从预专题

15 种高级 RAG 技术 ——从预检索到生成
15 种高级 RAG 技术 ——从预检索到生成 检索增强生成(RAG)是一个丰富、快速发展的领域,它为增强由大型语言模型(LLM)驱动的生成式人工智能系统创造了新的机会。在本指南中,WillowTree的数据与人工智能研究团队(DART)分享了15种先进的RAG技术,用于微调您自己的系统,在优化客户的应用程序时,我们信任所有这些技术。 原文链接:15 Advanced RAG Techniqu
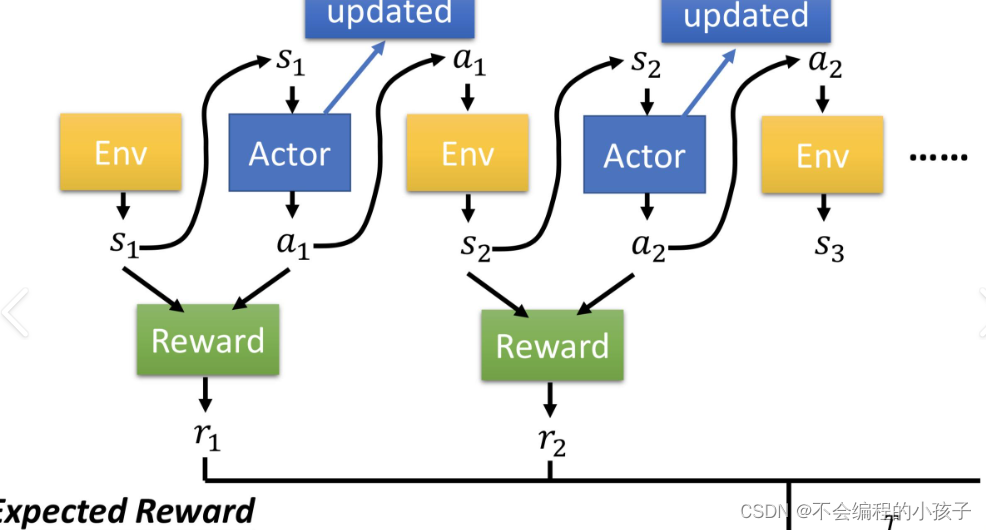
大模型训练的艺术:从预训练到增强学习的四阶段之旅
文章目录 大模型训练的艺术:从预训练到增强学习的四阶段之旅1. 预训练阶段(Pretraining)2. 监督微调阶段(Supervised Finetuning, SFT)3. 奖励模型训练阶段(Reward Modeling)4. 增强学习微调阶段(Reinforcement Learning, RL) 大模型训练的艺术:从预训练到增强学习的四阶段之旅 在当今人工智能领
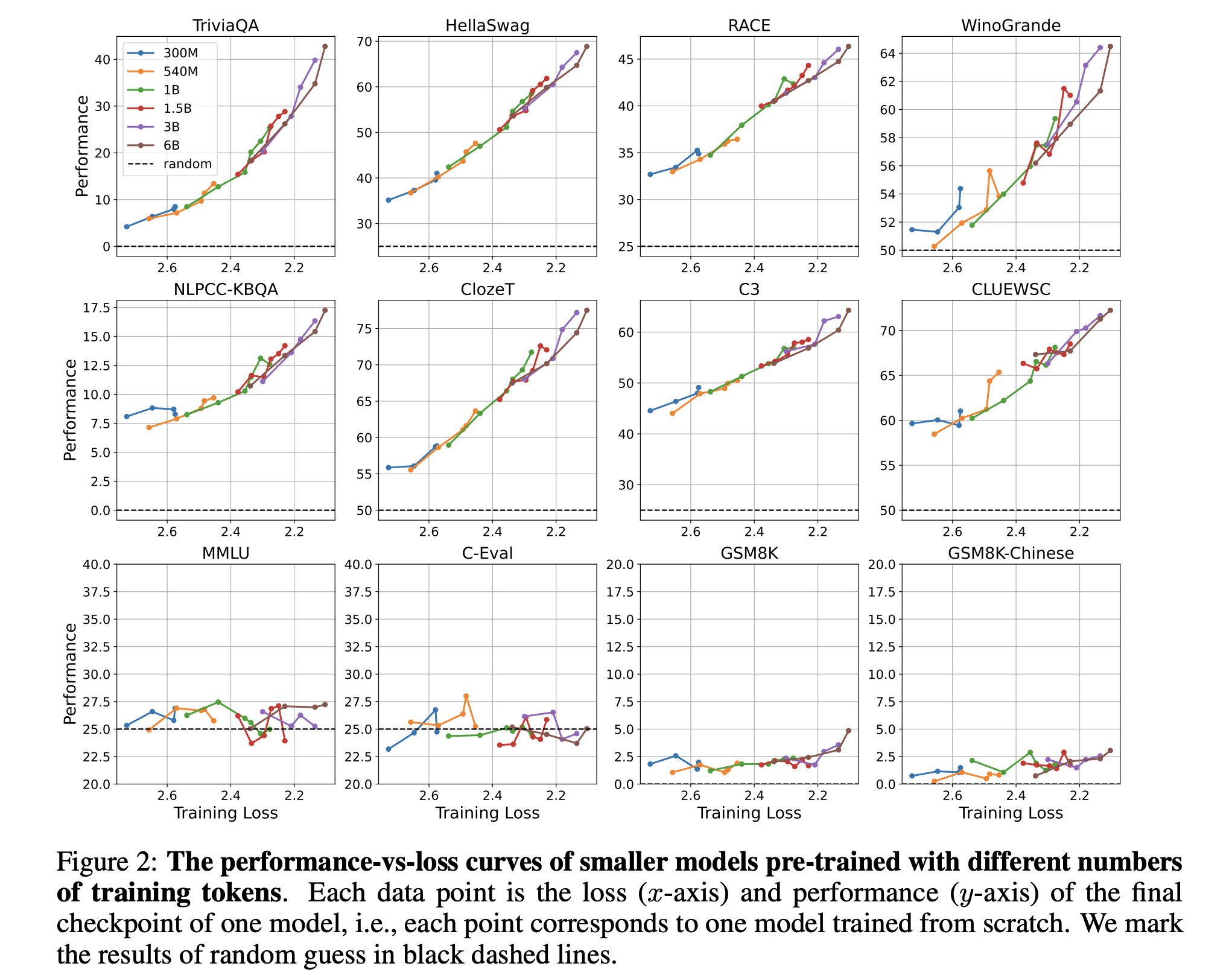
从预训练损失的角度,理解语言模型的涌现能力
原文:Understanding Emergent Abilities of Language Models from the Loss Perspective 摘要 本文从预训练损失的角度重新审视语言模型的涌现能力,挑战了以往以模型大小或训练计算量为标准的观念。通过实验,作者发现预训练损失是预测下游任务性能的关键指标,不同规模的模型在相同预训练损失下展现相似性能。这一新视角为理解语言

