涌现专题
从loss角度理解LLM涌现能力
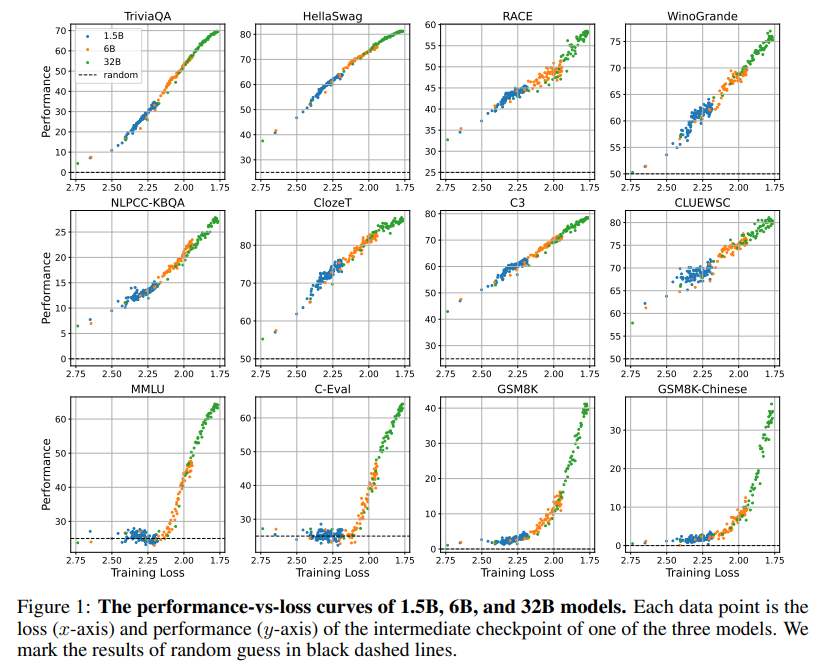
如今的很多研究都表明小模型也能出现涌现能力,本文的作者团队通过大量实验发现模型的涌现能力与模型大小、训练计算量无关,只与预训练loss相关。 作者团队惊奇地发现,不管任何下游任务,不管模型大小,模型出现涌现能力都不约而同地是在预训练loss降低到 2.2 以下后。 在 2.2 之前,模型的表现跟一般模型无异。在 2.2 之后,模型的性能显著上升。 数学建模 模型涌现能力与预训练loss的
从预训练损失的角度,理解语言模型的涌现能力
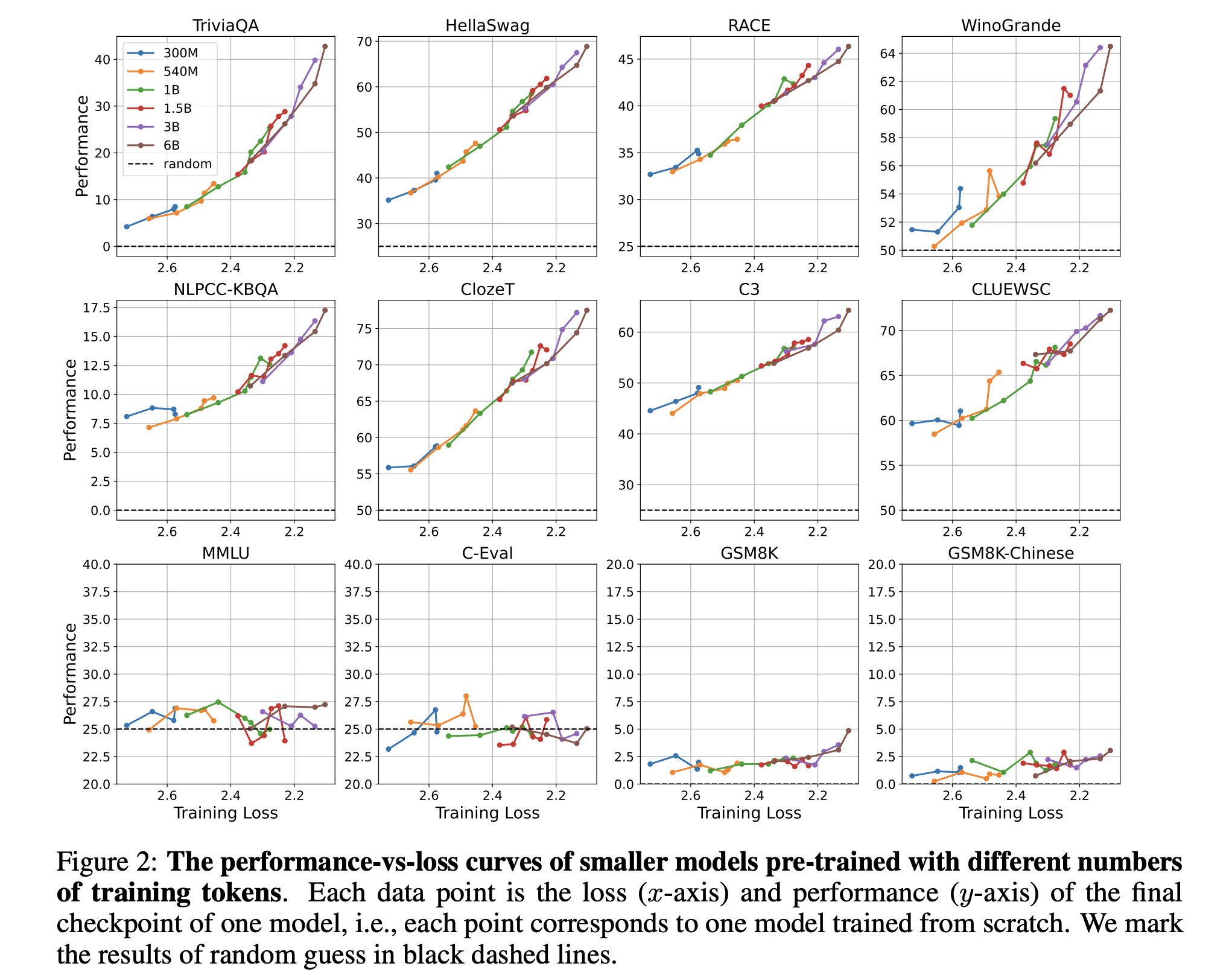
原文:Understanding Emergent Abilities of Language Models from the Loss Perspective 摘要 本文从预训练损失的角度重新审视语言模型的涌现能力,挑战了以往以模型大小或训练计算量为标准的观念。通过实验,作者发现预训练损失是预测下游任务性能的关键指标,不同规模的模型在相同预训练损失下展现相似性能。这一新视角为理解语言

