kaggle专题

kaggle竞赛宝典 | Mamba模型综述!
本文来源公众号“kaggle竞赛宝典”,仅用于学术分享,侵权删,干货满满。 原文链接:Mamba模型综述! 型语言模型(LLMs),成为深度学习的基石。尽管取得了令人瞩目的成就,Transformers仍面临固有的局限性,尤其是在推理时,由于注意力计算的平方复杂度,导致推理过程耗时较长。 最近,一种名为Mamba的新型架构应运而生,其灵感源自经典的状态空间模型,成为构建基础模型的有力替代方案

Kaggle刷比赛的利器,LR,LGBM,XGBoost,Keras
刷比赛利器,感谢分享的人。 摘要 最近打各种比赛,在这里分享一些General Model,稍微改改就能用的 环境: python 3.5.2 XGBoost调参大全: http://blog.csdn.net/han_xiaoyang/article/details/52665396 XGBoost 官方API: http://xgboost.readthedocs.io/en

24/9/3算法笔记 kaggle泰坦尼克
题目: 这次我用两种算法做了这道题 逻辑回归二分类算法 import pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.linear_model import LogisticRegr

Kaggle竞赛——手写数字识别(Digit Recognizer)
目录 1. 数据集介绍2. 数据分析3. 数据处理与封装3.1 数据集划分3.2 将数据转为tensor张量3.3 数据封装 4. 模型训练4.1 定义功能函数4.1 resnet18模型4.3 CNN模型4.4 FCNN模型 5. 结果分析5.1 混淆矩阵5.2 查看错误分类的样本 6. 加载最佳模型7. 参考文献 本次手写数字识别使用了resnet18(比resnet50精度更

Kaggle克隆github项目+文件操作+Kaggle常见操作问题解决方案——一文搞定,以openpose姿态估计项目为例
文章目录 前言一、Kaggle克隆仓库1、克隆项目2、查看目录 二、安装依赖三、文件的上传、复制、转移操作1.上传.pth文件到input目录2、将权重文件从input目录转移到工作目录 三、修改工作目录里的文件内容1、修改demo_camera.py内容 四、运行! 前言 想跑一些深度学习的项目,但是电脑没有显卡,遂看向云服务器Kaggle,这里可以每周免费使用30h的GP

机器学习学习--Kaggle Titanic--LR,GBDT,bagging
参考,机器学习系列(3)_逻辑回归应用之Kaggle泰坦尼克之灾 http://www.cnblogs.com/zhizhan/p/5238908.html 机器学习(二) 如何做到Kaggle排名前2% http://www.jasongj.com/ml/classification/ 一、认识数据 1.把csv文件读入成dataframe格式 import pandas as

kaggle平台free使用GPU
1、注册 请保证在【科学上网】条件下进入如下操作,只有在注册账户和手机号验证时需要。 step1:注册账户 进入kaggle官网:https://www.kaggle.com/,点击右上角【Register】进入注册页面 最好选择使用邮箱注册(!!!如果你先用goole注册,然后改成其他邮箱,再用其他邮箱登录时会报错,需要重新找回密码) 输入【邮箱】、【密码】和【用户名】后,勾选

Kaggle竞赛:Rossmann Store Sales第66名策略复现
之前做过一次Kaggle的时间序列竞赛数据集练习:CSDN链接效果并不理想,之后在Kaggle的评论中又找到了各式各样的模型方法,其中我还手动还原过第三名的Entity Embedding:CSDN链接。这个参赛方法中,使用了除了比赛给出的数据以外的外部数据(天气数据等)。而这次,我准备还原一个没有使用外部数据且方法较为简单,但是效果较好的策略。也就是第66名的策略。 详细的策略可以看这里 R语言

kaggle竞赛宝典 | 量化竞赛第一名的网络模型
本文来源公众号“kaggle竞赛宝典”,仅用于学术分享,侵权删,干货满满。 原文链接:量化竞赛第一名的网络模型 1 简介 今天我们重温Jane Street 大赛第一名的网络模型。该次赛事数据集包含了一组匿名的特征,feature_{0...129},代表真实的股市数据。数据集中的每一行代表一个交易机会,你需要预测一个动作值:1表示进行交易,0表示放弃。每笔交易都有一个相关的权重和响应,它们

