本文主要是介绍一个可以进行机器学习特征选择的python工具,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
前戏作者:Will Koehrsen
编译:ronghuaiyang
用这个工具可以高效的构建机器学习工作流程。一起来了解一下这个工具吧。
特征选择是在数据集中寻找和选择最有用的特征的过程,是机器学习pipeline中的一个关键步骤。不必要的特征降低了训练速度,降低了模型的可解释性,最重要的是,降低了测试集的泛化性能。
我发现自己一遍又一遍地为机器学习问题应用特别的特征选择方法,这让我感到沮丧,于是我在Python中构建了一个特征选择类可在GitHub上找到。 FeatureSelector包括一些最常见的特征选择方法:
缺失值百分比高的特征
共线性(高相关性)的特征
在基于树的模型中零重要性的特征
低重要性的特征
具有单一唯一值的特征
在本文中,我们将在一个样例机器学习数据集上使用 FeatureSelector。我们将看到它如何允许我们快速实现这些方法,从而实现更有效的工作流。
完整的代码可在GitHub上获得,我鼓励任何贡献。 Feature Selector正在开发中,并将根据社区的需要不断改进!
样例数据集
在本例中,我们将使用Kaggle上的Home Credit Default Risk machine learning competition数据。(要开始竞赛,请参见本文)。整个数据集可下载,这里我们将使用一个例子来演示。

这个比赛是一个监督分类问题,这是一个很好的数据集,因为它有许多缺失的值,许多高度相关(共线)的特征,和一些不相关的特征,这对机器学习模型没有帮助。
创建实例
要创建 FeatureSelector类的实例,我们需要传入一个结构化数据集,其中包含行和列中的特征。我们可以使用一些只有特征的方法,但是基于重要性的方法也需要训练标签。由于我们有一个监督分类任务,我们将使用一组特征和一组标签。
(确保在与feature_selector.py相同的目录中运行这个脚本)
from feature_selector import FeatureSelector
# Features are in train and labels are in train_labels
fs = FeatureSelector(data = train, labels = train_labels)方法
特征选择器有五种方法来查找要删除的特征。我们可以访问任何已识别的特征并手动从数据中删除它们,或者使用特征选择器中的“remove”函数。
在这里,我们将详细介绍每种识别方法,并展示如何同时运行所有5种方法。 FeatureSelector还具有一些绘图功能,因为可视化检查数据是机器学习的关键组件。
缺失值
查找要删除的特征的第一种方法很简单:看看哪些特征的缺失值的比例大于某个阈值。下面的调用标识了缺失值超过60%的特征。
fs.identify_missing(missing_threshold = 0.6)
17 features with greater than 0.60 missing values.我们可以看到dataframe中每一列缺失值的比例:
