路透社专题

python深度学习---路透社多分类
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport pylabfrom pandas import DataFrame, Series#路透社数据集#多分类问题from keras.datasets import reuters(train_data, train_labels), (te

路透社:国际权威医学组织Cochrane证实电子烟可戒烟
10月15日,路透社报道了国际最权威的循证医学学术组织——考克兰协作组织(Cochrane Collaboration,以下简称Cochrane)发布的一则综述。综述研究表明,电子烟具有戒烟作用,且效果优于尼古丁替代疗法等手段。以下为路透社报道全文: 上周三(10月14日),一份新综述显示,电子烟的戒烟效果优于尼古丁贴剂和尼古丁口香糖(均为尼古丁替代疗法 译者注),且电子烟比传统香烟更

(路透社数据集)新闻分类:多分类问题实战
目录 前言一、电影评论分类实战1-1、数据集介绍&数据集导入&分割数据集1-2、字典的键值对颠倒&数字评论解码1-3、将整数序列转化为张量(训练数据和标签)1-4、搭建神经网络&选择损失函数和优化器&划分出验证集1-5、开始训练&绘制训练损失和验证损失&绘制训练准确率和验证准确率1-6、在测试集上验证准确率 二、调参总结三、碎碎念(绘制3D爱心代码)总结 前言 对于路透社数

路透社新闻分类(多分类)--python深度学习
import keraskeras.__version__ ‘2.0.8’ 路透社新闻分类(多分类) 多分类任务(Keras内置数据集) 路透社数据集,它包含许多短新闻及其对应的主题,由路透社在 1986 年发布。它是一个简单的、广泛使用的文本分类数据集。 包括 46 个不同的主题 1.数据导入 from keras.datasets import reuters(train_d

路透社新闻分类--自然语言处理
路透社新闻分类 数据准备和载入查看文件基本信息创建网络模型训练网络模型词向量预训练与模型优化 embedding_matrix = pd.read_csv('embedding_matrix.csv')embedding_matrix import numpy as npimport pandas as pdfrom tkinter import _flattenimport

keras实现路透社新闻主体的分类
keras实现路透社新闻主体的分类 参考书目:《Python深度学习》。 Just for fun!!! import kerasfrom keras.datasets import reutersimport matplotlib.pyplot as pltimport numpy as np Using TensorFlow backend. 1 加载路透社数据集 (trai

使用Keras处理深度学习中的多分类问题——路透社新闻分类
简介 本文将着手构建一个网络,将路透社新闻划分为46个互斥的主题,与二分类问题不同,这是一个多分类问题。 关于二分类问题的处理方式,请参考:使用Keras处理深度学习中的二分类问题——Imdb影评分类。 对于某个新闻,它只能划分到46个类别中的一个,所以这个问题又是单标签、多分类问题。如果每条新闻可以划分到不同的主题,那就是多标签、多分类问题了。 路透社数据集由路透社在1986年发布,


3.Keras实现路透社新闻分类
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、路透社数据集二、步骤1.导入Keras2、加载路透社数据集3、准备数据4、构建网络4.1 构建模型4.2 编译模型4.3 准备验证集4.4 训练模型 5、绘制图像6、重新训练一个新的模型7、使用训练好的网络在新数据上生成预测结果8、处理标签和损失的另一种方法9、 中间层维度足够大的重要性 总结

keras 实现reuters路透社新闻多分类
路透社reuters话题分类 来自路透社的11,228条新闻数据集标有46个主题。与IMDB数据集一样,每条线都被编码为一系列字索引。 reuters数据集无法下载,详见本篇博客提供下载和使用: https://blog.csdn.net/sinat_41144773/article/details/89843688 代码实现 from keras.datasets

【我的python机器学习之路·6】用keras做路透社新闻分类
本系列日记GitHub: https://github.com/zhengyuv/MyPyMLRoad 欢迎follow和star。 代码: # -*- coding: utf-8 -*-"""Created on Fri Nov 30 09:22:03 2018@author: zhengyuv"""from keras.datasets import reutersimpo
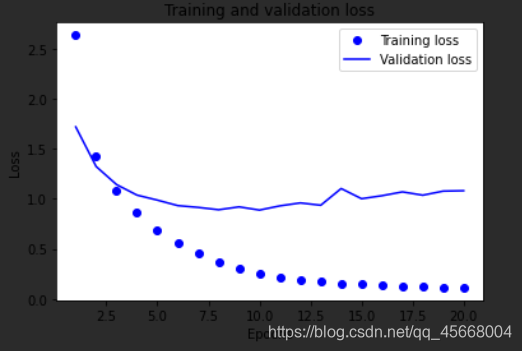
【In Action】Keras 实现“路透社数据集”的新闻分类(多分类任务)
本节使用路透社数据集,它包含许多短新闻及其对应的主题,由路透社在 1986 年发布。它是一个简单的、广泛使用的文本分类数据集。它包括 46 个不同的主题:某些主题的样本更多,但训练集中每个主题都有至少 10 个样本。 该数据集已被 Keras 内置。 步骤: 1. 加载数据 import kerasfrom keras.datasets import reuters(train_data,

