shap专题

数据分析:R语言计算XGBoost线性回归模型的SHAP值
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍SHAP用途计算方法:应用 加载R包导入数据数据预处理函数模型 介绍 SHAP(SHapley Additive exPlanations)值是一种解释机器学习模型预测的方法。它基于博弈论中的Shapley值概念,用于解释任何机器学习模型的输出。 SHAP用途 解释性:机器学习模型
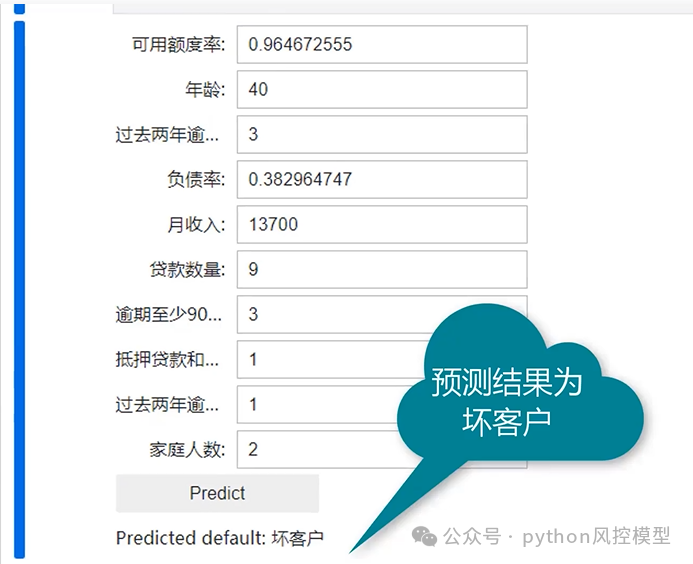
专利复现_基于ngboost和SHAP值可解释预测方法
大家好,我是重庆未来之智的Toby老师,最近看到一篇专利,名称是《基于NGBoost和SHAP值的可解释地震动参数概率密度分布预测方法》。该专利申请工日是2021年3月2日。 专利复现 我看了这专利申请文案后,文章整体布局和文字内容结构不错,就是创新点半天找不到。我们公司之前申请专利至少还有算法创新点,不由
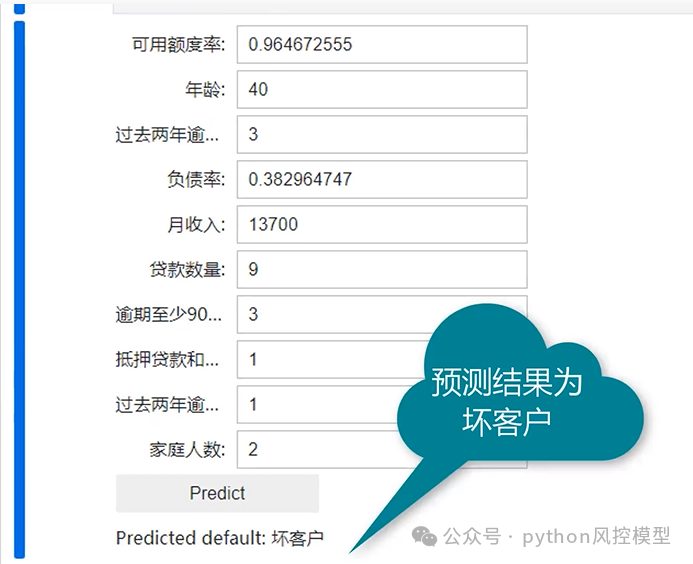
算法专利复现_基于ngboost和SHAP值可解释预测方法
大家好,我是重庆未来之智的Toby老师,最近看到一篇专利,名称是《基于NGBoost和SHAP值的可解释地震动参数概率密度分布预测方法》。该专利申请工日是2021年3月2日。 专利复现 我看了这专利申请文案后,文章整体布局和文字内容结构不错,就是创新点半天找不到。我们公司之前申请专利至少还有算法创新点,不由感叹
基于SHAP进行特征选择和贡献度计算——可解释性机器学习
方法介绍 SHAP(SHapley Additive exPlanations)是一个 Python 包,旨在解释任何机器学习模型的输出。SHAP 的名称源自合作博弈论中的 Shapley 值,它构建了一个加性的解释模型,将所有特征视为“贡献者”。对于每个预测样本,模型会产生一个预测值,而 SHAP 值则表示该样本中每个特征的贡献度。 假设第i个样本为Xi,第i个样本的第j个特征为Xij,模型

