代表性专题

ACL22--基于CLIP的非代表性新闻图像的多模态检测
摘要 这项研究调查了假新闻如何使用新闻文章的缩略图,重点关注新闻文章的缩略图是否正确代表了新闻内容。在社交媒体环境中,如果一篇新闻文章与一个不相关的缩略图一起分享,可能会误导读者对问题产生错误的印象,尤其是用户不太可能点击链接并消费整个内容的情况下。我们提议使用预训练的CLIP(Contrastive Language-Image Pretraining)表示来捕捉多模态关系中语义不一致的程度。

MLM:多模态大型语言模型的简介、微调方法、发展历史及其代表性模型、案例应用之详细攻略
MLM:多模态大型语言模型的简介、微调方法、发展历史及其代表性模型、案例应用之详细攻略 目录 相关文章 AI之MLM:《MM-LLMs: Recent Advances in MultiModal Large Language Models多模态大语言模型的最新进展》翻译与解读 MLM之CLIP:CLIP(对比语言-图像预训练模型)的简介、安装和使用方法、案例应用之详细攻略 多模

Gartner《2024中国安全技术成熟度曲线》AI安全助手代表性产品:开发者安全助手D10
海云安关注到,近日,国际权威研究机构Gartner发布了《2024中国安全技术成熟度曲线》(Hype Cycle for Security in China,2024)报告。 在此次报告中,安全技术成熟度曲线将安全周期划分为技术萌芽期(Innovation Trigger)、期望膨胀期(Peak of Inflated Expectations)、泡沫破裂低谷期(Trough of Disill

从0开始学统计-战斗机保护和代表性抽样
1.什么是抽样研究?为什么要做抽样研究? 抽样研究是一种研究方法,它涉及从整体人群或群体中选取一部分样本来代表整体,以进行研究和推断。在抽样研究中,研究者从总体中选择一个相对较小的样本,通过对这个样本进行观察、实验或调查来推断总体的特征、趋势或关系。 抽样研究的目的在于: (1)节省时间和成本: 通过研究样本而不是整个总体,可以节省大量的时间和资源。这样的方法通常更经济高效。 (2)可行性

机器学习训练中常见的问题和挑战:训练数据的数量不足、训练数据不具代表性、低质量数据、无关特征、过拟合训练数据、欠拟合训练数据
1.50.机器学习训练中常见的问题和挑战 转载博文:https://blog.csdn.net/Datawhale/article/details/109006583 Datawhale干货 作者:奥雷利安·杰龙 由于我们的主要任务是选择一种学习算法,并对某些数据进行训练,所以最可能出现的两个问题不外乎是“坏算法”和“坏数据”,本文主要从坏数据出发,带大家了解目前机器学习面临的常见问题和挑战,

Qt 翻金币游戏项目(具有代表性)
文章目录 效果展示项目概述功能实现1,第一个场景构建2、第二个场景功能3、进入第三个场景 效果展示 项目概述 打开游戏,点击开始按钮进入第二个场景,进行选择关卡,进入第三个游戏场景,翻动当前金币他的周围(上下左右)会进行切换,游戏胜利显示胜利图标,可以通过,back按钮退回第二个和第一个场景。 可以根据源码,看这个篇文章,这篇文章大概梳理了一下整个项目的思路,对细

用Elasticsearch构建电商搜索平台,一个极有代表性的基础技术架构和算法实践案例(转)
转自:https://blog.csdn.net/jek123456/article/details/54562158 随着数据规模的爆炸式增长,如何从海量的历史,实时数据中快速获取有用的信息,变得越来越有挑战性。 电商数据系统主要类型 一个中等的电商平台,每天都要产生百万条原始数据,上亿条用户行为数据。一般来说,电商数据一般有3种主要类型的数据系统: 关系型数据库,大多数互联网公