从预训练到通用智能(AGI)的观察和思考
1.预训练词向量 预训练词向量(Pre-trained Word Embeddings)是指通过无监督学习方法预先训练好的词与向量之间的映射关系。这些向量通常具有高维稠密特征,能够捕捉词语间的语义和语法相似性。最著名的预训练词向量包括Google的Word2Vec(包括CBOW和Skip-Gram两种模型)、GloVe(Global Vectors for Word Repre

标题:从预编译到链接:探索C/C++程序的翻译环境全貌
引言 在软件开发的世界里,我们通常会遇到两种不同的环境——翻译环境与运行环境。今天,我们将聚焦于前者,深入剖析C/C++程序生命周期中至关重要的“翻译环境”,即从源代码到可执行文件这一过程中涉及的四个关键阶段:预编译、编译、汇编和链接。 一、翻译环境概览 翻译环境是C/C++程序员眼中的炼金炉,它负责将人类可读、可理解的源代码转化为机器语言可以执行的二进制指令。这个转化过程并非一步到位,而是
美团好文:从预编译的角度理解Swift与Objective-C及混编机制
写在前面 本文涉及面较广,篇幅较长,阅读完需要耗费一定的时间与精力,如果你带有较为明确的阅读目的,可以参考以下建议完成阅读: 如果你对预编译的理论知识已经了解,可以直接从【`原来它是这样的】的章节开始进行阅读,这会让你对预编译有一个更直观的了解。如果你对 Search Path 的工作机制感兴趣,可以直接从【关于第一个问题】的章节阅读,这会让你更深刻,更全面的了解到它们的运作机制,如果您对 X