fs.missing_stats.head()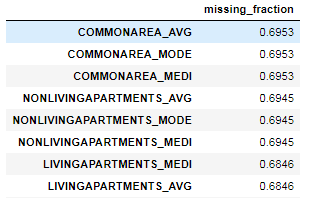
要查看要删除的特征,我们访问 FeatureSelector的 ops属性,这是一个Python字典,值为特征列表。
missing_features = fs.ops['missing']
missing_features[:5]
['OWN_CAR_AGE', 'YEARS_BUILD_AVG', 'COMMONAREA_AVG', 'FLOORSMIN_AVG', 'LIVINGAPARTMENTS_AVG']最后,我们绘制了所有特征缺失值的分布图:
fs.plot_missing()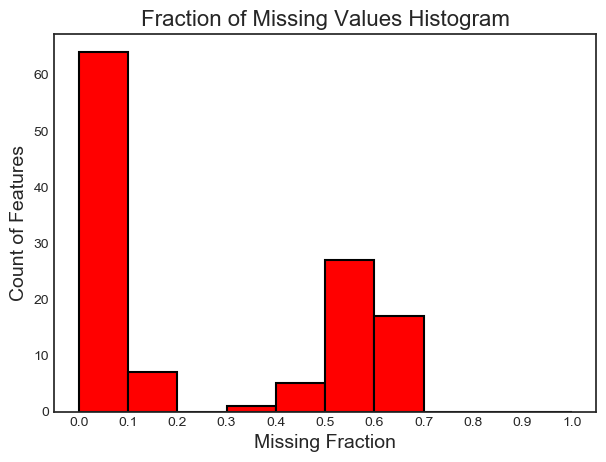
共线性的特征
共线性特征是彼此高度相关的特征。在机器学习中,由于方差大、模型可解释性差,导致测试集泛化性能下降。
方法 identify_collinear根据指定的相关系数值查找共线特征。对于每一对相关的特征,它识别出要删除的特征之一(因为我们只需要删除一个):
fs.identify_collinear(correlation_threshold = 0.98)
21 features with a correlation magnitude greater than 0.98.我们可以用关联做出一个清晰的可视化,那就是热图。这显示了在阈值以上至少有一个相关性特征的所有特征:
fs.plot_collinear()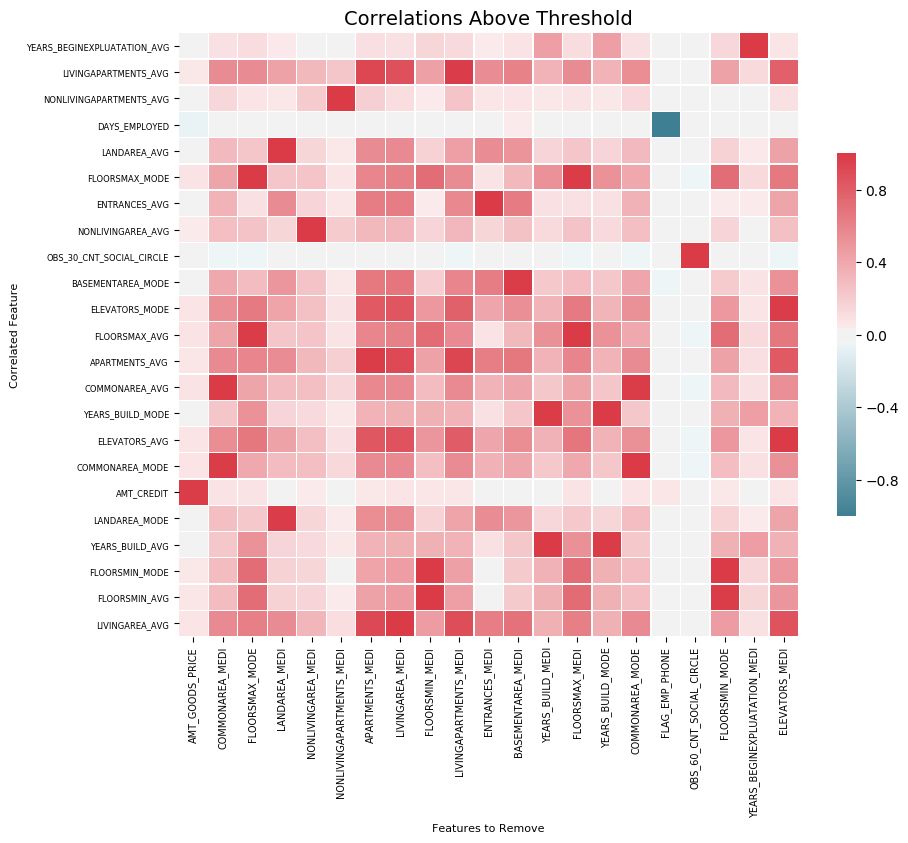
如前所述,我们可以访问将要删除的相关特征的整个列表,或者查看dataframe中高度相关的特征对。
# list of collinear features to remove
collinear_features = fs.ops['collinear']
# dataframe of collinear features
fs.record_collinear.head()
如果我们想要研究我们的数据集,我们还可以通过将 plot_all=True传递给调用来绘制数据中所有关联的图表:
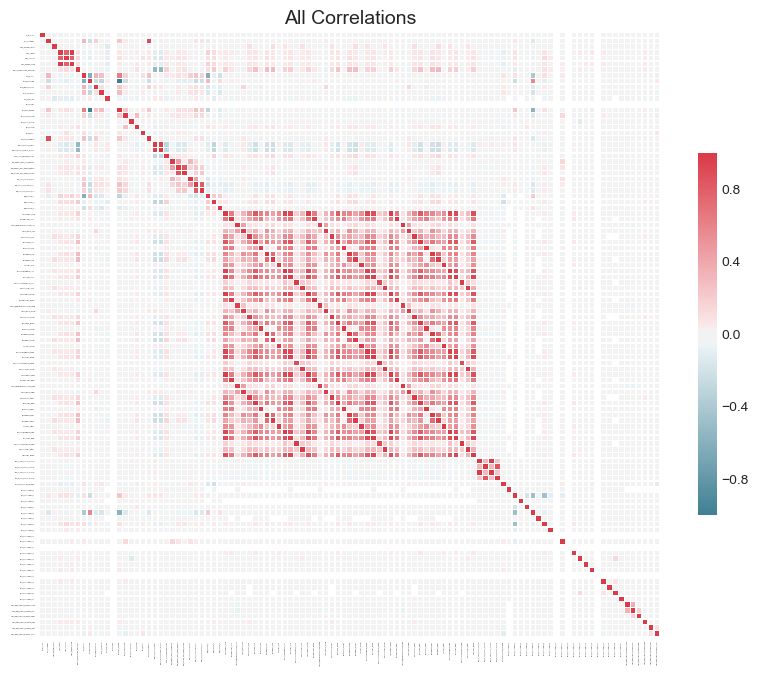
零重要性特征
前两种方法可以应用于任何结构化数据集,并且是确定性的——对于给定的阈值,每次结果都是相同的。下一种方法只适用于有监督的机器学习问题,在这种问题中,我们有训练模型的标签,并且是不确定的。 identify_zero_importance函数根据梯度提升机(GBM)学习模型查找不重要的特征。
使用基于树的机器学习模型,例如增强集成,我们可以找到特征重要性。重要性的绝对值没有相对值重要,相对值可以用来确定任务的最相关的特征。我们还可以通过删除零重要性的特征来进行特征选择。在基于树的模型中,不使用零重要性的特征来分割任何节点,因此我们可以在不影响模型性能的情况下删除它们。
