本文主要是介绍动手学深度学习——Kaggle小白入门,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. kaggle注册
注册网址:https://www.kaggle.com
注册账号不需要代理,但手机号验证需要代理。如果要使用GPU或TPU,则需要进行手机号验证。
手机号验证位置:右上角头像的settings界面。
手机号验证时会有几个问题:
- 无验证码,提示:Captcha must be filled out.
- 原因:人机验证组件在国内被拦截,所以看不到验证按钮,需要代理才能看到
人机身份验证。
- 如果出现人机验证窗口,必须在代理状态下才能激活。一旦激活之后,必须切回正常状态,再进行国内的电话验证,不然代理的区域,跟验证电话的区域不一致,会报验证失败。
手验证完结果:PhoneVerification一栏必须是verified才可以。
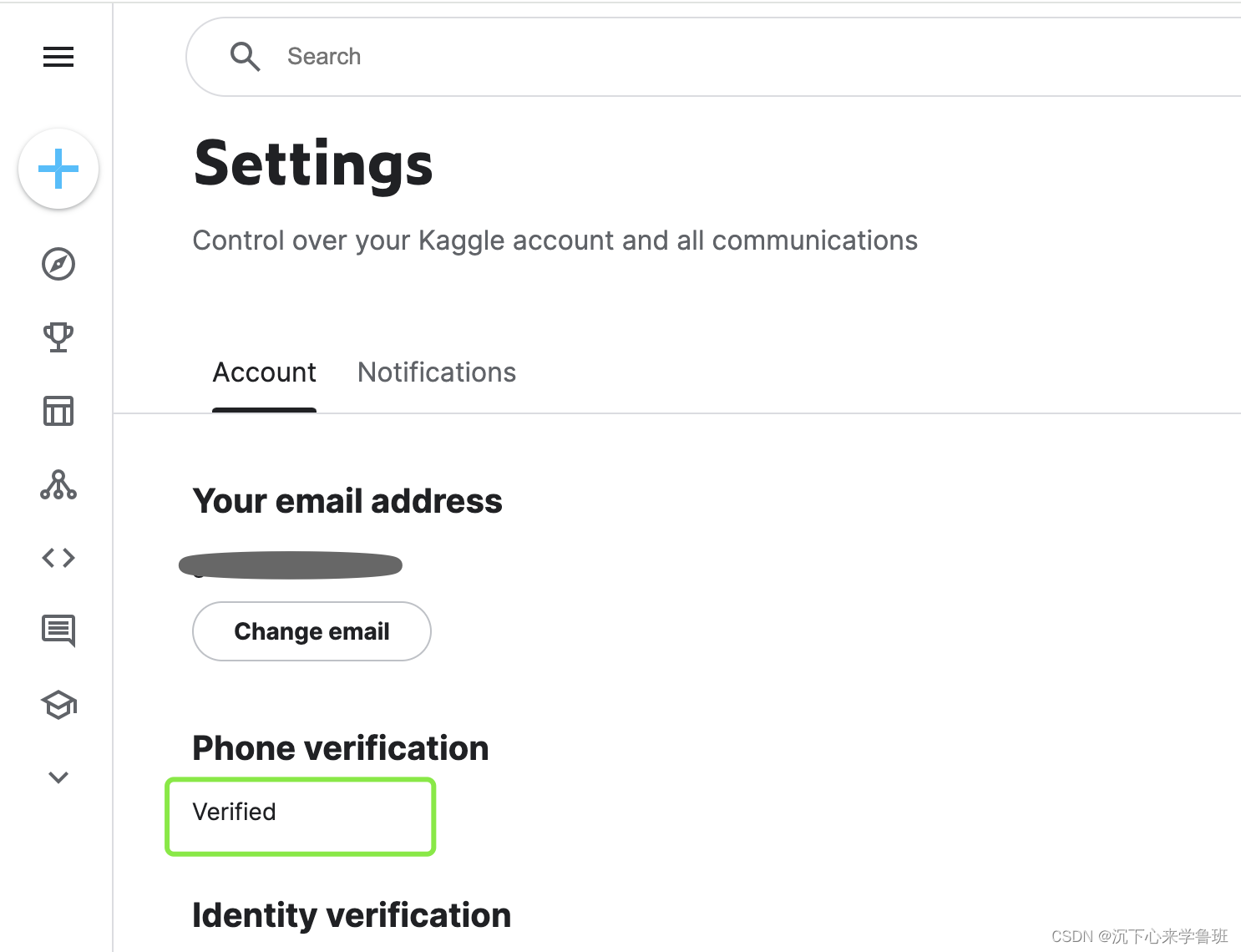
更详细的手机验证方法见文章最后参考资料中的链接。
2. 新建notebook
写代码前需要先创建notebook。

创建完后操作界面如下图所示,左边为代码区,右边为数据区。