Parallelize your massive SHAP computations with MLlib and PySpark
https://medium.com/towards-data-science/parallelize-your-massive-shap-computations-with-mllib-and-pyspark-b00accc8667c (能翻墙直接看原文) A stepwise guide for efficiently explaining your models using SHAP.
Explain Python Machine Learning Models with SHAP Library
Explain Python Machine Learning Models with SHAP Library – Minimatech (能翻墙直接看原文) Explain Python Machine Learning Models with SHAP Library 11 September 2021Muhammad FawiMachine Learning Using S

【Python】探索 SHAP 特征贡献度:解释机器学习模型的利器
缘分让我们相遇乱世以外 命运却要我们危难中相爱 也许未来遥远在光年之外 我愿守候未知里为你等待 我没想到为了你我能疯狂到 山崩海啸没有你根本不想逃 我的大脑为了你已经疯狂到 脉搏心跳没有你根本不重要 🎵 邓紫棋《光年之外》 什么是 SHAP? SHAP,全称为 SHapley Additive exPlanations,是一种解释机器学习模型

Android 布局自定义Shap圆形ImageView,可以单独设置背景与图片
时间 2015-01-09 11:05:02 ITeye-博客 原文 http://kt-g.iteye.com/blog/2174304 主题 安卓开发 一、图片预览: 一、实现功能: 需求要实现布局中为圆形图片,图片背景与图标分开且合并到一个ImageView。 二、具体实现: XML中布局中定义ImageView,关健设置两个参数