【Kaggle】练习赛《有毒蘑菇的二分类预测》(下)
前言 上篇 《有毒蘑菇的二分类预测 》(上) 用ColumnTransformer和Pipeline 技术来提升缺失值和建模的方法,本篇将用特征工程的方法,将特征扩展,由原先的21个特征扩展成118个特征,再用深度学习的方法进行建模以达到较好的成绩,同时,在这篇里增加了上篇没有EDA部分,更好的展示数据集。 题目说明 加载库 import pandas as pdimport num

【Kaggle】练习赛《有毒蘑菇的二分类预测》(上)
前言 本篇文章介绍的是Kaggle月赛《Binary Prediction of Poisonous Mushrooms》,即《有毒蘑菇的二分类预测》。与之前练习赛一样,这声比赛也同样适合初学者,但与之前不同的是,本次比赛的数据集有大量的缺失值,如何处理这些缺失值,直接影响比赛的成绩。因此,本期用两篇文章用不同的方法来处理这些,至于用什么模型,模型的参数将不是本期的重点。第一篇使用ColumnT

Kaggle比赛:成人人口收入分类
拿到数据首先查看数据信息和描述 import pandas as pd import seaborn as sns import matplotlib.pyplot as plt # 加载数据(保留原路径,但在实际应用中建议使用相对路径或环境变量) data = pd.read_csv(r"C:\Users\11794\Desktop\收入分类\training.csv", e
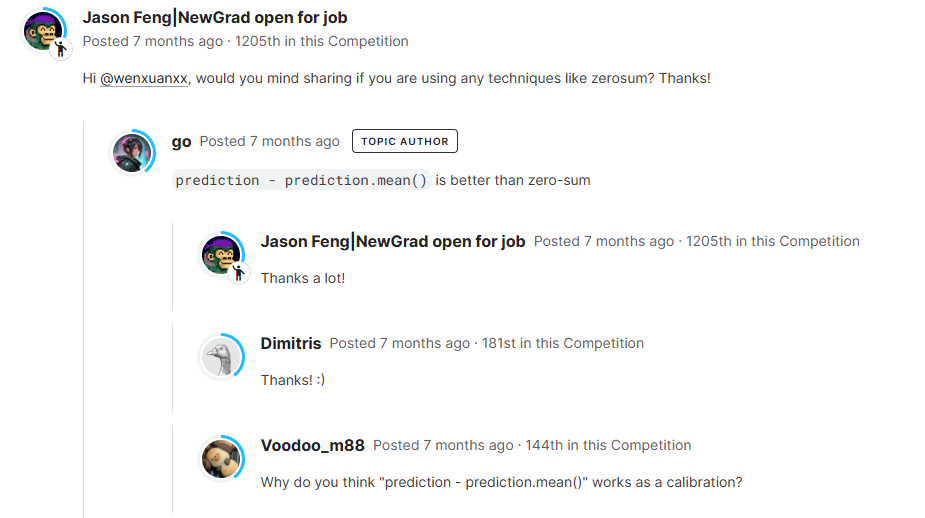
【Kaggle量化比赛】Top讨论
问: 惊人的单模型得分,请问您使用了多少个特征来获得如此高的得分?我也在使用LGB模型。 答 235个特征(180个基本特征+滚动特征) 问: 您是在使用Polars进行特征工程还是仅依赖于Pandas+Numba/多进程?即使进行了Numba优化,我也发现当滚动特征过多时,推理速度会非常慢。在Colab T4上使用在线流式评估,完成一个qp需要超过7秒。 答 使用Numba和多进程
![Kaggle-Camera_Model_Identification 比赛记录总结[19/582(Top 4%)]](/front/images/it_default.jpg)