- notebook创建完后,默认会自动创建两个目录:输入/kaggle/input和输出/kaggle/output。
- 代码区会自动生成一段默认代码,功能是打印输入目录中的文件列表。
这个notebook的具体操作与jupyter notebook完全一致。
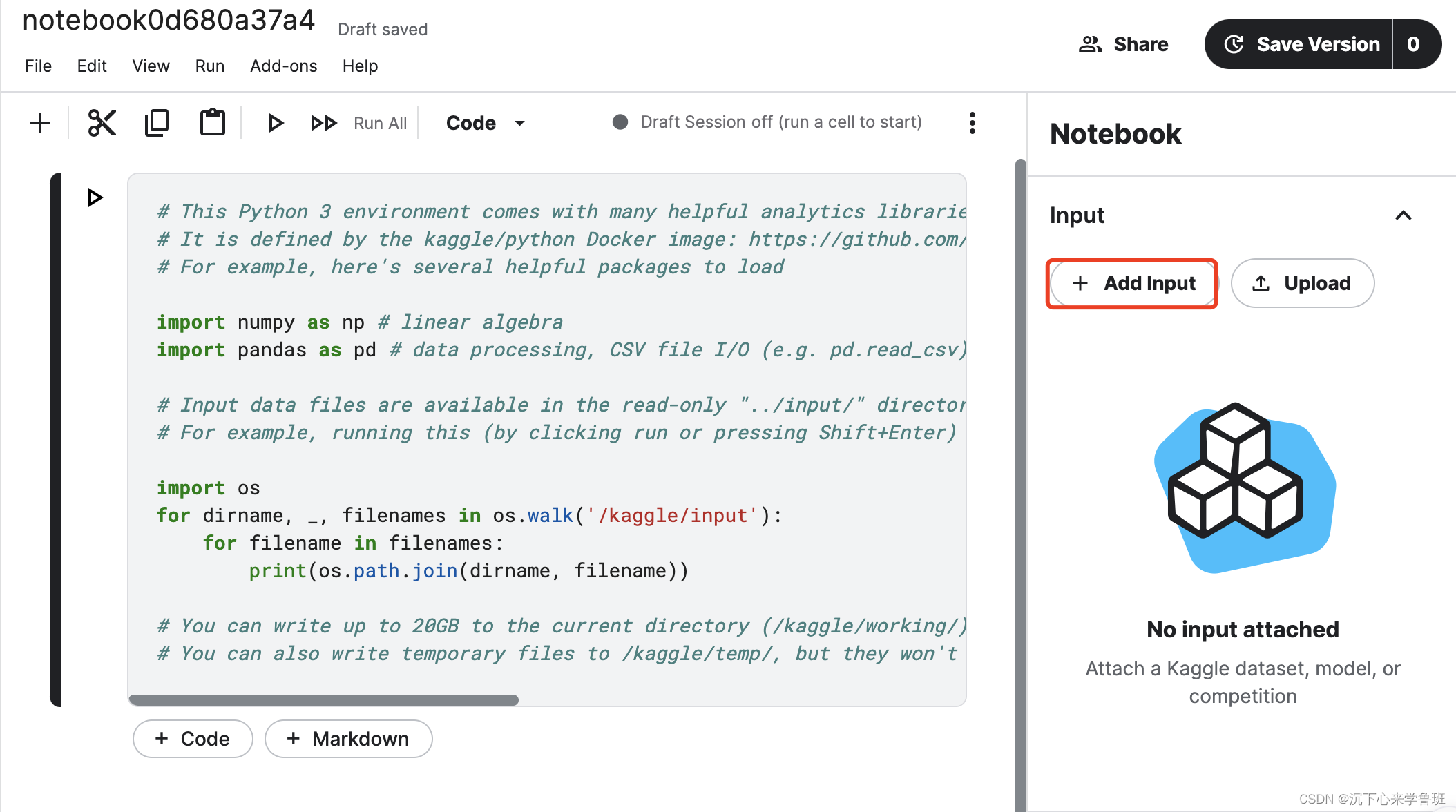
此notebook在创建时已经默认安装了python环境和pytorch库。
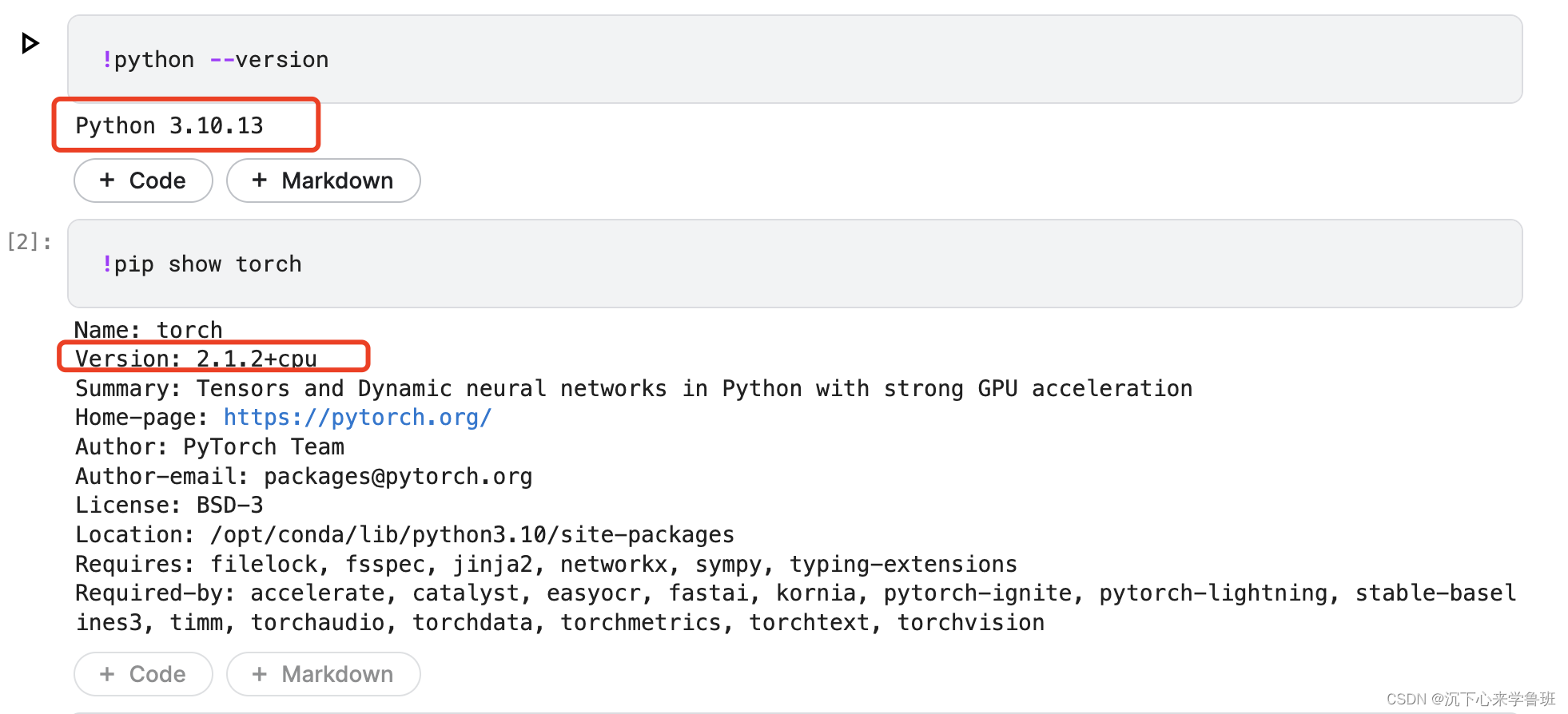
3. 传数据
模型训练都需要使用大批量的专用数据集,传数据可分为两种操作:
- Add Input: 添加kaggle平台上已有数据集。
- upload:上传数据集,支持本地压缩文件,也支持指定一个远程的URL来下载
不论哪种操作方式,传的数据都会保存到/kaggle/input文件夹中。
这里以Add Input为例来演示如何传数据。

添加好数据集后如下所示:
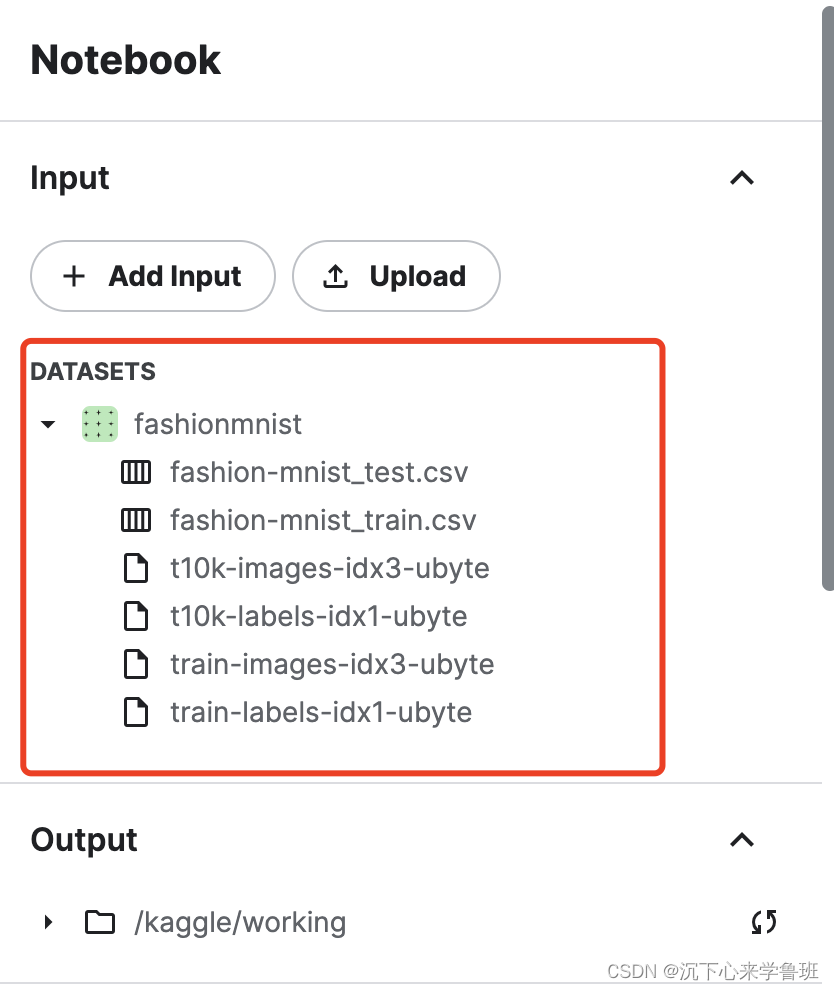
此时,我们运行代码区的默认代码,就能打印出刚添加的数据集文件列表。