SHAP,一个解释机器学习模型Python库
SHAP库概述 SHAP(SHapley Additive exPlanations)是一个Python库,用于解释任何机器学习模型的预测.它基于博弈论中的Shapley值概念,可以帮助用户理解模型预测中各个特征的贡献度. 安装与使用 # 命令安装SHAP库:pip install shap 使用SHAP库的基本步骤如下: 创建一个解释器来解释模型. 解释模型的预测结果并可
SHAP分析交互作用的功能,如果你用的模型是xgboost
SHAP分析交互作用的功能,如果你用的模型是xgboost 如果在SHAP分析中使用的是xgoost模型,就可以使用SHAP分析内置的交互作用分析,为分析变量间的相互提供了另外一个观察的视角。关于SHAP交互作用分析,一个参考资料,还是很值得看看。 SHAP分析内置的交互作用可视化(汇总图)。是使用R语言shapviz包实现。前提是用的模型是xgboost,还要在获得shap对象的时候将参数“
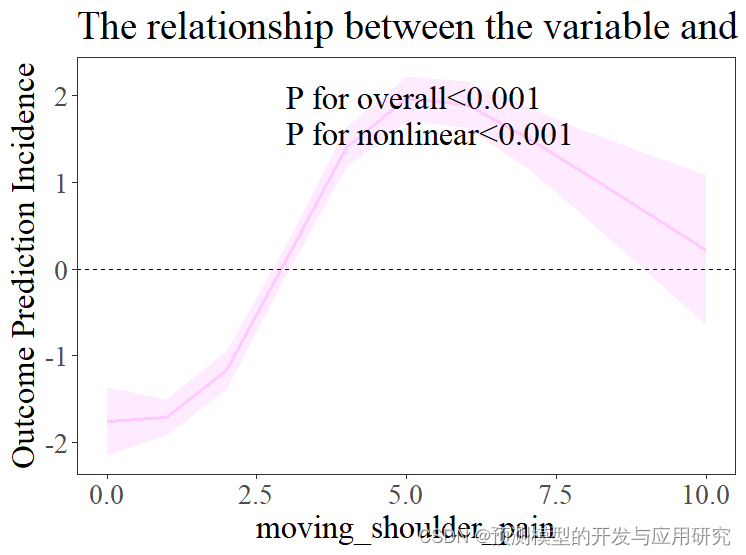
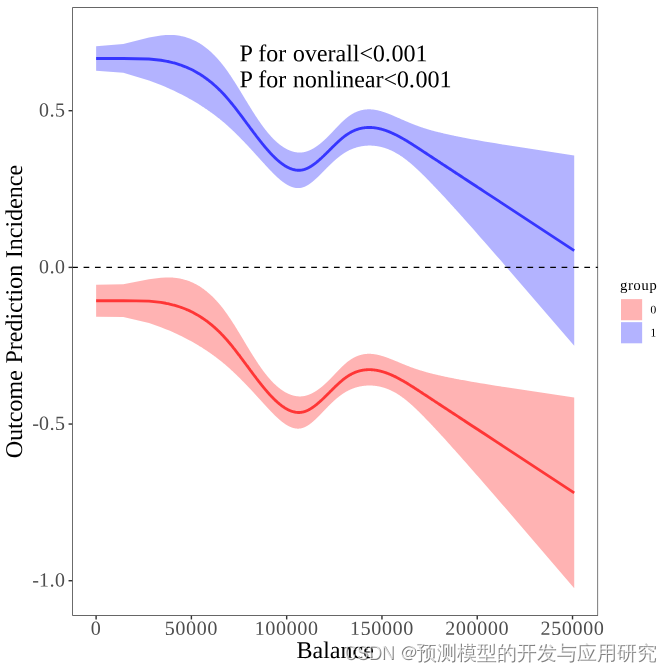
用立方样条来拟合SHAP分析的结果
用立方样条来拟合SHAP分析的结果 1. SHAP分析告诉我们变量之间的关系 SHAP分析计算的SHAP值代表了某变量对于结局指标的贡献,代表了相关性的趋势,SHAP分析中的散点图是对以上关系的可视化,从中我们可以直观看到随着变量值的变化,其对结局指标的贡献。如下图,从中可以看到变量之间的关系不是直线关系,但是,如何描述这种关系就是一个问题,比如,曲线的拐点在哪里?等等。因为这变量之间的关系往
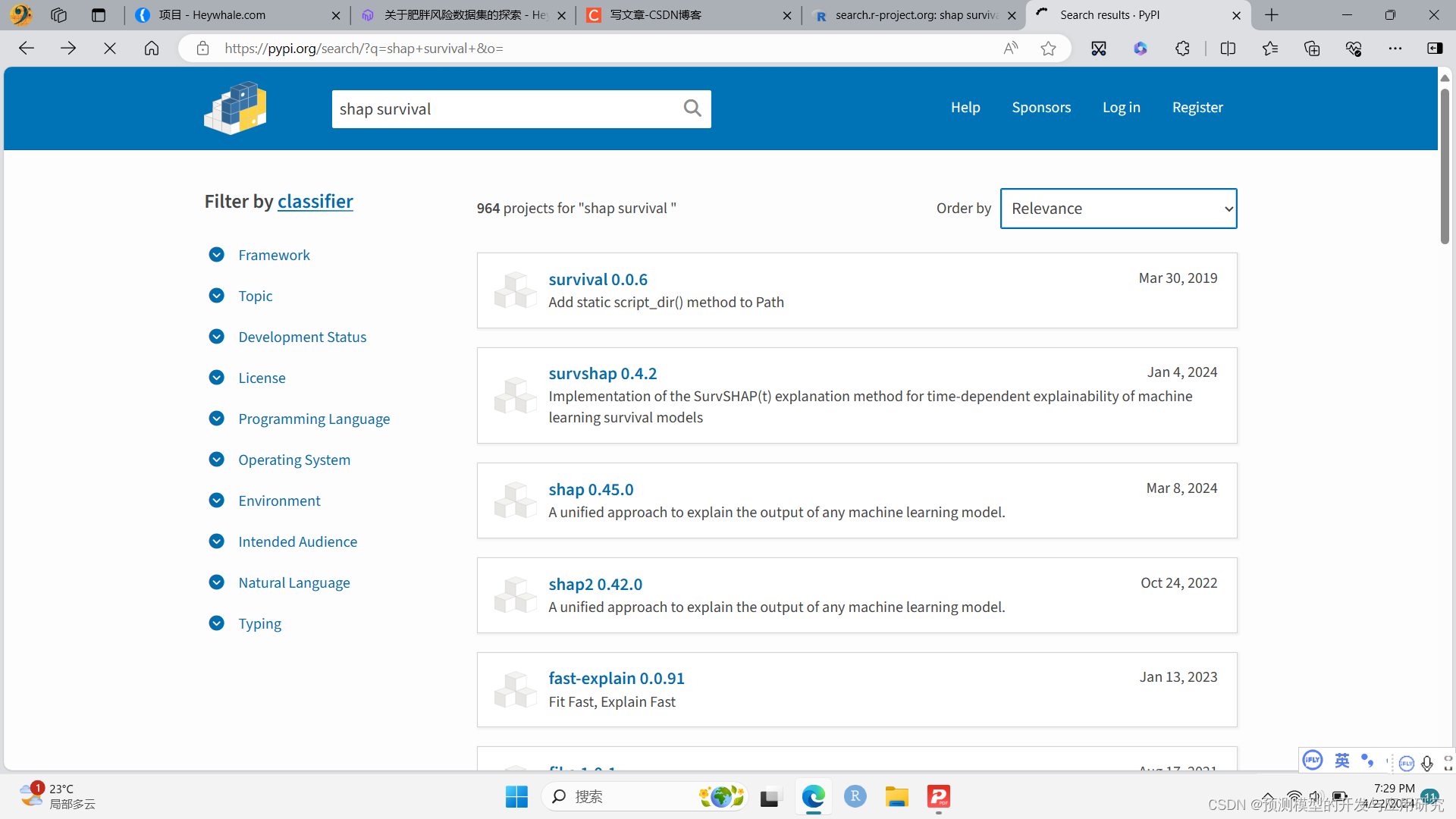
快速找到可以用的R包或python包(比如可以对Cox数据进行shap分析的包)
快速找到可以用的R包或python包(比如可以对Cox数据进行shap分析的包) 这里介绍一种方法,当然去搜索引擎找,也是一种方法,有时候还可以找到不一样的结果。 1. 寻找R包 第一步:百度CRAN网站,点击左边栏的“search”,获得如下界面。 第二步:点击主界面中的“search.r-project.org”,获得如下界面。 第三步:按照图中取消掉大部分的选择,只保留对“De

