本文主要是介绍从预训练损失的角度,理解语言模型的涌现能力,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文:Understanding Emergent Abilities of Language Models from the Loss Perspective

摘要
本文从预训练损失的角度重新审视语言模型的涌现能力,挑战了以往以模型大小或训练计算量为标准的观念。通过实验,作者发现预训练损失是预测下游任务性能的关键指标,不同规模的模型在相同预训练损失下展现相似性能。这一新视角为理解语言模型涌现能力提供了理论基础,并指出了在更小规模模型上复现或超越大型模型涌现能力的可能性。
引言
近年来,随着大规模语言模型(LMs)的发展,其在多种下游任务上展现出的涌现能力(emergent abilities)引起了广泛关注。这些能力通常被认为是大型模型的专属,但近期研究开始质疑这一观点,提出小型模型在某些情况下也能展现出类似的能力。本文旨在从预训练损失的角度重新审视语言模型的涌现能力,挑战了以往以模型大小或训练计算量为标准的旧观念。
研究动机
传统的观念认为,只有大型语言模型才具备处理复杂任务的涌现能力。然而,两个观察结果对这一信念提出了质疑:首先,小型模型在足够数据量的加持下也能在声称具有涌现能力的任务上超越大型模型。其次,一些研究指出,所谓的涌现能力可能仅仅是由于使用了非线性或不连续的评估指标。本文的动机在于,探索并证明预训练损失而非模型大小是决定语言模型在下游任务性能的关键因素。
方法论
研究背景
在探讨语言模型的涌现能力时,作者首先回顾了以往研究中关于模型规模和数据规模对预训练损失的影响。他们指出,不同模型和数据规模的组合可以在相同的训练计算量下产生不同的预训练损失,这表明预训练损失是比模型或数据规模更自然的学习能力代表。
方法动机
本文在探讨语言模型的涌现能力时,虽然提出了从预训练损失角度进行分析的新视角,但在研究过程中也暴露出一些限制和问题:
- 模型架构与训练算法的多样性:研究中主要关注了预训练损失与任务性能的关系,但没有充分考虑不同模型架构和训练算法对这一关系可能产生的影响。
- 预训练语料库的影响:预训练损失受到所使用的分词器和预训练语料库分布的影响,这导致在不同语料库上训练出的模型之间的预训练损失不具备直接的可比性。
