损失专题

SigLIP——采用sigmoid损失的图文预训练方式
SigLIP——采用sigmoid损失的图文预训练方式 FesianXu 20240825 at Wechat Search Team 前言 CLIP中的infoNCE损失是一种对比性损失,在SigLIP这个工作中,作者提出采用非对比性的sigmoid损失,能够更高效地进行图文预训练,本文进行介绍。如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注

逐行讲解Transformer的代码实现和原理讲解:计算交叉熵损失
LLM模型:Transformer代码实现和原理讲解:前馈神经网络_哔哩哔哩_bilibili 1 计算交叉熵目的 计算 loss = F.cross_entropy(input=linear_predictions_reshaped, target=targets_reshaped) 的目的是为了评估模型预测结果与实际标签之间的差距,并提供一个量化指标,用于指导模型的训练过程。具体来说,交叉

【深度学习 误差计算】10分钟了解下均方差和交叉熵损失函数
常见的误差计算函数有均方差、交叉熵、KL 散度、Hinge Loss 函数等,其中均方差函数和交叉熵函数在深度学习中比较常见,均方差主要用于回归问题,交叉熵主要用于分类问题。下面我们来深刻理解下这两个概念。 1、均方差MSE。 预测值与真实值之差的平方和,再除以样本量。 均方差广泛应用在回归问题中,在分类问题中也可以应用均方差误差。 2、交叉熵 再介绍交叉熵损失函数之前,我们首先来介绍信息

Anchor Alignment Metric来优化目标检测的标签分配和损失函数。
文章目录 背景假设情况任务和目标TaskAligned方法的应用1. **计算Anchor Alignment Metric**2. **动态样本分配**3. **调整损失函数** 示例总结 背景 假设我们在进行目标检测任务,并且使用了YOLOv8模型。我们希望通过TaskAligned方法来优化Anchor与目标的匹配程度,从而提升检测效果。 假设情况 图像: 一张包含

在目标检测模型中使用正样本和负样本组成的损失函数。
文章目录 背景例子说明1. **样本和标签分配**2. **计算损失函数**3. **组合损失函数** 总结 背景 在目标检测模型中,损失函数通常包含两个主要部分: 分类损失(Classification Loss):用于评估模型对目标类别的预测能力。定位损失(Localization Loss):用于评估模型对目标位置的预测准确性。 例子说明 假设我们有一个目标检测模
逻辑回归-损失函数详解
有监督学习 机器学习分为有监督学习,无监督学习,半监督学习,强化学习。对于逻辑回归来说,就是一种典型的有监督学习。 既然是有监督学习,训练集自然可以用如下方式表述: {(x1,y1),(x2,y2),⋯,(xm,ym)} 对于这m个训练样本,每个样本本身有n维特征。再加上一个偏置项 x0 , 则每个样本包含n+1维特征: x=[x0,x1,x2,⋯,xn


神经网络多分类任务的损失函数——交叉熵
神经网络多分类任务的损失函数——交叉熵 神经网络解决多分类问题最常用的方法是设置n个输出节点,其中n为类别的个数。对于每一个样例,神经网络可以得到的一个n维数组作为输出结果。数组中的每一个维度(也就是每一个输出节点)对应一个类别。在理想情况下,如果一个样本属于类别k,那么这个类别所对应的输出节点的输出值应该为1,而其他节点的输出都为0。 以识别手写数字为例,0~9共十个类别。识别数字1,神经网
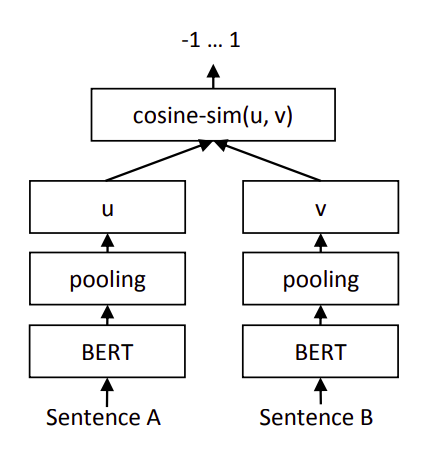
Sentence-BERT实现文本匹配【对比损失函数】
引言 还是基于Sentence-BERT架构,或者说Bi-Encoder架构,但是本文使用的是参考2中提出的对比损失函数。 架构 如上图,计算两个句嵌入 u \pmb u u和 v \pmb v v之间的距离(1-余弦相似度),然后使用参考2中提出的对比损失函数作为目标函数: L = y × 1 2 ( distance ( u , v ) ) 2 + ( 1 − y ) × 1 2