华为云创新动能涌现,浒墅关开启先进制造新纪元
编辑:阿冒 设计:沐由 穿境而过的京杭大运河,孕育了苏州浒墅关深厚的历史文化底蕴。千年延续不断的繁华,滋养了一代又一代奋进的浒墅关人。今天,一座国家级经开区挺立在这里,散发出创新创业的蓬勃活力。 苏州浒墅关经济技术开发区(以下简称:浒墅关经开区),始建于1992年9月。经历了20年的快速发展之后,浒墅关经开区2013年升级为国家级经济技术开发区,正式步入到“国家队”的行列。 作为苏州高新区先

大模型2024规模化场景涌现,加速云计算走出第二增长曲线
导读:2024,大模型第一批规模化应用场景已出现。 如果说“百模大战”是2023年国内AI产业的关键词,那么2024年我们将正式迈进“应用为王”的新阶段。 不少业内观点认为,2024年“百模大战”将逐渐收敛甚至洗牌,而大模型在千行万业的应用将从小规模试水,逐渐走向规模化落地。 展望2024,哪些场景更有可能率先实现大模型的规模化应用? 如果将大模型的应用场景分为互联网和

OpenAI超级视频模型Sora技术报告解读,虚拟世界涌现了
昨天白天,「现实不存在了」开始全网刷屏。 「我们这么快就步入下一个时代了?Sora简直太炸裂了」。 「这就是电影制作的未来」! 谷歌的Gemini Pro 1.5还没出几个小时的风头,天一亮,全世界的聚光灯就集中在了OpenAI的Sora身上。 Sora一出,众视频模型臣服。 就在几小时后,OpenAI Sora的技术报告也发布了! 其中,「里程碑」也成为报告中
《系统架构:复杂系统的产品设计与开发》——第2章,第2.6节任务四:涌现
本节书摘来自华章出版社《系统架构:复杂系统的产品设计与开发》一书中的第2章,第2.6节任务四:涌现,作者[美]布鲁斯·卡梅隆,更多章节内容可以访问云栖社区“华章计算机”公众号查看 2.6任务四:涌现2.6.1涌现的重要性系统的奇妙之处,在于涌现。把系统的各个实体组合起来之后,一种新的功能,就会随着由这些实体的功能与实体之间的功能交互所形成的组合而涌现出来。系统是由一系列实体及其关系所组成的,系统

