特征选择专题
【ML--05】第五课 如何做特征工程和特征选择
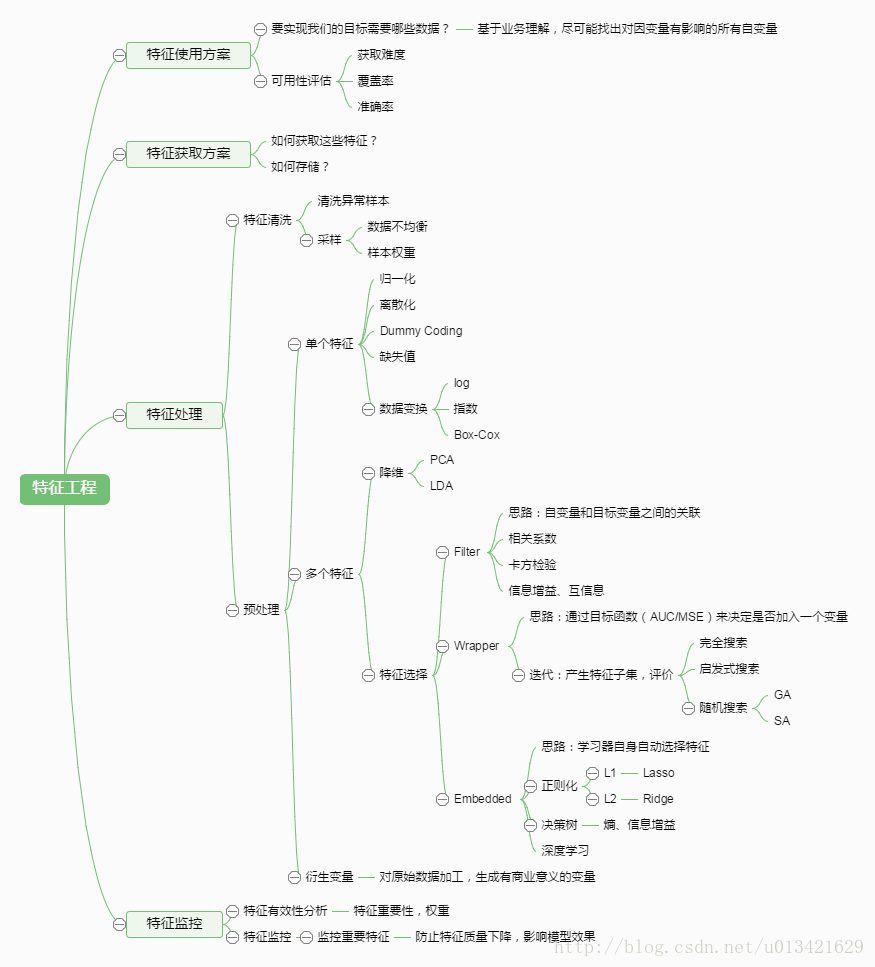
一、如何做特征工程? 1.排序特征:基于7W原始数据,对数值特征排序,得到1045维排序特征 2. 离散特征:将排序特征区间化(等值区间化、等量区间化),比如采用等量区间化为1-10,得到1045维离散特征 3. 计数特征:统计每一行中,离散特征1-10的个数,得到10维计数特征 4. 类别特征编码:将93维类别特征用one-hot编码 5. 交叉特征:特征之间两两融合,x+y、x-y、

结合sklearn说一下特征选择
特征选择(排序)对于数据科学家、机器学习从业者来说非常重要。好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点、底层结构,这对进一步改善模型、算法都有着重要作用。 特征选择主要有两个功能: 减少特征数量、降维,使模型泛化能力更强,减少过拟合增强对特征和特征值之间的理解 拿到数据集,一个特征选择方法,往往很难同时完成这两个目的。通常情况下,我们经常不管三七二十一,选择一种自己最熟悉或者


特征选择错误:The classifier does not expose coef_ or feature_importances_ attributes
在利用RFE进行特征筛选的时候出现问题,源代码如下: from sklearn.svm import SVRmodel_SVR = SVR(C=1.0, cache_size=200, coef0=0.0, degree=3, epsilon=0.1, gamma='auto',kernel='rbf', max_iter=-1, shrinking=True, tol=0.001, verb