Boruta 和 SHAP :不同特征选择技术之间的比较以及如何选择
来源:DeepHub IMBA本文约1800字,建议阅读5分钟 在这篇文章中,我们演示了正确执行特征选择的实用程序。 当我们执行一项监督任务时,我们面临的问题是在我们的机器学习管道中加入适当的特征选择。只需在网上搜索,我们就可以访问讨论特征选择过程的各种来源和内容。 总而言之,有不同的方法来进行特征选择。文献中最著名的是基于过滤器和基于包装器的技术。在基于过滤器的过程中,无监督算法或统计数据

【机器学习】如何计算解释模型的SHAP值
文章目录 近似算法计算步骤计算举例参考资料 SHAP值是一种用于解释机器学习模型的工具,可以帮助我们理解每个特征值对模型预测结果的贡献程度。具体地,我们应该如何计算单个特征的SHAP值呢?以下介绍一种近似计算方法。 近似算法 单个特征值的shap值近似估计算法: 输出:第j个特征值的shap值输入:迭代次数 M M M、待计算的实例 x x x、特征索引 j j j、数据

SHAP和LIME:Python机器学习模型解释
SHAP和LIME:Python机器学习模型解释 为了更好地展示,示例代码参见和鲸社区,一键运行 简介 机器学习模型在各个领域得到广泛应用,但其黑盒性质往往使人难以理解其决策过程,降低了模型的可信度和可靠性。为了解决这一问题,可解释性人工智能(XAI)应运而生,其目标是为模型的行为和决策提供清晰、可理解的解释。 一、SHAP SHAP(SHapley Additive Explanati
android中Style,Selected,Shap等使用
1、Style是针对窗体元素级别的,改变指定控件或者Layout的样式。 一般我们可以自定义我们的style,在目录res/value下定义xxxx.xml.例如如下: <?xml version="1.0" encoding="UTF-8"?> <resources> <style name="text1"> <item name="android:textC

