而LLaMA (32B)和LLaMA (65B)则使用了1.4T令牌。 |
3.3 Library Resource库资源—2+5+大高性能库
| In this part, we briefly introduce a series of available li-braries for developing LLMs. | 在本部分,我们简要介绍了一系列可用于开发大型语言模型(LLM)的可用库。 |
(1)、DL基础库:Transformers(Hugging Face开发)、DeepSpeed(微软开发DL分布式训练优化库【内存优化{ZeRO+梯度检查点}+管道并行】,如MT-NLG/BLOOM )
| Transformers [147] is an open-source Python library for building models using the Transformer architecture, which is developed and maintained by Hugging Face. It has a simple and user-friendly API, making it easy to use and customize various pre-trained models. It is a powerful library with a large and active community of users and developers who regularly update and improve the models and algorithms. DeepSpeed [65] is a deep learning optimization library (compatible with PyTorch) developed by Microsoft, which has been used to train a number of LLMs, such as MT-NLG [97] and BLOOM [69]. It provides the support of various optimization techniques for distributed training, such as memory optimization (ZeRO technique, gradient checkpointing), and pipeline parallelism. | Transformers[147] 是一个开源的 Python 库,用于使用 Transformer 架构构建模型,由 Hugging Face 开发和维护。它具有简单且用户友好的 API,使其易于使用和自定义各种预训练模型。这是一个功能强大的库,拥有庞大且活跃的用户和开发者社区,他们定期更新和改进模型及算法。 DeepSpeed[65] 是微软开发的深度学习优化库(与 PyTorch 兼容),已被用于训练诸如 MT-NLG [97] 和 BLOOM [69] 等 LLM。它为分布式训练提供了各种优化技术的支持,如内存优化(ZeRO 技术、梯度检查点)以及管道并行性。 |
(2)、高性能分布式库:Megatron-LM(NVIDIA开发DL分布式训练库【MP/DP+AMP+FlashAttention】)、JAX(Google开发高性能ML库)
| Megatron-LM [66–68] is a deep learning library developed by NVIDIA for training large-scale language models. It also provides rich optimization techniques for distributed training, including model and data parallelism, mixed-precision training, and FlashAttention. These optimization techniques can largely improve the training efficiency and speed, enabling efficient distributed training across GPUs. JAX [148] is a Python library for high-performance machine learning algorithms developed by Google, allow-ing users to easily perform computations on arrays with hardware acceleration (e.g., GPU or TPU). It enables efficient computation on various devices and also supports several featured functions, such as automatic differentiation and just-in-time compilation. | Megatron-LM[66-68] 是 NVIDIA 为训练大规模语言模型而开发的深度学习库。它还为分布式训练提供了丰富的优化技术,包括模型和数据并行性、混合精度训练以及 FlashAttention。这些优化技术可以大幅提高训练效率和速度,实现 GPU 上的高效分布式训练。 JAX[148] 是 Google 开发的 Python 高性能机器学习算法库,允许用户轻松地在硬件加速(例如 GPU 或 TPU)上执行数组计算。它支持在各种设备上进行高效计算,并提供一些特色功能,如自动微分和即时编译。 |
(3)、高性能分布式库:Colossal-AI(新加坡云计算公司HPC开发+基于PyTorch+并行策略)、BMTrain(清华大学OpenBMB开发分布式训练高效库+Flan-T5/GLM)、FastMoE(针对MoE的训练库+基于PyTorch)
| Colossal-AI [149] is a deep learning library developed by HPC-AI Tech for training large-scale AI models. It is implemented based on PyTorch and supports a rich collec-tion of parallel training strategies. Furthermore, it can also optimize heterogeneous memory management with meth-ods proposed by PatrickStar [150]. Recently, a ChatGPT-like model called ColossalChat [122] has been publicly released with two versions (7B and 13B), which are developed using Colossal-AI based on LLaMA [57]. BMTrain [151] is an efficient library developed by OpenBMB for training models with large-scale parameters in a distributed manner, which emphasizes code simplicity, low resource, and high availability. BMTrain has already incorporated several common LLMs (e.g., Flan-T5 [64] and GLM [83]) into its ModelCenter, where developers can use these models directly. FastMoE [152] is a specialized training library for MoE (i.e., mixture-of-experts) models. It is developed based on PyTorch, prioritizing both efficiency and user-friendliness in its design. FastMoE simplifies the process of transferring Transformer models to MoE models and supports both data parallelism and model parallelism during training. | Colossal-AI[149] 是 HPC-AI Tech 开发的大型 AI 模型训练库。它是基于 PyTorch 实现的,并支持丰富的并行训练策略集合。此外,它还可以使用 PatrickStar[150] 提出的方法优化异构内存管理。最近,一个名为 ColossalChat[122] 的类似 ChatGPT 的模型已公开发布,分为两个版本(7B 和 13B),它们基于 LLaMA[57] 使用 Colossal-AI 进行开发。 BMTrain[151] 是 OpenBMB 为分布式方式训练具有大量参数的大型模型而开发的高效库,强调代码简洁、低资源消耗和高可用性。BMTrain 已将多个常见的 LLM(如 Flan-T5[64] 和 GLM[83])集成到其 ModelCenter 中,开发人员可以直接使用这些模型。 FastMoE[152] 是专门针对 MoE(即专家混合)模型的训练库。它基于 PyTorch 设计,在设计时既注重效率又注重用户体验。FastMoE 简化了将 Transformer 模型转换为 MoE 模型的过程,并在训练过程中支持数据并行性和模型并行性。 |
(4)、其它如PyTorch、TensorFlow、MXNet、PaddlePaddle、MindSpore、OneFlow
| In addition to the above library resources, existing deep learning frameworks (e.g., PyTorch [153], TensorFlow [154], MXNet [155], PaddlePaddle [156], MindSpore [118] and OneFlow [157]) have also provided the support for parallel algorithms, which are commonly used for training large-scale models. | 除了上述库资源外,现有的深度学习框架(如 PyTorch[153]、TensorFlow[154]、MXNet[155]、PaddlePaddle[156]、MindSpore[118] 和 OneFlow[157])也为常用于训练大型模型的并行算法提供了支持。 |
这篇关于LLMs:《A Survey of Large Language Models大语言模型综述》的翻译与解读(一)之序言(挑战+LM四阶段+LLM与PLM的三大区别)、概述(两个代表性扩展定律/涌现能力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