智能优化特征选择|基于鲸鱼WOA优化算法实现的特征选择研究Matlab程序(XGBoost分类器)
智能优化特征选择|基于鲸鱼WOA优化算法实现的特征选择研究Matlab程序(XGBoost分类器) 文章目录 一、基本原理鲸鱼智能优化特征选择流程 二、实验结果三、核心代码四、代码获取五、总结 智能优化特征选择|基于鲸鱼WOA优化算法实现的特征选择研究Matlab程序(XGBoost分类器) 一、基本原理 当然,这里是鲸鱼智能优化算法(WOA)与XGBoost分类器结
基于SHAP进行特征选择和贡献度计算——可解释性机器学习
方法介绍 SHAP(SHapley Additive exPlanations)是一个 Python 包,旨在解释任何机器学习模型的输出。SHAP 的名称源自合作博弈论中的 Shapley 值,它构建了一个加性的解释模型,将所有特征视为“贡献者”。对于每个预测样本,模型会产生一个预测值,而 SHAP 值则表示该样本中每个特征的贡献度。 假设第i个样本为Xi,第i个样本的第j个特征为Xij,模型

机器学习第十一章--特征选择与稀疏学习
一、子集搜索与评价 我们将属性称为 “特征”(feature),对当前学习任务有用的属性称为 “相关特征”(relevant feature)、没什么用的属性称为 “无关特征”(irrelevant feature).从给定的特征集合中选择出相关特征子集的过程,称为“特征选择”(feature selection). 有两个很重要的原因:减轻维数灾难问题、降低学习任务的难度. “冗余特征”(

【机器学习】Lasso回归:稀疏建模与特征选择的艺术
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 Lasso回归:稀疏建模与特征选择的艺术引言一、Lasso回归简介1.1 基本概念1.2 数学表达式 二、算法与实现2.1 解决方案2.2 Python实现示例 三、Lasso回归的优势与特性3.1

一个可以进行机器学习特征选择的python工具
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Will Koehrsen 编译:ronghuaiyang 前戏 用这个工具可以高效的构建机器学习工作流程。一起来了解一下这个工具吧。 特征选择是在数据集中寻找和选择最有用的特征的过程,是机器学习pipeline中的一个关键步骤。不必要的特征降低了训练速度,降低了模型的可解释性,最重要的是,降低了测试集的泛化性能。 我发现自

基于麻雀搜索算法的同步优化特征选择 - 附代码
基于麻雀搜索算法的同步优化特征选择 - 附代码 文章目录 基于麻雀搜索算法的同步优化特征选择 - 附代码1.数据集2.SVM模型建立3.麻雀搜索算法同步优化特征选择4.测试结果5.参考文献:6.Matlab代码 摘要:针对传统支持向量机在封装式特征选择中分类效果差、子集选取冗余、计算性能易受核函数参数影响的不足, 利用麻雀优化算法对其进行同步优化。 1.数据集 wine
特征抽取、特征选择、特征工程
(更新于2019/03/02) 注意:关于这三个名词的概念,网上的一些内容并不是非常权威,当然也有人对这方面的内容做了比较详细的区分,所以看这部分内容的时候就需要仔细甄别,多看不同的内容。 1. 引言 在机器学习的流程中,如图1所示,这是一个完整的循环,针对一个特定的机器学习问题,这个循环应该是一直进行的,直到你对整个的模型性能满意的时候。 图1 机器学习流程[1] 因

AI学习指南机器学习篇-决策树的特征选择和分裂准则
AI学习指南机器学习篇-决策树的特征选择和分裂准则 1. 特征选择的方法 在机器学习中,特征选择是一项非常重要的任务,它直接影响到模型的性能和泛化能力。决策树是一种常用的机器学习算法之一,而特征选择则是决策树构建过程中的关键环节。常用的特征选择方法包括信息增益、基尼不纯度和增益率。 1.1 信息增益 信息增益是一种用于特征选择的常用方法,它是基于信息论的概念来衡量特征对分类任务的贡献程度。
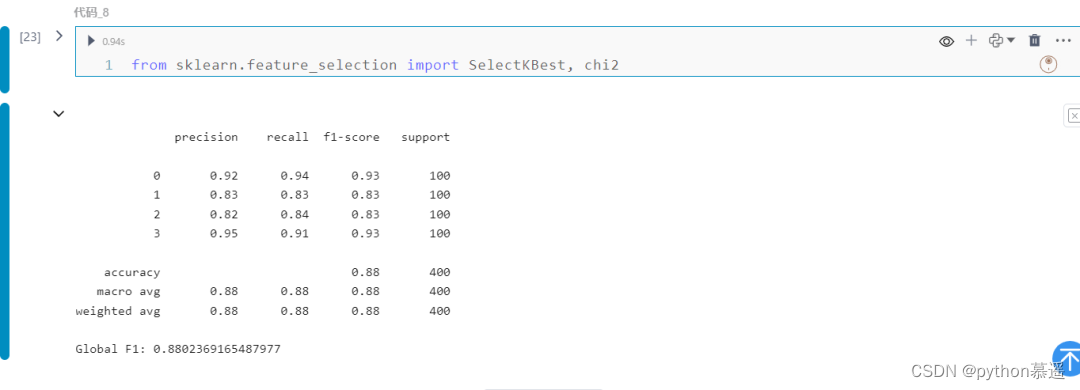
Python | 机器学习中的卡方检验及特征选择
卡方检验是分析分类数据关联性的重要统计方法。它的应用跨越各个领域,帮助研究人员了解因素之间的关系。 卡方检验 卡方检验是用于确定两个分类变量之间是否存在显著关联的统计检验。这是一个非参数检验,意味着它不对数据的分布做出任何假设。该测试基于列联表中观察到的频率和预期频率的比较。卡方检验通过查看元素之间的关系来帮助解决特征选择问题。它确定样本的两个分类变量之间的关联是否反映了它们在总体中的真实的关