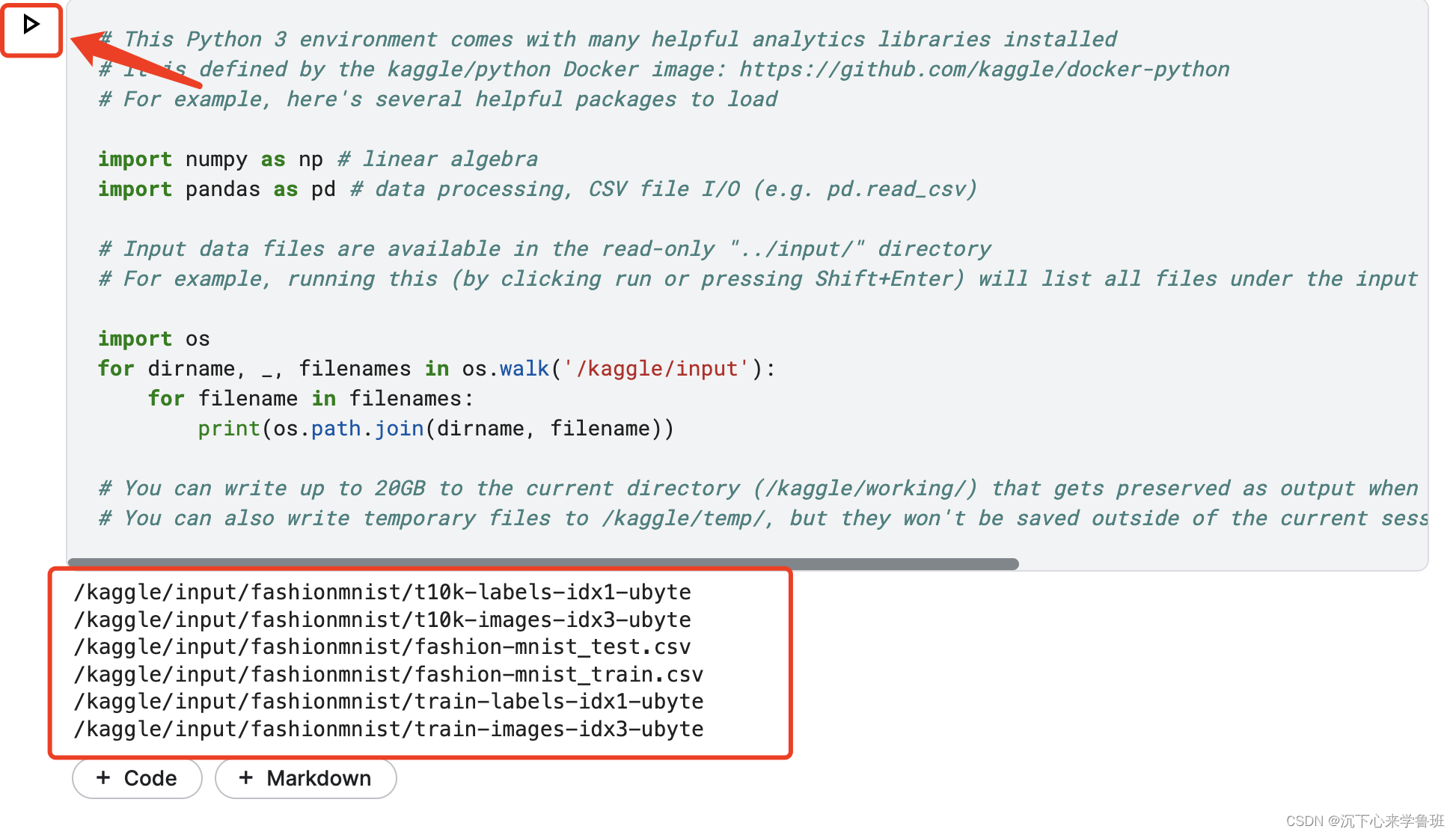
可以尝试用pandas库来读取下数据:
具体pandas操作方法可参考:动手学深度学习——pandas
df = pd.read_csv("/kaggle/input/fashionmnist/fashion-mnist_train.csv")
print(df.shape)>>> (60000, 785)
可以看到,该数据集有60000行、785列。
再尝试读取下前三行数据的内容。
print(df.iloc[0:3,:])label pixel1 pixel2 pixel3 pixel4 pixel5 pixel6 pixel7 pixel8 \
0 2 0 0 0 0 0 0 0 0
1 9 0 0 0 0 0 0 0 0
2 6 0 0 0 0 0 0 0 5 pixel9 ... pixel775 pixel776 pixel777 pixel778 pixel779 pixel780 \
0 0 ... 0 0 0 0 0 0
1 0 ... 0 0 0 0 0 0
2 0 ... 0 0 0 30 43 0 pixel781 pixel782 pixel783 pixel784
