本文主要是介绍基于SHAP进行特征选择和贡献度计算——可解释性机器学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
方法介绍
SHAP(SHapley Additive exPlanations)是一个 Python 包,旨在解释任何机器学习模型的输出。SHAP 的名称源自合作博弈论中的 Shapley 值,它构建了一个加性的解释模型,将所有特征视为“贡献者”。对于每个预测样本,模型会产生一个预测值,而 SHAP 值则表示该样本中每个特征的贡献度。
假设第i个样本为Xi,第i个样本的第j个特征为Xij,模型对该样本的预测值为yi,整个模型的基线(通常是所有样本的目标变量的均值)为 ybase,那么 SHAP 值服从以下等式:
yi=ybase+f(Xi1)+f(Xi2)+⋯+f(Xik)
其中 f(Xij)表示第i个样本中第j个特征的 SHAP 值。从直观上看,f(Xi1)表示第i个样本中第1个特征对最终预测值yi的贡献。当f(Xj1)>0时,说明该特征提升了预测值,有正向作用;反之,则说明该特征降低了预测值,有反向作用。
解释器Explainer
在SHAP中进行模型解释需要先创建一个explainer,SHAP支持很多类型的explainer(例如deep、gradient、kernel、tree、sampling等),以tree为例,它支持常用的XGB、LGB、CatBoost等树集成算法。
explainer = shap.TreeExplainer(model) # #这里的model在准备工作中已经完成建模,模型名称就是modelshap_values = explainer.shap_values(X) # 传入特征矩阵X,计算SHAP值
上面的shap_values对象是一个包含两个array的list。第一个array是负向结果的SHAP值,而第二个array是正向结果的SHAP值。通常从预测正向结果的角度考虑模型的预测结果,所以会拿出正向结果的SHAP值(拿出shap_values[1])。
局部可解释性Local Interper,Local可解释性提供了预测的细节,侧重于解释单个预测是如何生成的。它可以帮助决策者信任模型,并且解释各个特征是如何影响模型单次的决策。
使用例子
import xgboost as xgb
from sklearn.model_selection import train_test_split
import shap
import pandas as pddata = pd.read_csv('example.csv')