- 评估指标的选择:虽然文中提到了使用连续指标来评估性能,但如何选择合适的评估指标以准确反映模型的性能仍然是一个挑战。
- 模型规模的上限:研究并没有明确指出模型规模的上限在哪里,即是否存在一个点,超过该点后,进一步增加模型规模不会带来性能的提升。
- 计算资源的限制:大规模语言模型的训练和预训练需要巨大的计算资源,这可能限制了研究的可扩展性。
作者提出,尽管预训练损失与模型的下游任务性能关系尚未被充分理解,但通过固定数据语料库、分词和模型架构来预训练多种规模的语言模型,可以更准确地评估预训练损失与下游任务性能之间的关系。
针对上述问题,文中提出了一些可能的解决思路或方法:
- 多架构和算法的比较:未来的研究可以在不同的模型架构和训练算法下,比较预训练损失与任务性能的关系,以更全面地理解这一关系。
- 标准化的预训练损失评估:建议使用标准化的预训练损失评估方法,如在公共验证集上评估不同语言模型的归一化困惑度(normalized perplexity),以考虑不同词汇表大小的影响。
- 评估指标的深入研究:需要对评估指标进行更深入的研究,以确保它们能够准确反映模型在特定任务上的性能。
- 模型规模与性能的边际效应:研究模型规模与性能之间的边际效应,确定是否存在一个最优的模型规模,超过该规模后,性能提升会显著减少。
- 资源有效的训练策略:探索更资源有效的训练策略,如指令调整(instruction tuning)或多任务学习,以降低对计算资源的需求。
方法步骤
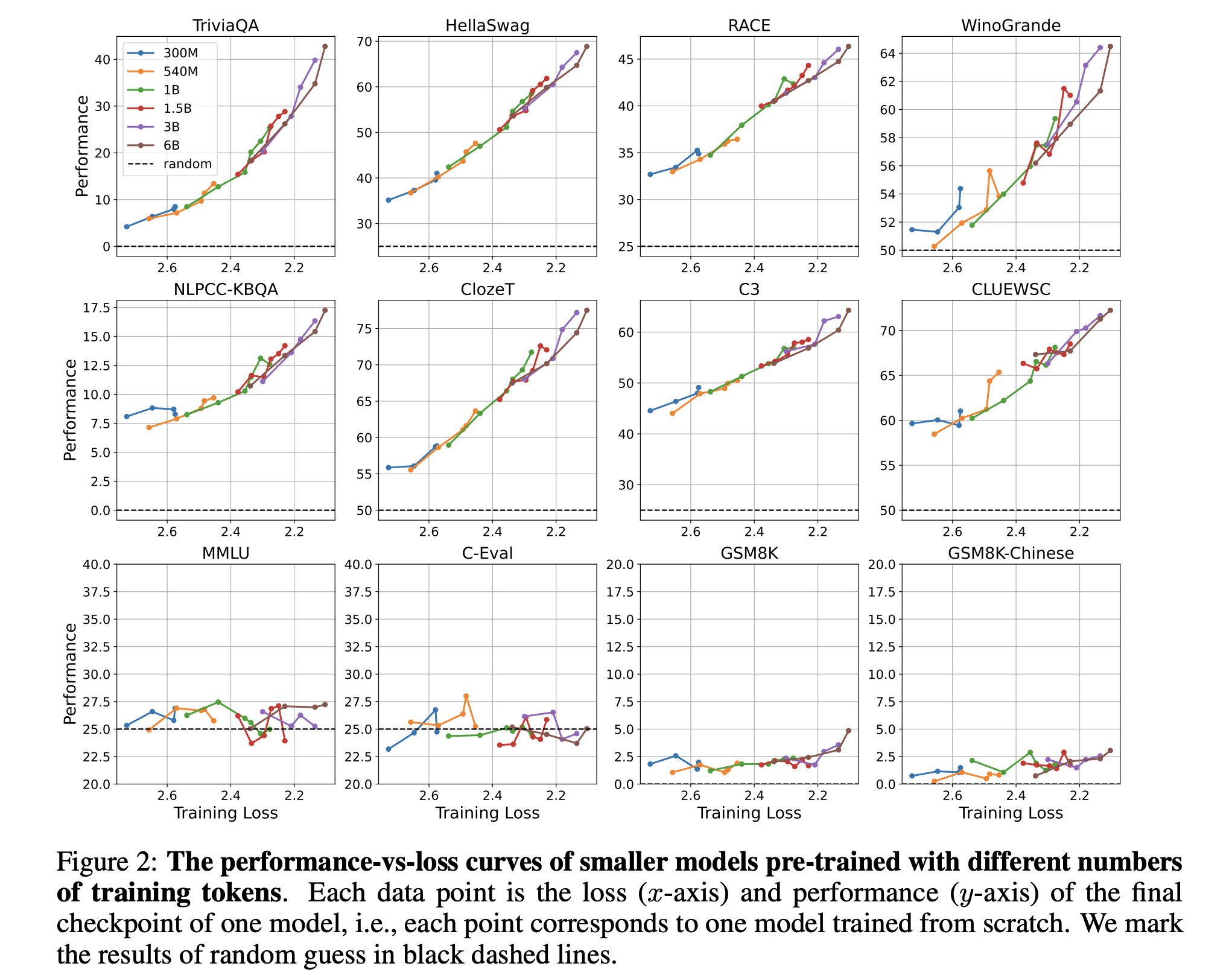
- 预训练设置:作者选择了多种规模的模型(从300M到32B参数不等),并使用固定的数据语料库、分词方法和模型架构进行预训练。
- 数据和模型架构:数据集包括英文和中文的网页、维基百科、书籍和论文,模型架构类似于LLaMA,但有细微差别。
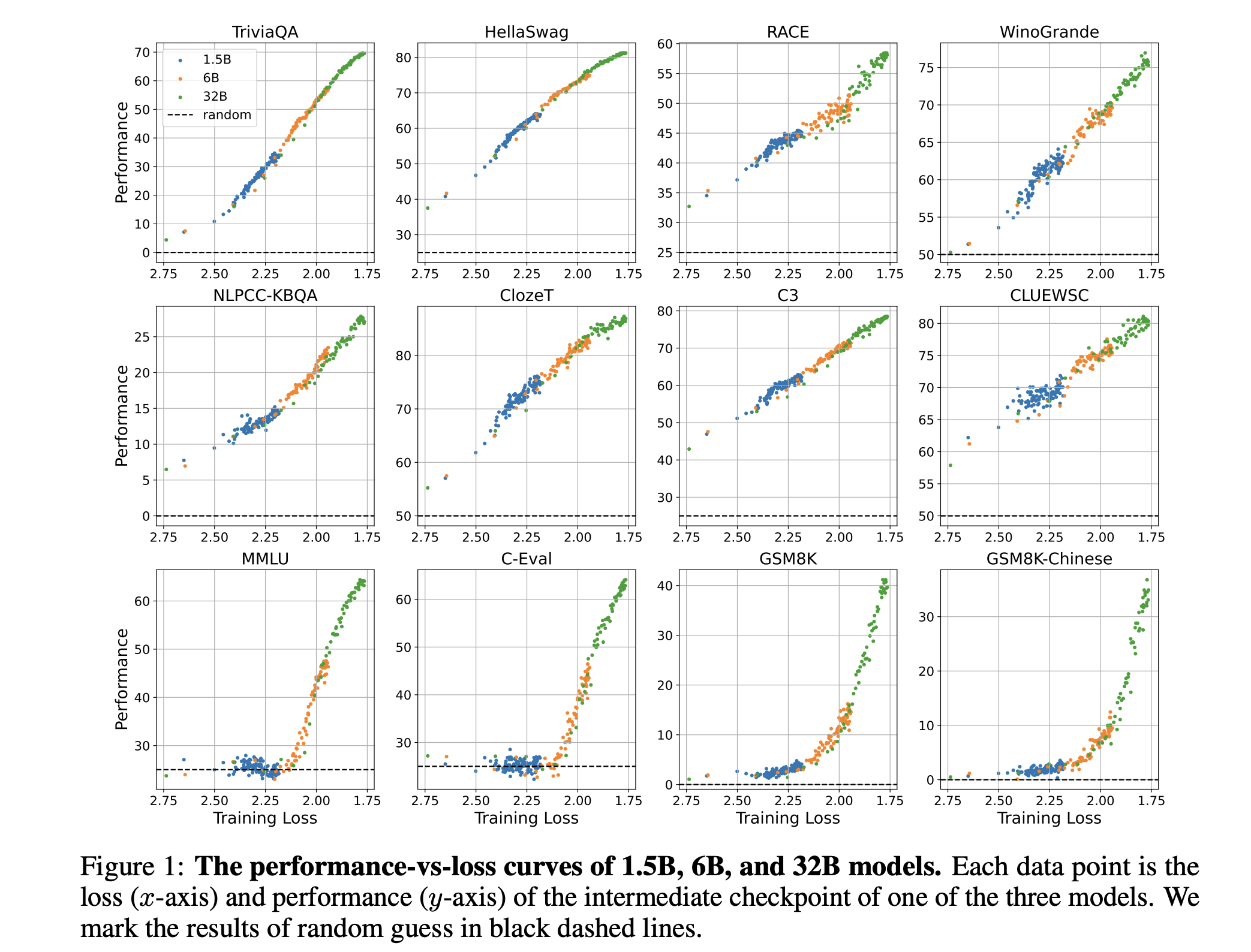
- 评估任务:预训练模型在12个不同的数据集上进行评估,这些数据集覆盖了多种任务、语言、提示类型和答案形式。
- 性能与损失的关系:通过分析不同中间训练检查点的性能和预训练损失,作者探讨了这两者之间的关系。