0 0 0 0 0
1 0 0 0 0
2 0 0 0 0 [3 rows x 785 columns]
FashionMnist是一个时装分类的图像数据集,每条数据的第一列为标签分类(0-9),表示10种时装分类。后面784列表示28x28图像展开后每一个像素的值。
iloc是pandas的一个切片操作,与python中的数组切片功能相似,不同的是:python中是对一维数组进行切片,iloc可以同时对多维数组进行切片。
4. 使用GPU
默认情况下,创建的notebook都是没有启用GPU的,可以通过简单API来查看运行环境上的CPU和GPU信息。
import os
import torchprint(f"cpu nums:{os.cpu_count()}")# 检查是否有可用的 GPU
if torch.cuda.is_available():# 获取 GPU 设备信息for i in range(torch.cuda.device_count()):gpu = torch.cuda.get_device_properties(i)print("GPU {}:".format(i))print("型号:", gpu.name)print("核心数:", gpu.multi_processor_count) # 核心数print("显存大小:", gpu.total_memory // (1024**2), "MB") # 显存大小,转换为 MBprint("-----------")
else:print("没有可用的 GPU。")
cpu nums:4
没有可用的 GPU。
启用GPU: 右边的功能框找见Session options—>accelerator—>选择GPU T4 x2。
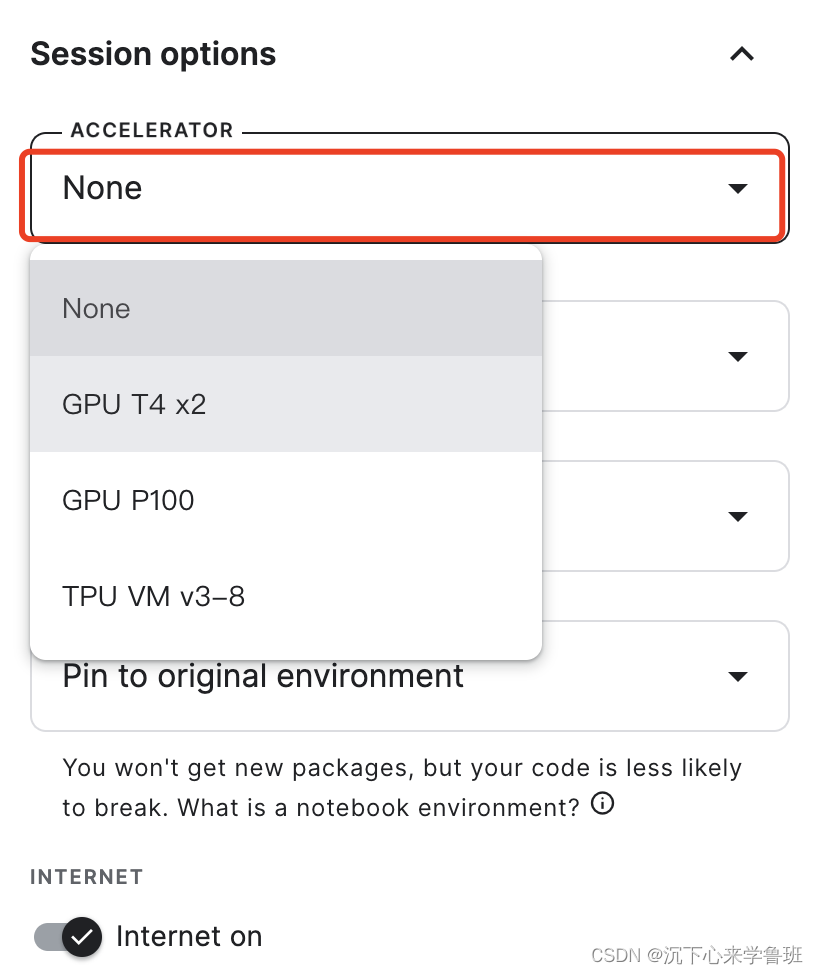
此时再运行上面的GPU设备检测代码,已经有了GPU设备信息:
cpu nums:4
GPU 0:
型号: Tesla T4
核心数: 40
显存大小: 15102 MB
-----------
GPU 1:
型号: Tesla T4
核心数: 40
显存大小: 15102 MB
-----------
简单使用下GPU做矩阵乘法运算:
GPU主要用来加速pytorch,tensorflow,pandas、numpy是不会加速的。
# 创建两个随机张量
a = torch.rand(3, 4)