大语言模型LLM Large Language Model 的涌现Emergence 反馈强化学习 RLHF 预训练 token word embeddings 温度 temperature=0.7
1. Large Language Model(大型语言模型) Large Language Model(大型语言模型)是指具有大规模参数数量和处理能力的语言模型。这些模型通过深度学习技术训练,能够处理和生成自然语言文本。 大型语言模型在自然语言处理领域发挥着重要作用,它们能够理解和生成文本,执行语言相关的任务,如机器翻译、文本摘要、情感分析、对话系统等。这些模型的训练基于大量的文本数据集,使
大模型2024规模化场景涌现,加速云计算走出第二增长曲线
导读:2024,大模型第一批规模化应用场景已出现。 如果说“百模大战”是2023年国内AI产业的关键词,那么2024年我们将正式迈进“应用为王”的新阶段。 不少业内观点认为,2024年“百模大战”将逐渐收敛甚至洗牌,而大模型在千行万业的应用将从小规模试水,逐渐走向规模化落地。 展望2024,哪些场景更有可能率先实现大模型的规模化应用? 如果将大模型的应用场景分为互联网和

腾讯科技Hi Tech Day暨2023数字开物大会:智能涌现将通往无数的未来
腾讯科技讯 12月14日,以“智能涌现 数开万物”为主题的腾讯科技Hi Tech Day暨2023数字开物大会在北京国家会议中心召开,腾讯科技邀请知名院士、知名经济学家、知名大学教授、研究院院长、产业大咖、互联网大厂高管、知名科技领域头部企业高管、产业数字化转型企业高管等共话AI趋势。 大会开场,腾讯新闻运营总经理黄晨霞发表主办方致辞。她回顾了2023年新技术的涌现发展,并提出如何让这些新技术打
华为云创新动能涌现,浒墅关开启先进制造新纪元
编辑:阿冒 设计:沐由 穿境而过的京杭大运河,孕育了苏州浒墅关深厚的历史文化底蕴。千年延续不断的繁华,滋养了一代又一代奋进的浒墅关人。今天,一座国家级经开区挺立在这里,散发出创新创业的蓬勃活力。 苏州浒墅关经济技术开发区(以下简称:浒墅关经开区),始建于1992年9月。经历了20年的快速发展之后,浒墅关经开区2013年升级为国家级经济技术开发区,正式步入到“国家队”的行列。 作为苏州高新区先
腾讯科技Hi Tech Day暨2023数字开物大会:智能涌现将通往无数的未来
腾讯科技讯 12月14日,以“智能涌现 数开万物”为主题的腾讯科技Hi Tech Day暨2023数字开物大会在北京国家会议中心召开,腾讯科技邀请知名院士、知名经济学家、知名大学教授、研究院院长、产业大咖、互联网大厂高管、知名科技领域头部企业高管、产业数字化转型企业高管等共话AI趋势。 大会开场,腾讯新闻运营总经理黄晨霞发表主办方致辞。她回顾了2023年新技术的涌现发展,并提出如何让这些新技术打

人工智能“涌现”时刻:数据中心如何解题?
随着科技的迅猛发展,人工智能(AI)正逐渐成为推动社会进步的关键力量。AI技术的广泛应用给我们的生活和工作带来了巨大的改变,而这一切的背后离不开数据中心的支持和创新。数据中心如何解决人工智能的挑战,成为了当今科技领域一个备受关注的话题。 1. 大数据时代的崛起 人工智能的崛起和发展离不开大数据的支持。大数据时代的到来使得数据中心面临了前所未有的规模和复杂性。海量的数据需要被高效地存储、管理和分

Science最新:Jeff Gore团队揭示复杂生态系统中涌现的相变
来源:集智俱乐部 作者:胡脊梁 编辑:邓一雪 导语 生态学致力于理解自然生态系统中的多样化的物种和复杂的动力学行为,然而科学家长期缺乏描述和预测生物多样性和生态动力学的统一框架。MIT物理系的胡脊梁和Jeff Gore等科学家结合理论和微生物群落实验,证明只需要掌握少量群落尺度的控制变量,就可以预测复杂生态系统的行为。热力学描述大量气体分子的行为只需要温度和压强等少数涌现的状态变量,而不需要知