路透社新闻 --- jsoup解析html
广告时间:张大妈 好看美剧 妹子图 路透中文网:http://cn.reuters.com/ 本Demo主要使用 jsoup 实现html解析和数据展示 所以只取其中三个部分(热点文章,中国财经,国际财经) 其他组件: PagerSlidingTabStrip ,ViewPager,Fragment结合使用 下拉刷新使用XListView 源码下载地址

Keras学习之4:多分类问题(reuters路透社新闻数据为例)
本数据库包含来自路透社的11,228条新闻,分为了46个主题。与IMDB库一样,每条新闻被编码为一个词下标的序列。上代码: from keras.datasets import reutersfrom keras.utils.np_utils import to_categoricalfrom keras import modelsfrom keras import layersimpo


关于Reuters Corpora(路透社语料库)
首先在命令行窗口中进入python编辑环境,输入 >>import nltk>>nltk.download() 然后加载出: 在Corpora中所有的文件下载到C:\nltk_data中,大小在2.78G左右。 然后开始对其玩弄啦。 加载 from nltk.corpus import reutersfiles = reuters.fileids()#print(files)wo

深度学习多分类问题--路透社数据集
环境使用keras为前端,TensorFlow为后端 本次构建一个网络,将路透社新闻划分为46个类别。因为有多个类别,所以这是多分类问题。每个数据点只能划分到一个类别,所以,这是一个单标签,多分类问题。如果每个数据点可以划分到多个类别,那么就是多标签,多分类问题。 首先加载数据集 from keras.datasets import reuters#限定为前10000个最常出现的单词(t

27分钟,路透社用人工智能抢到了一条全球新闻
“网络的出现以及随之而来的信息爆炸,让记者准确迅速地报道新闻变得越来越具有挑战性。”全球新闻机构路透社的研发团队本周在arXiv上发表的一篇论文用了这样一句开场白。 对路透社而言,假新闻的出现让问题变得更加严重,这些假新闻扭曲了事件认知。 不过,像美联社等新闻机构已经开始采用自动化的新闻写作服务。这些报道使用了标准化的模式,例如财经新闻或者特定体育比赛结果,将数据填到预先写好的模板之中:“X

大数据时代,路透社如何玩转“原生数据”做新闻?
什么是数据新闻 数据新闻简单来讲就是利用真实有效的数据来发现、辅证和讲述新闻故事。举个最简单的例子,人的身体需要各种各样的营养,缺维生素B1可能导致消化不良,缺少维生素C导致抵抗力下降。事实上,我们的身体也可以理解为一个永不休息的数据新闻记者,搜集身体营养数据,向大脑报告发现的问题。当如此这般的“健康报告”不再是关乎一个人,而是一群人的时候,这就成了我们所说的数据新闻了。 如今,可视化数据已经成

路透社:大众与江淮计划在合肥投资50.6亿元建新电动汽车工厂
【TechWeb】4月26日消息,据路透社报道,德国汽车制造商大众汽车与江淮汽车的合资企业计划在合肥投资50.6亿元,建设一座新的电动汽车工厂。 周一,合肥经济技术开发区在网上发布的一份文件显示,大众汽车和江淮汽车已获得批准,建设一座年产10万辆全电动汽车的工厂。 该合资企业的一位发言人证实了建设该工厂的计划,并表示该批准意味着“该项目正有序推进”。这家合资企业的首款电动汽车E20X将于今年推

路透社:亚马逊有意收购预付费无线品牌Boost Mobile
【TechWeb】5月31日消息,据路透社报道,当地时间周四,两名知情人士表示,亚马逊有意从美国运营商T-Mobile US和Sprint手中收购预付费无线品牌Boost Mobile。 目前,Boost Mobile是Sprint旗下的预付费品牌之一。其中一名消息人士称,亚马逊正考虑收购Boost Mobile,主要是因为该交易将使其可以使用新T-Mobile的无线网络至少六年。新T-Mob