b = torch.rand(4, 3)# 将张量移动到GPU上
if torch.cuda.is_available():a = a.cuda()b = b.cuda()c = torch.matmul(a, b)print(f"a: {a}")print(f"b: {b}")print(f"c: {c}")
a: tensor([[0.1732, 0.5473, 0.1821, 0.8392],[0.5551, 0.6203, 0.9935, 0.3267],[0.4213, 0.0994, 0.7320, 0.7110]], device='cuda:0')
b: tensor([[0.9064, 0.8337, 0.6155],[0.7991, 0.4399, 0.3409],[0.8997, 0.2004, 0.2329],[0.2817, 0.1979, 0.8481]], device='cuda:0')
c: tensor([[0.9946, 0.5877, 1.0473],[1.9847, 0.9994, 1.0616],[1.3201, 0.6824, 1.0667]], device='cuda:0')
可以看到,a、b、c三个矩阵均位于cuda 0号设备上。
CUDA是NVIDIA提供的一种GPU并行计算框架,在pytorch中使用 .cuda() 表示让我们的模型或者数据从CPU迁移到GPU上(默认是0号GPU),通过GPU开始计算。
5. 释放GPU
kaggle为每位用户只提供每周30h的免费GPU使用时间,所以用完后要及时手动释放来节省GPU可用时长。
注意:GPU使用时长的计算不是以实际运算时间来计,而是以用户绑定GPU设备的时长来计,这意味着哪怕你的代码没有在GPU上运行,只是简单绑定也会计算你的使用时长。
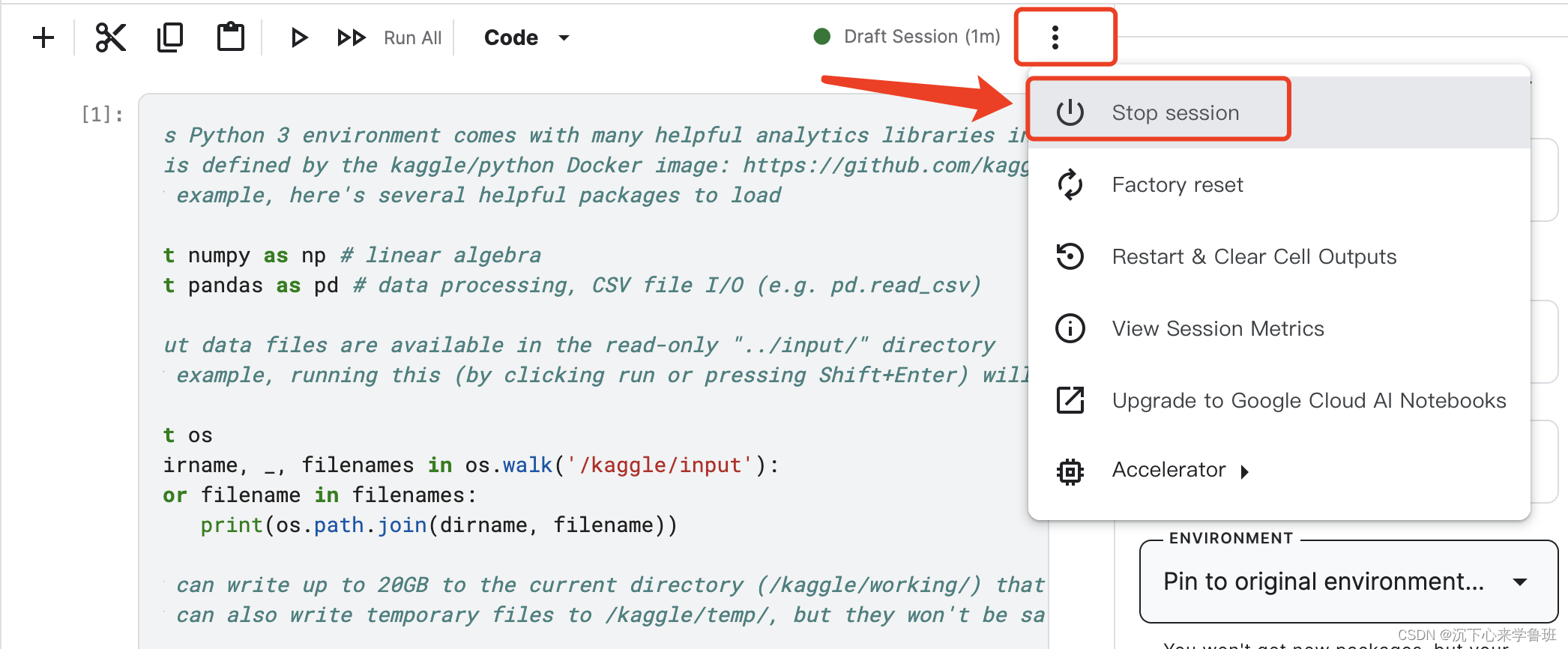
方式1:将Accelerator置为None来单独释放GPU设备。

方式2:停止会话来释放GPU设备。
如果直接关闭网页(没有执行上面的操作),GPU设备是不会及时释放的,只能等系统检测到设备空闲超时后才会释放,具体空闲超时时间数分钟到半个小时不等。
参考资料
- 手机验证方法
这篇关于动手学深度学习——Kaggle小白入门的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