现在市场上IT人才大量涌现,现在开始学习编程,以后会有前途吗?
现在市场上IT人才大量涌现,如果我现在开始学习编程,以后会有前途吗?答案是肯定的,一定有前途而且前途远大!下面分析一下具体原因: 未来一定是信息化社会 当今我们正处在第三次信息化浪潮中,这次信息化浪潮的典型技术代表是物联网、云计算、大数据。物联网和云计算是大数据的基础,大数据驱动了很多行业的快速发展,比如智能医疗、智能交通、智能购物、智慧城市等等,所有这些都离不开数据的支撑,而这些将是未来
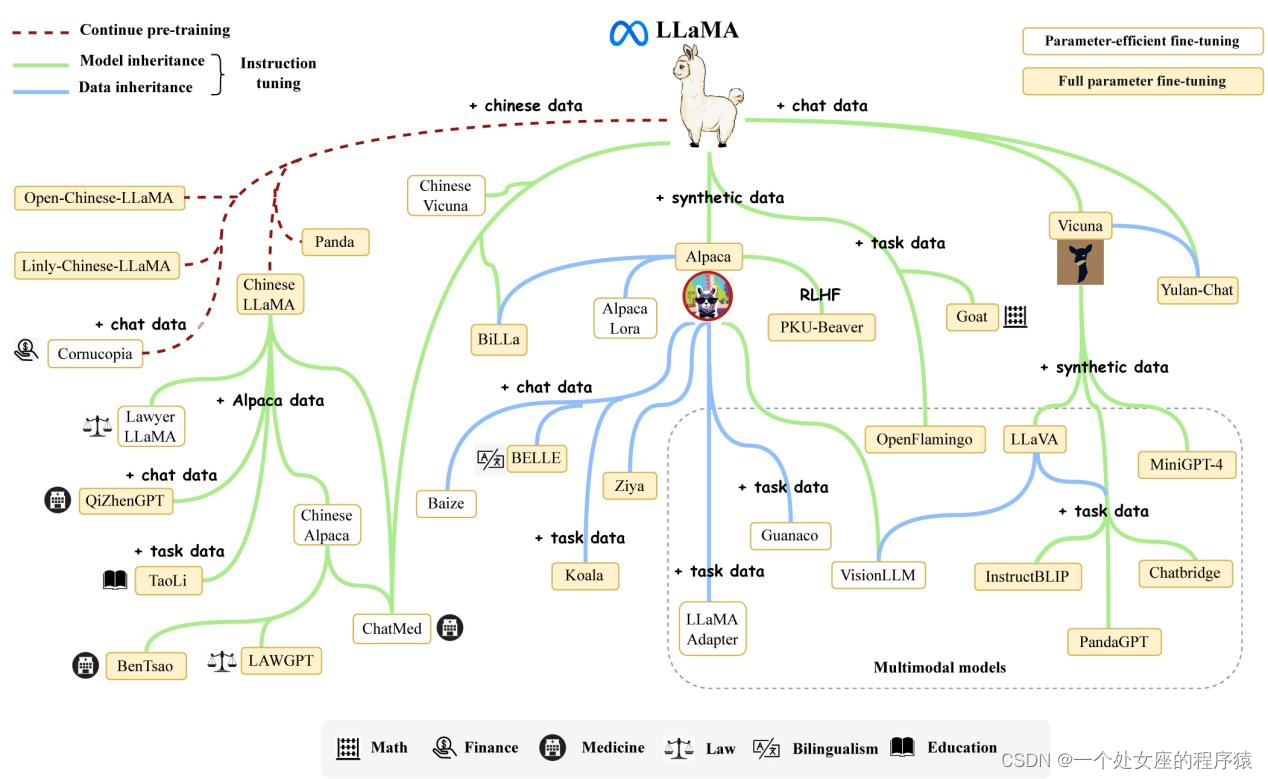
LLMs:《A Survey of Large Language Models大语言模型综述》的翻译与解读(一)之序言(挑战+LM四阶段+LLM与PLM的三大区别)、概述(两个代表性扩展定律/涌现能力
LLMs:《A Survey of Large Language Models大语言模型综述》的翻译与解读(一)之序言(挑战+LM四阶段+LLM与PLM的三大区别)、概述(两个代表性扩展定律/涌现能力三种典型/六大关键技术+GPT系列技术演进)、资源(开源模型/闭源API+六类语料库+三种框架库) 导读:LLMs(LLM)是指具有数十亿甚至数百亿参数的 Transformer 语言模型,近
LLMs:《A Survey of Large Language Models大语言模型综述》的翻译与解读(一)之序言(挑战+LM四阶段+LLM与PLM的三大区别)、概述(两个代表性扩展定律/涌现能力
LLMs:《A Survey of Large Language Models大语言模型综述》的翻译与解读(一)之序言(挑战+LM四阶段+LLM与PLM的三大区别)、概述(两个代表性扩展定律/涌现能力三种典型/六大关键技术+GPT系列技术演进)、资源(开源模型/闭源API+六类语料库+三种框架库) 导读:LLMs(LLM)是指具有数十亿甚至数百亿参数的 Transformer 语言模型,近