【AI】Pytorch_损失函数优化器
建议点赞收藏关注!持续更新至pytorch大部分内容更完。 本文已达到10w字,故按模块拆开,详见目录导航。 整体框架如下 数据及预处理 模型及其构建 损失函数及优化器 本节目录 损失函数创建损失函数 (共18个)nn.CrossEntropyLossnn.NLLLossBCE LossBCEwithLogitsLossnn.L1Lossnn.MSELossnn.SmoothL1Lo
![[pytorch] --- pytorch基础之损失函数与反向传播](https://i-blog.csdnimg.cn/direct/d7918f0c5e0d4bc2be09bd8aaf71e61a.png)
[pytorch] --- pytorch基础之损失函数与反向传播
1 损失函数 1.1 Loss Function的作用 每次训练神经网络的时候都会有一个目标,也会有一个输出。目标和输出之间的误差,就是用Loss Function来衡量的。所以Loss误差是越小越好的。此外,我们可以根据误差Loss,指导输出output接近目标target。即我们可以以Loss为依据,不断训练神经网络,优化神经网络中各个模块,从而优化output 。 Loss Funct

机器学习面试:请介绍下LR的损失函数?
在机器学习中,逻辑回归(Logistic Regression, LR)是一种广泛使用的分类算法,尤其适用于二分类问题。逻辑回归的损失函数主要是用来衡量模型预测值与真实值之间的差距。以下是对逻辑回归损失函数的详细介绍: 1. 逻辑回归的基本概念 逻辑回归通过一个sigmoid函数将线性组合的输入映射到0和1之间,公式如下: 其中,hθ(x)是预测的概率,θ是模型参数,x 是输入特征。
keras missing label unlabeled 未标注类 如何训练 如何自定义损失函数 去除未标注类 缺少标签
我从这里找到的答案: def ignore_unknown_xentropy(ytrue, ypred):return (1-ytrue[:, :, :, 0])*categorical_crossentropy(ytrue, ypred) 然后下面是我的代码: 我感觉看到这个帖子的应该都看得懂吧(其实就是懒得解释了,请看注释) from __future__ import print_
叶斯神经网络(BNN)在训练过程中损失函数不收敛或跳动剧烈可能是由多种因素
贝叶斯神经网络(BNN)在训练过程中损失函数不收敛或跳动剧烈可能是由多种因素引起的,以下是一些可能的原因和相应的解决方案: 学习率设置不当:过高的学习率可能导致损失函数在优化过程中震荡不收敛,而过低的学习率则可能导致收敛速度过慢。可以尝试使用学习率衰减策略,或者根据任务和数据集的特点设置合适的学习率。 数据问题:数据集中的噪声、异常值或不均匀的分布可能会导致模型的损失函数上升。此外,如果训练

pytorch负对数似然损失函数介绍
nn.NLLLoss(负对数似然损失)是 PyTorch 中的一种损失函数,常用于分类任务,特别是在模型的输出已经经过了 log-softmax 的情况下。与 nn.CrossEntropyLoss 不同的是,nn.NLLLoss 期望输入的是对数概率值(即 log-softmax 的输出),而不是未经过处理的 logits。 Log-Softmax函数是对Softmax函数的对数版本,它在

pytorch交叉熵损失函数
nn.CrossEntropyLoss 是 PyTorch 中非常常用的损失函数,特别适用于分类任务。它结合了 nn.LogSoftmax 和 nn.NLLLoss(负对数似然损失)的功能,可以直接处理未经过 softmax 的 logits 输出,计算预测值与真实标签之间的交叉熵损失。 1. 交叉熵损失的原理 交叉熵损失衡量的是两个概率分布之间的差异。在分类任务中,模型输出的 logits

损失函数、成本函数cost 、最大似然估计
一、损失函数 什么是损失函数? 【深度学习】一文读懂机器学习常用损失函数(Loss Function)-腾讯云开发者社区-腾讯云 损失函数(loss function)是用来估量模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。损失函数是经验风险函数的核心部分,也是结构风险函数重要组成部分。模型的结构风险函
深度学习--损失函数
损失函数 什么是损失函数? 在深度学习中损失函数是用来衡量模型参数的质量函数,衡量的方式是比较网络输出和真实输出的差异 回归任务损失函数-MAE损失 (MAE)也被称为L1 Loss,是以绝对误差作为距离. 特点: 1.由于L1 loss具有稀疏性,为了惩罚较大的值,因此常常将其作为正则项添加到其他loss中作为约束. 2.L1 loss的最大问题是梯度在零