RNN的四种代表性扩展—Attention and Augmented Recurrent Neural Networks(一)
看到一片不错的文章,按着自己的理解翻译的,水平有限,难免会有错误,各路大牛看到后感谢指出! Attention and Augmented Recurrent Neural Networks(二) 作者:CHRIS OLAH Google Brain SHAN CARTER Google Brain 原文:http://distill.pub/2016/augmented-rnns/#cit
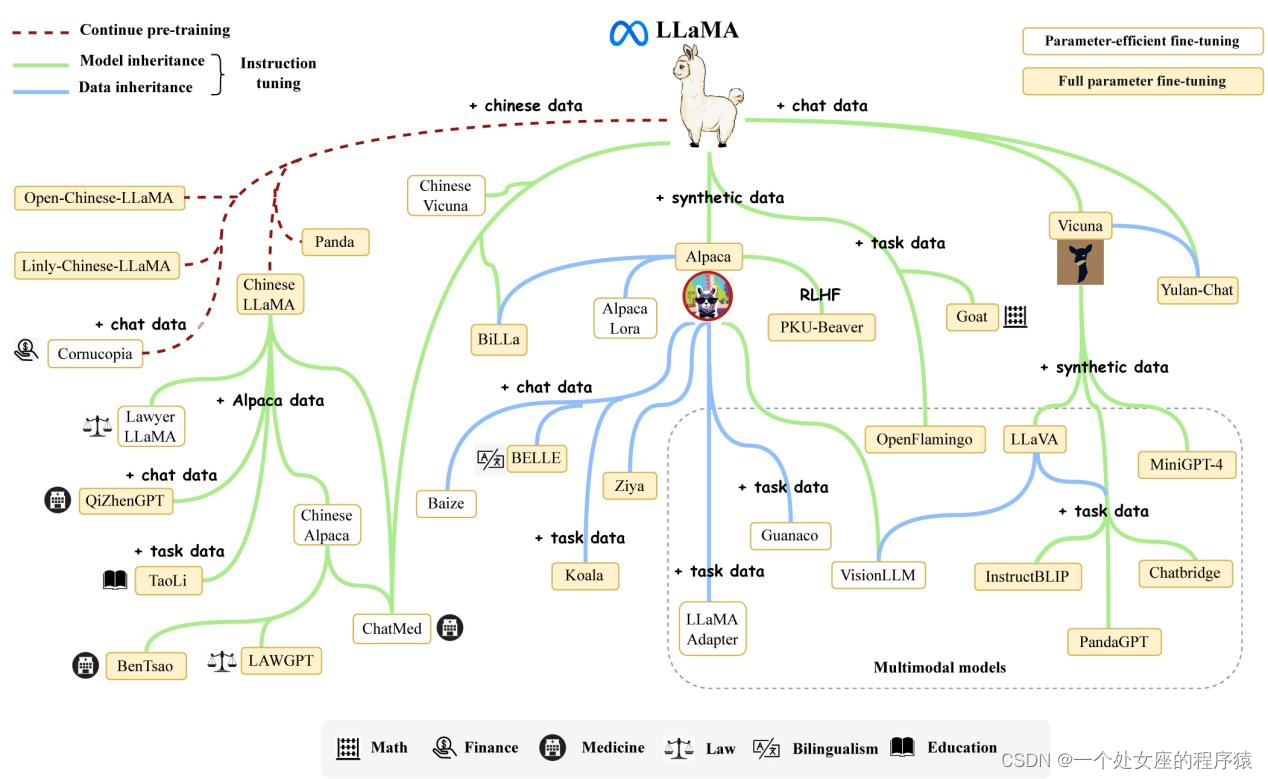
LLMs:《A Survey of Large Language Models大语言模型综述》的翻译与解读(一)之序言(挑战+LM四阶段+LLM与PLM的三大区别)、概述(两个代表性扩展定律/涌现能力
LLMs:《A Survey of Large Language Models大语言模型综述》的翻译与解读(一)之序言(挑战+LM四阶段+LLM与PLM的三大区别)、概述(两个代表性扩展定律/涌现能力三种典型/六大关键技术+GPT系列技术演进)、资源(开源模型/闭源API+六类语料库+三种框架库) 导读:LLMs(LLM)是指具有数十亿甚至数百亿参数的 Transformer 语言模型,近
LLMs:《A Survey of Large Language Models大语言模型综述》的翻译与解读(一)之序言(挑战+LM四阶段+LLM与PLM的三大区别)、概述(两个代表性扩展定律/涌现能力
LLMs:《A Survey of Large Language Models大语言模型综述》的翻译与解读(一)之序言(挑战+LM四阶段+LLM与PLM的三大区别)、概述(两个代表性扩展定律/涌现能力三种典型/六大关键技术+GPT系列技术演进)、资源(开源模型/闭源API+六类语料库+三种框架库) 导读:LLMs(LLM)是指具有数十亿甚至数百亿参数的 Transformer 语言模型,近

硕士研究生的第一道难题:如何快速了解某个研究领域的发展历程及代表性文献?——采集“Google学术”上的文献数据(一)
01. 真实场景交代 我是一名计算机视觉研究生,研究方向是「目标检测(Object Detection)」。 在详细阅读相关文献之前,我需要先了解这个领域的发展历程及每个时间段有代表性的文献。 02. 遇到的困难 如何找到这些相关的文献? 03. 明确目标 我希望尽可能找到所有与当前研究领域相关的文献。 04. 工具准备 4.1 领域相关的关键词表:目标检测、O