Catboost算法助力乳腺癌预测:Shap值解析关键预测因素
一、引言 乳腺癌是一种常见的恶性肿瘤,对女性健康和生命造成严重威胁。乳腺癌的预测和治疗是当前研究的热点和难点。传统的预测方法主要基于临床病理学特征,但准确率有待提高。随着机器学习技术的发展,数据驱动的预测方法逐渐受到关注。Catboost算法是一种高效的深度学习模型,能够处理类别型特征,具有较高的预测精度。Shap值是一种解释模型预测结果的方法,能够解释模型中各个特征对预测结果的贡献程度。本文将
随机森林回归模型,SHAP库可视化
随机森林回归模型 创建一个随机森林回归模型,训练模型,然后使用SHAP库解释模型的预测结果,并将结果可视化。 具体步骤如下: 首先,代码导入了所需的库,包括matplotlib、shap、numpy和sklearn.ensemble。matplotlib库用于数据可视化,shap库用于解释机器学习模型的预测结果,numpy库用于进行数值计算和数组操作,sklearn.ensemble库中的
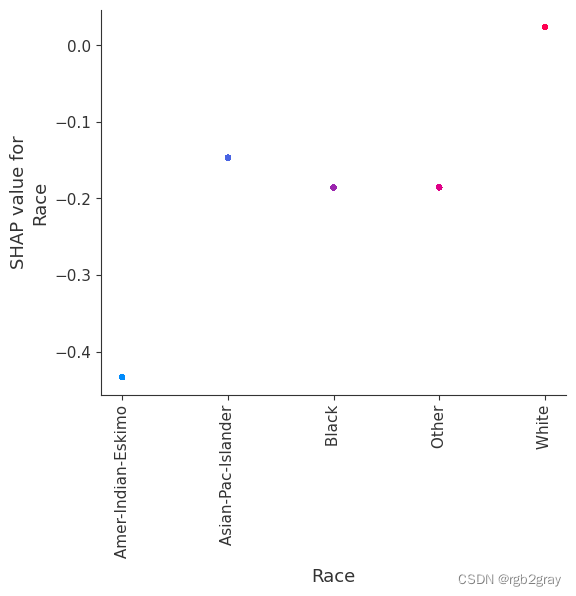
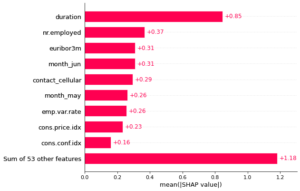
SHAP(五):使用 XGBoost 进行人口普查收入分类
SHAP(五):使用 XGBoost 进行人口普查收入分类 本笔记本演示了如何使用 XGBoost 预测个人年收入超过 5 万美元的概率。 它使用标准 UCI 成人收入数据集。 要下载此笔记本的副本,请访问 github。 XGBoost 等梯度增强机方法对于具有多种形式的表格样式输入数据的此类预测问题来说是最先进的。 Tree SHAP(arXiv 论文)允许精确计算树集成方法的 SHAP
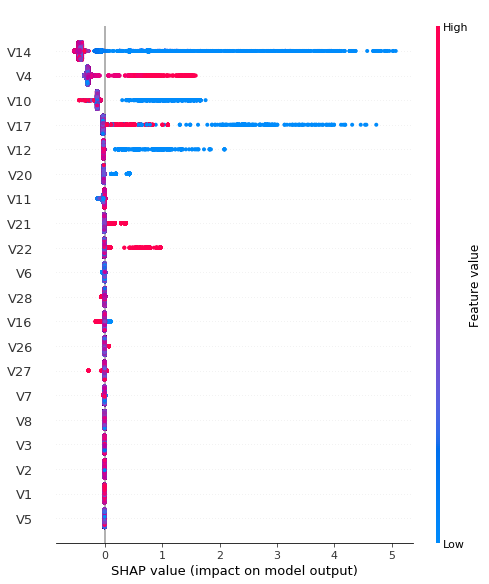
SHAP(六):使用 XGBoost 和 HyperOpt 进行信用卡欺诈检测
SHAP(六):使用 XGBoost 和 HyperOpt 进行信用卡欺诈检测 本笔记本介绍了 XGBoost Classifier 在金融行业中的实现,特别是在信用卡欺诈检测方面。 构建 XGBoost 分类器后,它将使用 HyperOpt 库(sklearn 的 GridSearchCV 和 RandomziedSearchCV 算法的替代方案)来调整各种模型参数,目标是实现正常交易和欺诈交