microsoft微软excel或WPS表格打开vivado逻辑分析仪ILA保存的csv文件,自动转换科学计数法损失精度的bug
问题 vivado的逻辑分析仪ILA,可以方便的把数据导出成CSV(Comma-Separated Values)文件,实际是逗号作为分隔符的数据文件。 导出数据文件用文本编辑器打开,第74行有如下数据: 但是使用excel打开这个csv文件,则这个数据自动显示为科学计数法,但是值的最后一位已经从8变成0: 误差 这个值代表的双精度浮点数,误差-0.00000000000005
机器学习和深度学习中常见损失函数,包括损失函数的数学公式、推导及其在不同场景中的应用
目录 引言什么是损失函数?常见损失函数介绍 3.1 均方误差(Mean Squared Error, MSE)3.2 交叉熵损失(Cross-Entropy Loss)3.3 平滑L1损失(Smooth L1 Loss)3.4 Hinge Loss(合页损失)3.5 二进制交叉熵损失(Binary Cross-Entropy Loss)3.6 KL散度(KL Divergence)3.7 Hub
如何将 iPhone 视频转换为 MP4 而不损失输出质量
目前,iPhone 以 HEVC(高效视频编码,也称为 H.265)保存视频。其优点是可以以较小的文件大小生成更好的视频质量。缺点是兼容性低。大多数网站、社交媒体和操作系统仍然不支持它。这就是为什么你必须将iPhone 视频转换为 MP4格式。本文介绍了最佳方法并详细演示了工作流程。 第 1 部分:将 iPhone 视频转换为 MP4 的最佳方法 将 iPhone 视频转换为 MP4 时,

神经网络算法 - 一文搞懂Loss Function(损失函数)
本文将从损失函数的本质、损失函数的原理、损失函数的算法三个方面,带您一文搞懂损失函数 Loss Function 。。 损失函数 机器学习“三板斧”: 选择模型家族,定义损失函数量化预测误差, 通过优化算法找到最小化损失的最优模型参数。 机器学习 vs 人类学习 定义一个函数集合(模型选择) 目标:确定一个合适的假设空间或模型家族。 示例:线性回归、逻辑回归、神经网络、决

YOLOv9改进策略【损失函数篇】| 利用MPDIoU,加强边界框回归的准确性
一、背景 目标检测和实例分割中的关键问题: 现有的大多数边界框回归损失函数在不同的预测结果下可能具有相同的值,这降低了边界框回归的收敛速度和准确性。 现有损失函数的不足: 现有的基于 ℓ n \ell_n ℓn范数的损失函数简单但对各种尺度敏感。当预测框与真实框具有相同的宽高比但不同的宽度和高度值时,现有损失函数可能会存在问题,限制了收敛速度和准确性。 文章目录 一、背景二、原理2.

YOLOv9改进策略【损失函数篇】| Slide Loss,解决简单样本和困难样本之间的不平衡问题
一、本文介绍 本文记录的是改进YOLOv9的损失函数,将其替换成Slide Loss,并详细说明了优化原因,注意事项等。Slide Loss函数可以有效地解决样本不平衡问题,为困难样本赋予更高的权重,使模型在训练过程中更加关注困难样本。若是在自己的数据集中发现容易样本的数量非常大,而困难样本相对稀疏,可尝试使用Slide Loss来提高模型在处理复杂样本时的性能。 文章目录 一、本文介绍

大模型训练核心算法之——损失函数算法
“ 损失函数是实现大模型训练的基础” 今天就来介绍一下大模型训练的一个核心算法——损失函数算法。 大模型正是利用损失差和反向传播算法来更新模型参数的权重,依此达到最优化模型参数的目的,而这也直接关系到大模型的推测效果。 大模型损失函数计算 损失函数是机器学习与深度学习中用于衡量模型预测与实际结果之间差距的函数;选择合适的损失函数对于训练模型的性能至关重要。 以下从技术原理,实现等多个方面
【深度学习】Focal Loss 损失函数
Focal Loss 损失函数 1. Focal Loss 介绍2. 背景3. Focal Loss 定义(1) 交叉熵损失(2) 平衡因子 α t \alpha_t αt(3) 焦点因子 γ \gamma γ 4. 使用场景5. Focal Loss代码实现(Pytorch)6. 总结 1. Focal Loss 介绍 Focal Loss 是一种专门设计用于处理类别不平衡