本文主要是介绍kaggle----NLP线性回归---Real or Not? NLP with Disaster Tweets,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
依然是按照老样子拿到了我们的训练集测试集还有提交模板
竞赛网站:
https://www.kaggle.com/c/nlp-getting-started/overview/description
数据初步可视化
import numpy as np
import pandas as pd
from sklearn import feature_extraction, linear_model, model_selection, preprocessing
train = pd.read_csv('路径/train.csv')
test = pd.read_csv('路径/test.csv')
此处以keyword作为例子,查看不同的度量对于预测结果的影响
#划分数据集,查看相应变量中的
target1=train.keyword[train.target == 1].value_counts()
target0=train.keyword[train.target == 0].value_counts()
df=pd.DataFrame({'target1':target1,'target0':target0})
df.plot(kind='bar',stacked=True,title='keyword')
当然呢,这个图可能略显的凌乱,但我们可以发现有的蓝色条尤其长是说明其中有的keyword是对于判断文本是否是有显著影响的,我们可以点开详情查看统计

发现了次数的统计,那么这几个keyword就可以作为后续的限制条件
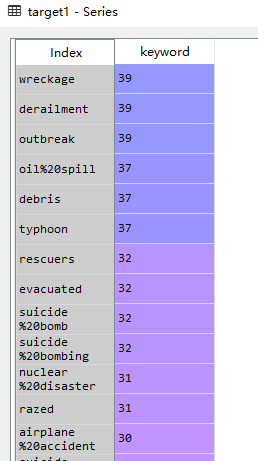
本例只做了简单样例,各位老板做参考就可
向量构筑
每条 tweet中包含的单词都是一个很好的指标,表明它们是否是真正的Disaster (可能并不完全正确)。
使用scikit learn中的countvector对每条tweet中的单词进行计数,并将它们转换为机器学习模型可以处理的数据。
注:在这种情况下,向量是机器学习模型可以使用的一组数字
用前五条为例
count_vectorizer = feature_extraction.text.CountVectorizer()
# count_vectorizer.get_feature_names() 可以查看生成的字典名# count_vectorizer.vocabulary_ 字典形式呈现,key:词,value:词频
# 让我们计算一下数据中前5条tweets的单词数量
example_train_vectors = count_vectorizer.fit_transform(train["text"][0:5])
## 我们在这里使用.todense(),因为这些向量是“离散的”(只保留非零元素以节省空间)
print(example_train_vectors[0].todense().shape)
print(example_train_vectors[0].todense())
参考:sklearn——CountVectorizer详解

上面告诉我们:
前五条 tweets中有54个独特的单词(或“标记”)。
第一条tweet([0])只包含其中一些唯一的标记——上面所有的非零计数都是第一条tweet中存在的标记。
现在为所有的tweets创建向量:
train_vectors = count_vectorizer.fit_transform(train_df["text"])## 注意,这里没有使用.fit_transform(),只是用了.transform()确保列向量中的标记是映射到测试向量的唯一标记
# 也就是说,训练集向量和测试集向量使用同一组变化
test_vectors = count_vectorizer.transform(test_df["text"])
线性模型
正如前面提到的,每条tweet中包含的文字是一个很好的指标,可以判断它们是否是Disaster。tweet中特定单词(或一组单词)的出现可能直接链接到该tweet是否真实。
假设这是一个线性关系,建立一个线性模型看看!
我们的向量很大,所以我们想推进模型的权重趋近于0但不完全消除,ridge regression是一个很好的方式
clf = linear_model.RidgeClassifier()
使用交叉验证,我们对已知数据的一部分进行训练,然后使用其他数据对其进行验证。
这次竞赛的评价标准是F1,所以我们的模型也选用这个标准

scores = model_selection.cross_val_score(clf, train_vectors, train_df["target"], cv=3, scoring="f1")

预测并提交模型
clf.fit(train_vectors, train_df["target"])

sample_submission = pd.read_csv("路径/sample_submission.csv")
sample_submission["target"] = clf.predict(test_vectors)
sample_submission.head()
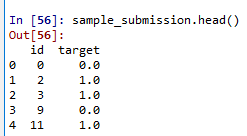
sample_submission.to_csv("路径/submission.csv", index=False)
完成,可以提交
这篇关于kaggle----NLP线性回归---Real or Not? NLP with Disaster Tweets的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