X = data[['A', 'B', 'C', 'D', 'E']]
Y = data['F']
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, shuffle=False)
xgb_model = xgb.XGBRegressor(random_state=42)
xgb_model.fit(X_train, Y_train)
explainer = shap.Explainer(xgb_model)
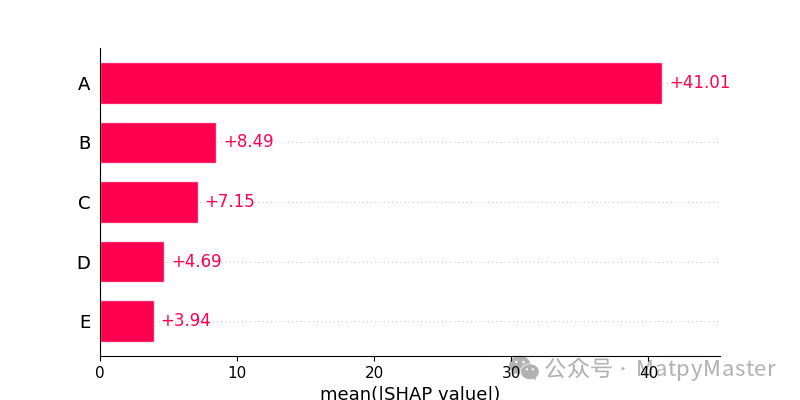
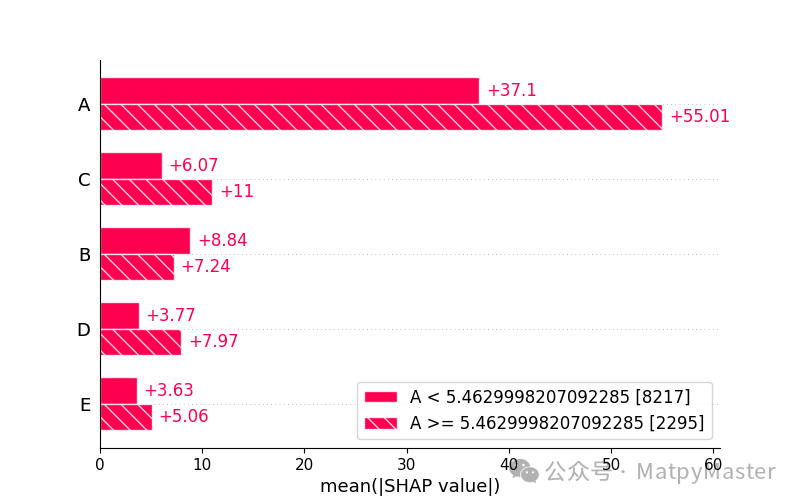
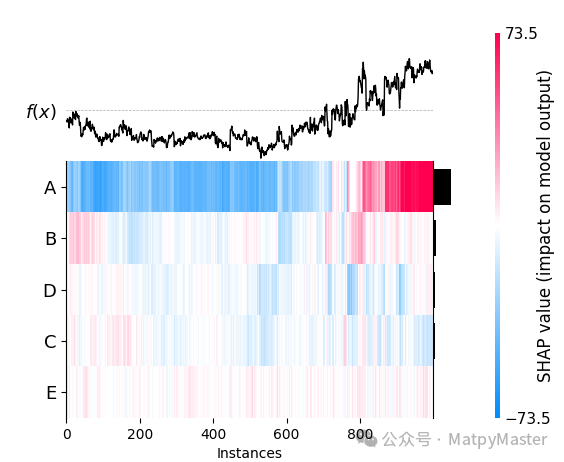
shap_values = explainer(X_test)shap.summary_plot(shap_values) #提琴图shap.plots.bar(shap_values) # Bar Plotshap.plots.bar(shap_values.cohorts(2).abs.mean(0)) # 队列图shap.plots.heatmap(shap_values[1:1000]) # 热图shap.plots.waterfall(shap_values[0]) # 瀑布图shap.initjs()
explainer = shap.TreeExplainer(xgb_model)
shap_values = explainer.shap_values(X_test)
def p(j):return(shap.force_plot(explainer.expected_value, shap_values[j,:], X_test.iloc[j,:]))
p(0)shap_values = explainer.shap_values(X_test)[1]
shap.decision_plot(explainer.expected_value, shap_values, X_test)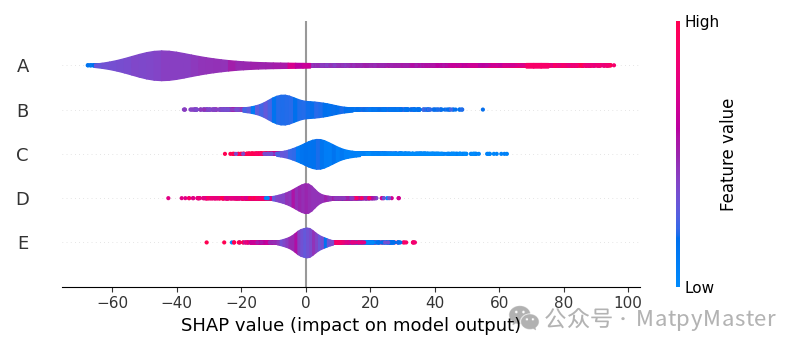
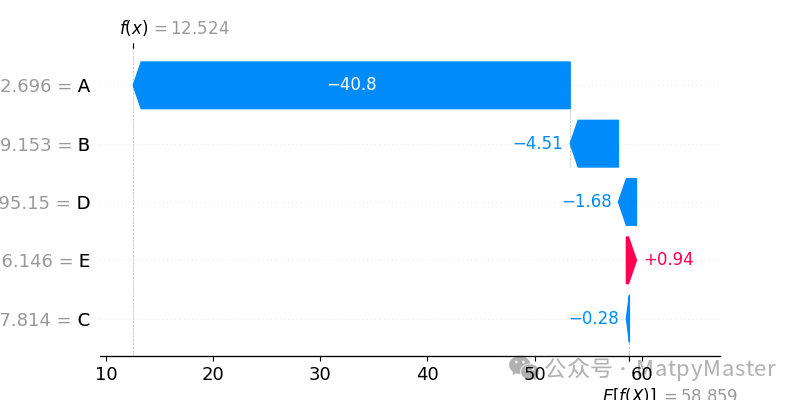
最后:
小编会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!
这篇关于基于SHAP进行特征选择和贡献度计算——可解释性机器学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