【光谱特征选择】连续投影算法SPA(含python代码)
目录 一、背景 二、代码实现 三、项目代码 一、背景 连续投影算法(Successive Projection Algorithm,SPA)是一种用于光谱分离的简单且有效的算法。它主要应用于高光谱图像处理,用于提取混合光谱数据中的端元(endmembers)。端元是指在高光谱图像中存在的纯物质的光谱签名,这些签名在混合像元的光谱数据中有重要的影响。 SPA的基本原理是通过迭代过
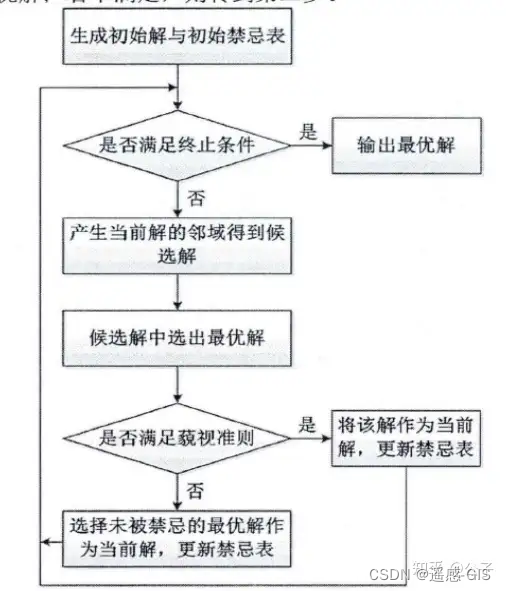
遥感之特征选择-禁忌搜索算法
各类智能优化算法其主要区别在于算法的运行规则不同,比如常用的遗传算法,其规则就是变异,交叉和选择等,各种不同的变体大多是在框架内的实现细节不同,而本文中的禁忌算法也是如此,其算法框架如下进行介绍。 智能优化算法和其他算法的最大不同在于,其没有太高深的数学理论和公式,主要是基于一种设定规则运行,其规则的设置背后有优美的哲学味道,所以它能有效解决一些问题,而同时不少人对比表示怀疑的态度,只有当真正的跑
机器学习中经常使用的特征选择方式+python实现代码
当数据与处理完成后,我们需要选择有意义的特征输入算法和模型进行训练,通常来说,从两个方面来选择特征: 1、特征是否发散,如果某一个特征的方差为0,即这个属性不能被称之为特征,因为所有的样本在这个特征上并没有什么区别,这种特种需要被剔除;但是如果相反,所有样本在在这个特征上都不一样,比如公民的身份证号码,不能反映出样本的共性的特征的话,特征也必须被剔除。 2、特征与目标之间的相关性,如果特征与
条件熵,信息增益(互信息)与特征选择
一定要先搞清楚什么是信息量,什么是信息熵。参考博文:https://blog.csdn.net/u010916338/article/details/91127242 一,什么是信息量? 简言之,就是把信源看做是一个随机变量。消息(信号)就是随机变量的取值,比如a1,a2···an。信息就是这些随机变量的不确程度(发生概率越低,不确定性越大),公式如下。为什么写成这样呢?原因有二。第一:概率和