- 连续与非连续指标:为了排除非连续指标的影响,作者还使用连续指标评估了模型性能的提升。
实验分析
作者通过实验发现,当预训练损失低于特定阈值时,模型在某些下游任务上的性能会超过随机猜测水平,而这一阈值与任务的连续性无关。此外,不同规模的模型在相同的预训练损失下展现出相似的性能趋势,表明预训练损失是预测下游任务性能的一个普适指标。
创新点
本文的主要创新点在于提出了从预训练损失的角度定义语言模型的涌现能力,这一定义超越了以往以模型大小或训练计算量为标准的旧观念。作者通过实证研究证明了预训练损失与下游任务性能之间的强相关性,并指出了模型在预训练损失低于特定阈值时表现出的涌现能力。
不足与展望
尽管本文的研究为理解语言模型的涌现能力提供了新的视角,但也存在一些局限性。例如,研究中未考虑模型架构和训练算法的差异,这些因素可能影响预训练损失与任务性能的关系。此外,预训练损失受到分词器和预训练语料库分布的影响,不同语料库训练出的模型的预训练损失可能不具有直接可比性。
未来的研究可以进一步探索在不同预训练语料库上的模型性能,以及如何通过指令调整或模型架构改进来降低涌现能力出现的规模要求。此外,研究者可以利用本文提出的视角,深入分析模型在特定预训练损失阈值下的行为变化,以促进新能力的发展。
结论
文中提出的从预训练损失角度理解语言模型的涌现能力,已经在一定程度上解释了为何不同规模的模型在特定任务上会表现出类似的性能。通过固定数据集和模型架构进行预训练,作者能够更准确地控制变量,从而更清晰地揭示预训练损失与下游任务性能之间的关系。
然而,由于上述问题的复杂性,文中提出的方法可能还需要进一步的实验和分析来验证其在不同情境下的适用性和有效性。特别是,如何将这些发现转化为实际应用中更高效的模型训练和优化策略,仍然需要更多的研究和探索。
本文通过深入分析,提出了从预训练损失的角度来理解和预测语言模型的涌现能力。这一新的定义不仅为语言模型的研究提供了新的理论基础,也为未来的研究方向指明了新的可能性。通过更细致的控制预训练损失,我们有望在更小规模的模型上复现或甚至超越大型模型的涌现能力,这将对资源有限的研究机构和开发者具有重要意义。
这篇关于从预训练损失的角度,理解语言模型的涌现能力的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