Kaggle-Camera_Model_Identification 比赛记录总结[19/582(Top 4%)]
这篇博客记录自己在这次kaggle比赛中做的工作。成绩:19/582(Top 4%) Kaggle比赛地址 我的代码github地址 这次比赛是给出10个相机拍摄的照片,然后给出测试图片,区分是哪个相机拍摄的。训练集中每类照片数量相同,每类都是由同一个手机拍摄的照片。测试集中,每类的照片都是来自另外一个手机,一半的图片可能被用了八种可能的操作。 总结: 1. 更多的数据。
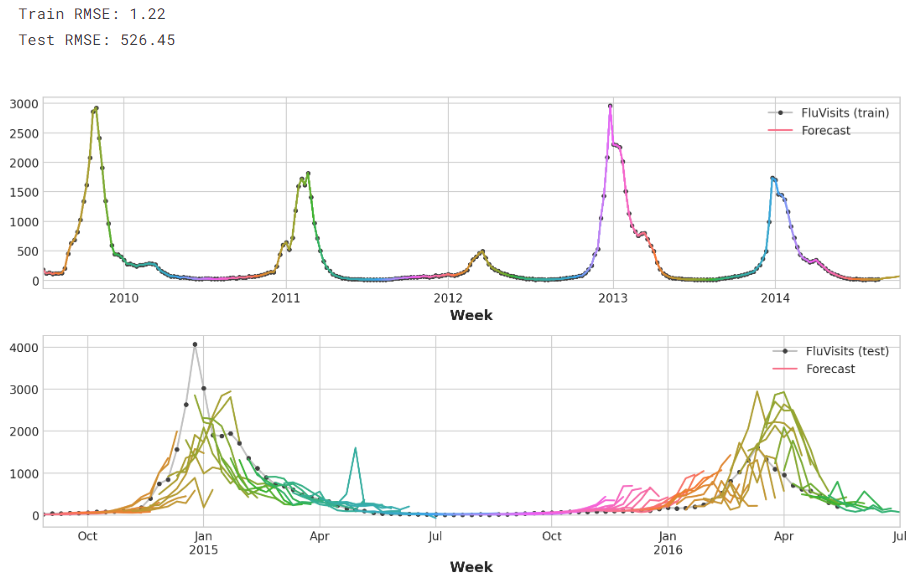
Python学习从0开始——Kaggle时间序列002
Python学习从0开始——Kaggle时间序列002 一、作为特征的时间序列1.串行依赖周期 2.滞后序列和滞后图滞后图选择滞后 3.示例 二、混合模型1.介绍2.组件和残差3.残差混合预测4.设计混合模型5.使用 三、使用机器学习进行预测1.定义预测任务2.为预测准备数据3.多步骤预测策略3.1 Multioutput模型3.2 直接策略3.3 递归策略3.4 DirRec策略 4.使用

动手学深度学习4.10 实战Kaggle比赛:预测房价-笔记练习(PyTorch)
以下内容为结合李沐老师的课程和教材补充的学习笔记,以及对课后练习的一些思考,自留回顾,也供同学之人交流参考。 本节课程地址:实战 Kaggle 比赛:预测房价_哔哩哔哩_bilibili 本节教材地址:4.10. 实战Kaggle比赛:预测房价 — 动手学深度学习 2.0.0 documentation (d2l.ai) 本节开源代码:...>d2l-zh>pytorch>chapter_m
动手学深度学习——Kaggle小白入门
1. kaggle注册 注册网址:https://www.kaggle.com 注册账号不需要代理,但手机号验证需要代理。如果要使用GPU或TPU,则需要进行手机号验证。 手机号验证位置:右上角头像的settings界面。 手机号验证时会有几个问题: 无验证码,提示:Captcha must be filled out. 原因:人机验证组件在国内被拦截,所以看不到验证按钮,需要