《系统架构:复杂系统的产品设计与开发》——第2章,第2.2节系统与涌现
本节书摘来自华章出版社《系统架构:复杂系统的产品设计与开发》一书中的第2章,第2.2节系统与涌现,作者[美]布鲁斯·卡梅隆,更多章节内容可以访问云栖社区“华章计算机”公众号查看 2.2系统与涌现2.2.1系统由于系统思维是一种把疑问、状况或难题明确视为系统的思维方式,因此,要讲解系统思维,首先就必须讨论系统。英语中很少有哪个词的使用范围像系统这样广泛,而且其定义也有很多种,本书采用文字框2.1中
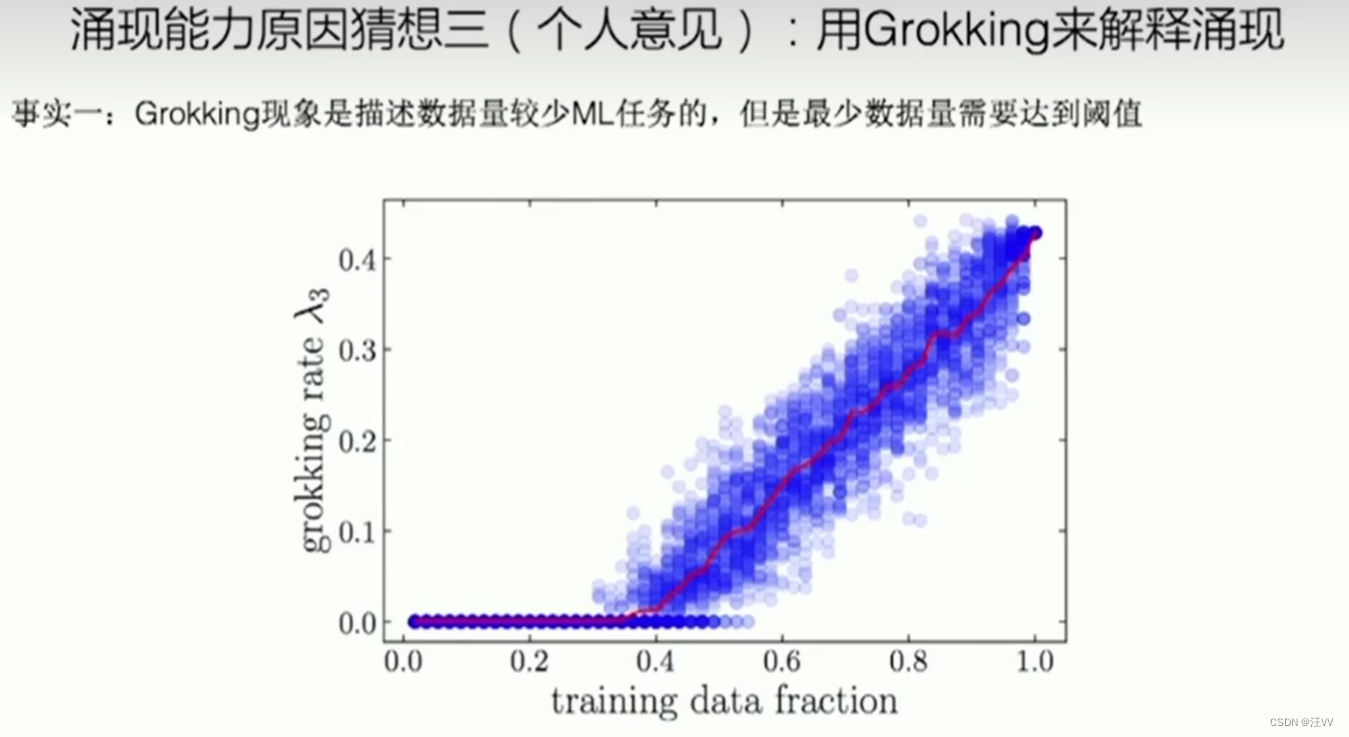
大模型/LLM的涌现能力
新浪张俊林–中国人工智能学会演讲 文章目录 什么是大模型的涌现能力LLM表现的涌现能力1. In Context Learning -- 情景学习2. CoT3. 其他涌现能力 LLM模型规模和涌现能力的关系模型训练中的顿悟现象:GrokkingLLM涌现能力的可能原因 什么是大模型的涌现能力 涌现: 许多小实体相互作用产生了大实体,大实体展现了组成它的小实体所不具有的特