SHAP(四):NHANES I 生存模型
SHAP(四):NHANES I 生存模型 这是一个 Cox 比例风险模型,基于来自 NHANES I 的数据以及来自 NHANES I 流行病学随访研究。 它旨在说明 SHAP 值如何能够以传统上仅由线性模型提供的清晰度解释 XGBoost 模型。 我们在数据中看到有趣的非线性模式,这表明了这种方法的潜力。 请记住,我们尚未对数据进行检查以校准当前的实验室测试,因此您不应将结果视为可操作的医学
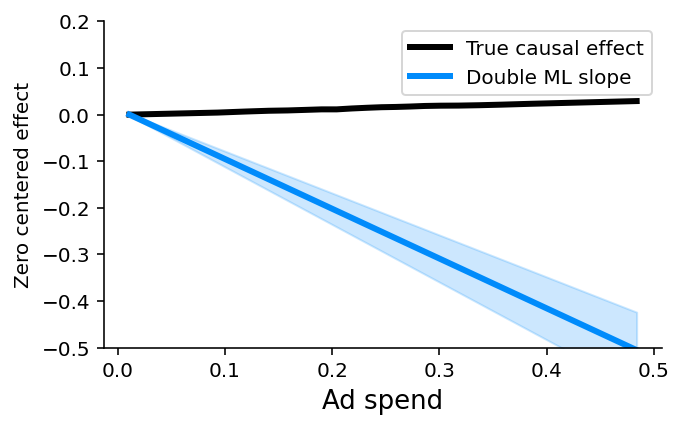
SHAP(三):在解释预测模型以寻求因果见解时要小心
SHAP(三):在解释预测模型以寻求因果见解时要小心 与 Microsoft 的 Eleanor Dillon、Jacob LaRiviere、Scott Lundberg、Jonathan Roth 和 Vasilis Syrgkanis 合作撰写的关于因果关系和可解释机器学习的文章。 当与 SHAP 等可解释性工具配合使用时,XGBoost 等预测机器学习模型会变得更加强大。 这些工具确定
SHAP 和 LIME 解释模型
内容大纲 1、SHAP 解释器1.1 案例:用于预测患者肺癌1.2 案例中使用的shap解释器1.3 举例说明:SHAP工作原理 2、LIME 解释器2.1 案例:判断法律案件胜诉可能性2.2 LIME解释器工作原理2.3 本地解释模型的训练过程2.4 举例说明1:新闻分类2.4 举例说明2:电影评论判断 1、SHAP 解释器 1.1 案例:用于预测患者肺癌 该案例使用肺癌数
SHAP算法在营销增益模型中的尝试
SHAP算法 Shap算法,全称SHapley Additive exPlanations,即沙普利加和解释。它的核心思想是将输出值归因到每一个特征的shapley值上,以此来量化衡量特征对最终输出值的影响。这个算法是由华盛顿大学的研究者开发并开源的,因此被命名为SHAP。 作为Python开发的"模型解释"包,SHAP可以解释任何机器学习模型的输出。其理论基础来源于合作博弈论,构建了一个加性

【机器学习可解释性】5.SHAP值的高级使用
机器学习可解释性 1.模型洞察的价值2.特征重要性排列3.部分依赖图4.SHAP 值5.SHAP值的高级使用 正文 汇总SHAP值以获得更详细的模型解释 总体回顾 我们从学习排列重要性和部分依赖图开始,以显示学习后的模型的内容。 然后我们学习了SHAP值来分解单个预测的组成部分。 现在我们将对SHAP值展开讨论,看看聚合许多SHAP值如何为排列重要性图和部分依赖图提供更详细的替代方
【机器学习可解释性】5.SHAP值的高级使用
机器学习可解释性 1.模型洞察的价值2.特征重要性排列3.部分依赖图4.SHAP 值5.SHAP值的高级使用 正文 汇总SHAP值以获得更详细的模型解释 总体回顾 我们从学习排列重要性和部分依赖图开始,以显示学习后的模型的内容。 然后我们学习了SHAP值来分解单个预测的组成部分。 现在我们将对SHAP值展开讨论,看看聚合许多SHAP值如何为排列重要性图和部分依赖图提供更详细的替代方