Kaggle——Deep Learning(使用 TensorFlow 和 Keras 为结构化数据构建和训练神经网络)
1.单个神经元 创建一个具有1个线性单元的网络 #线性单元from tensorflow import kerasfrom tensorflow.keras import layers#创建一个具有1个线性单元的网络model=keras.Sequential([layers.Dense(units=1,input_shape=[3])]) 2.深度神经网络 构建
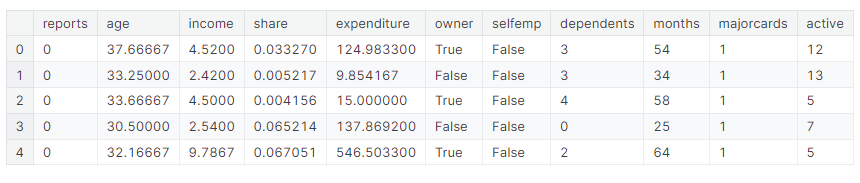
Python学习从0开始——Kaggle机器学习004总结2
Python学习从0开始——Kaggle机器学习004总结2 一、缺失值二、分类变量2.1介绍2.2实现1.获取训练数据中所有分类变量的列表。2.比较每种方法方法1(删除分类变量)方法2(序数编码)方法3独热编码 三、管道3.1介绍3.2实现步骤1:定义预处理步骤步骤2:定义模型步骤3:创建和评估管道 四、交叉验证1.介绍2.什么时候应该使用交叉验证?3.使用 五、XGBoost5.1