Python 机器学习 基础 之 数据表示与特征工程 【单变量非线性变换 / 自动化特征选择/利用专家知识】的简单说明
Python 机器学习 基础 之 数据表示与特征工程 【单变量非线性变换 / 自动化特征选择/利用专家知识】的简单说明 目录 Python 机器学习 基础 之 数据表示与特征工程 【单变量非线性变换 / 自动化特征选择/利用专家知识】的简单说明 一、简单介绍 二、单变量非线性变换 三、自动化特征选择 1、单变量统计 2、基于模型的特征选择 3、迭代特征选择 四、利用专家知识
数据科学:使用Optuna进行特征选择
大家好,特征选择是机器学习流程中的关键步骤,在实践中通常有大量的变量可用作模型的预测变量,但其中只有少数与目标相关。特征选择包括找到这些特征的子集,主要用于改善泛化能力、助力推断预测、提高训练效率。有许多技术可用于执行特征选择,每种技术的复杂性不同。 本文将介绍一种使用强大的开源优化工具Optuna来执行特征选择任务的创新方法,主要思想是通过有效地测试不同的特征组合(例如,不是逐个尝试它们)来处

1.基于python的单细胞数据预处理-特征选择
文章目录 特征选择背景基于基因离散度基于基因归一化方差基于基因皮尔森近似残差特征选择总结 参考: [1] https://github.com/Starlitnightly/single_cell_tutorial [2] https://github.com/theislab/single-cell-best-practices 特征选择背景 现在已经获得了经过归一化的测序数

RFID标签识别中的特征选择
#引用 ##LaTex @INPROCEEDINGS{6417479, author={D. Banerjee and Jiang Li and Jia Di and D. R. Thompson}, booktitle={7th International Conference on Communications and Networking in China}, title={Featur

华法林剂量预测的多目标特征选择
#引用 ##LaTex @article{SOHRABI2017126, title = “Multi-objective feature selection for warfarin dose prediction”, journal = “Computational Biology and Chemistry”, volume = “69”, pages = “126 - 133”, ye
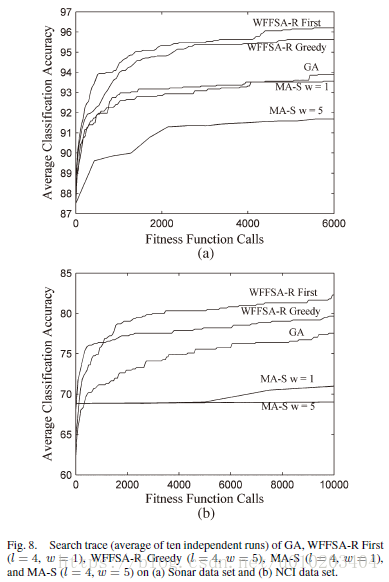
基于模因框架的包装过滤特征选择算法
#引用 ##LaTex @ARTICLE{4067093, author={Z. Zhu and Y. S. Ong and M. Dash}, journal={IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics)}, title={Wrapper ndash;Filter Feature Selec
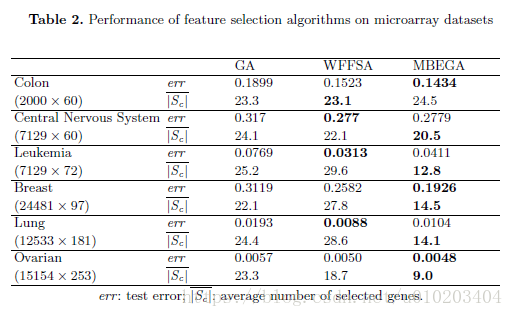
微阵列数据特征选择的模因算法
#引用 ##LaTex @inproceedings{Zhu:2007:MAF:1418707.1418870, author = {Zhu, Zexuan and Ong, Yew-Soon}, title = {Memetic Algorithms for Feature Selection on Microarray Data}, booktitle = {Proceedings of

一种可扩展的同时进化实例和特征选择方法
#引用 ##Latex @article{GARCIAPEDRAJAS2013150, title = “A scalable approach to simultaneous evolutionary instance and feature selection”, journal = “Information Sciences”, volume = “228”, pages = “150
模型选择和特征选择经验总结
模型以及特征选择 机器学习的关键部分无外乎是模型以及特征选择 模型选择 常见的分类模型有:SVM,LR,Navie Bayesian,CART以及由CART演化而来的树类模型,Random Forest,GBDT,最近详细研究了GBDT,RF发现它的拟合能力近乎完美,而且在调整了参数之后可以降低过拟合的影响,据说高斯过程的拟合能力也比不过它,这次就决定直接采用GBDT来做主模型