kaggle:房价预测
比赛链接 结果展示 结果链接 8848是密码 文章目录 数据处理调包部分拒绝掉包岭回归理论代码实践结果 自助采样理论代码 集成学习前言Bagging理论Bagging-Ridge代码Bagging-Ridge实践Bagging-Ridge结果 Tricks 数据处理 #打开文件import pandas as pddataset1=pd.read_csv("train.
kaggle竞赛实战7——其他方案之lightgbm
本文换种方案,用wrapper+lightgbm建模+TPE调优 接下来是特征筛选过程,此处先择使用Wrapper方法进行特征筛选,通过带入全部数据训练一个LightGBM模型,然后通过观察特征重要性,选取最重要的300个特征。当然,为了进一步确保挑选过程的有效性,此处我们考虑使用交叉验证的方法来进行多轮验证。实际多轮验证特征重要性的过程也较为清晰,我们只需要记录每一轮特征重要性,并在最后进行简
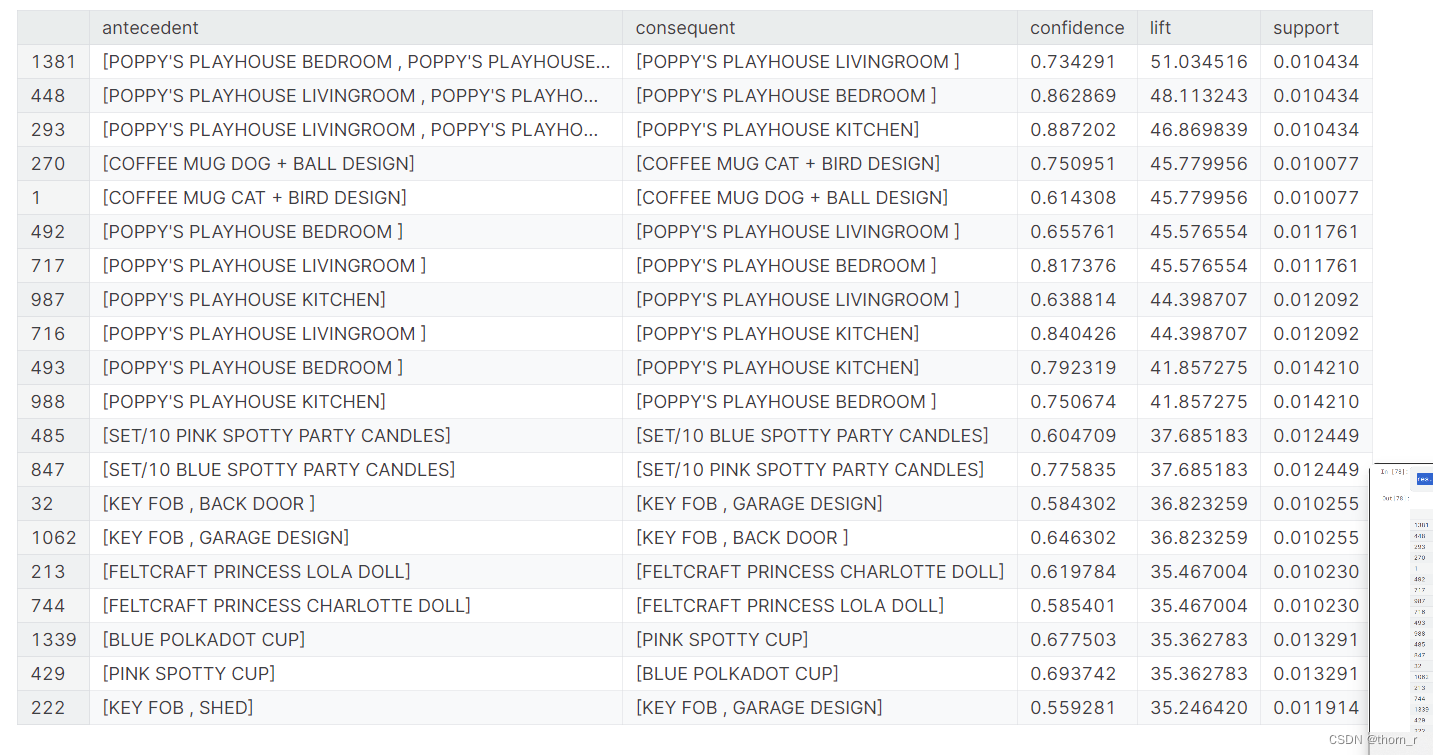
Kaggle线上零售 CRM分析(RFM+BG-NBD+生存分析+PySpark)
数据集地址:数据集地址 我的NoteBook地址:NoteBook地址 这个此在线零售数据集包含2009年12月1日至2011年12月9日期间的在线零售的所有交易。该公司主要销售独特的各种场合礼品。这家公司的许多客户都是批发商。本文将通过pyspark对数据进行导入与预处理,进行可视化分析并使用RFM、生存分析与BG-NBD模型进行对购买客户的各项分析。 1、数据集导入与清洗预处理 这一部分我
机器学习-11-使用kaggle命令下载数据集和操作指南
参考kaggle API 命令下载数据集 参考Kaggle操作完整指南(2023版) 参考Kaggle如何入门? 1 kaggle操作指南 Kaggle 是一个流行的数据科学竞赛平台。由 Goldbloom 和 Ben Hamner 创建于 2010 年。为什么这两个家伙要创立这样一个平台呢? 数据科学社区一直有这样一个难题:对于同一个问题,可以有多个模型来解决,但是研究者不可能在一开始就了解

kaggle竞赛实战3
接前文,本文主要做以下几件事: 1、把前面处理完的几个表拼成一个大表 2、做特征衍生(把离散特征和连续特征两两组合得出) # In[89]: #开始拼接表 transaction = pd.concat([new_transaction, history_transaction], axis=0, ignore_index=True)#最后一个参数表示产生新的索引 # In[91]
[Kaggle]Digit Recognizer
地址:https://www.kaggle.com/c/digit-recognizer 这同样是一道入门的KAGGLE题目。题目大意是给出一系列的灰度图像(用CSV表格表示像素),来预测该图像是何种数字。这是一个比较经典的图片,对应的方法有很多。可以使用传统的机器学习算法来进行计算,也可以使用深度学习的方法进行。在这一次我使用的是机器学习的SVC(线性支持分类器)来进行处理的。 第一步依然是
[Kaggle]House Prices: Advanced Regression Techniques
1、背景说明 2、前期准备 3、程序设计 4、知识点说明 5、测试结果 6、总结 7、附录:解释特征 1、背景说明 1.1 项目名称: House Prices_Advanced Regression Techniques https://www.kaggle.com/c/house-prices-advanced-regression-techniques 1.2 实现目