FeatureSelector使用LightGBM库中的梯度提升机查找特征重要性。为了减少方差,将GBM的10次训练的特征重要性计算平均值。此外,使用带有验证集的early stop(可以选择关闭验证集)对模型进行训练,以防止对训练数据的过拟合。
下面的代码调用该方法,提取零重要性特征:
# Pass in the appropriate parameters
fs.identify_zero_importance(task = 'classification', eval_metric = 'auc', n_iterations = 10, early_stopping = True)
# list of zero importance features
zero_importance_features = fs.ops['zero_importance']
63 features with zero importance after one-hot encoding.我们传入的参数如下:
任务:对应问题的“分类”或“回归”
eval_metric:用于早期停止的指标(如果禁用了早期停止,则没有必要使用该指标)
n_iteration:训练次数,用来对特征重要性取平均
early ly_stop:是否使用early stop来训练模型
这次我们得到了两个带有 plot_feature_importances的图:
# plot the feature importances
fs.plot_feature_importances(threshold = 0.99, plot_n = 12)
124 features required for 0.99 of cumulative importance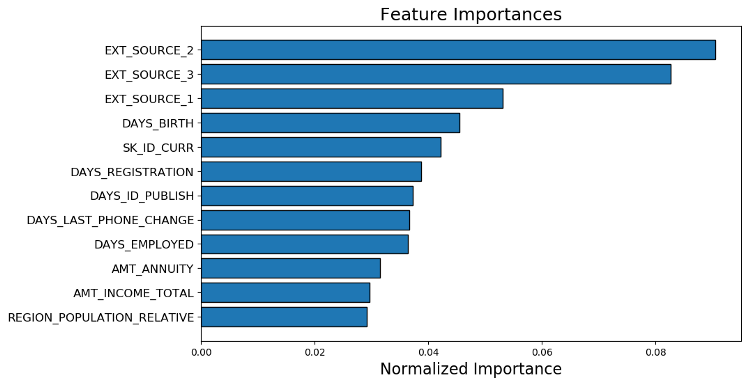
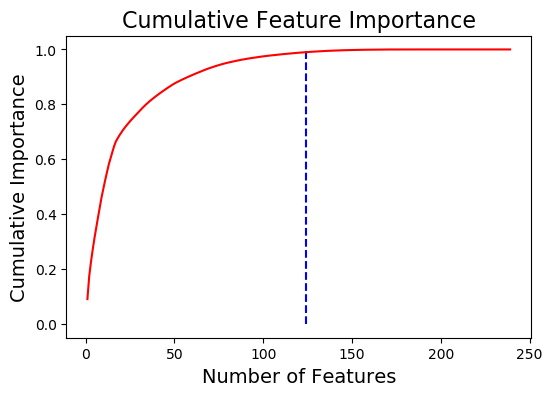
在左边,我们有 plot_n最重要的特征(按照归一化重要性绘制,总和为1),在右边,我们有相对于特征数量的累积重要性。垂直线是在累积重要性的“阈值”处绘制的,在本例中是99%。
对于基于重要性的方法,有两个注意事项值得记住:
梯度提升机的训练是随机的,这意味着每次运行模型时特征输入都会发生变化
这应该不会产生重大影响(最重要的特征不会突然变得最不重要),但是它会改变一些特征的顺序。它还可以影响识别的零重要性特征的数量。如果特征的重要性每次都发生变化,不要感到惊讶!
为了训练机器学习模型,首先对特征进行“独热编码”。这意味着一些重要性为0的特征可能是在建模过程中添加的独热编码特征。
当我们到达特征删除阶段时,有一个选项可以删除任何添加的独热编码特征。然而,如果我们在特征选择之后进行机器学习,我们还是要对特征进行一次独热编码!
低重要性特征
下一个方法建立在零重要性函数的基础上,利用模型的特征输入进行进一步的选择。函数 identify_low_importance查找对总重要性没什么贡献的最低重要性的特征。
例如,下面的调用找到了最不重要的特征,这些特征对于99%的总重要性是不需要的:
fs.identify_low_importance(cumulative_importance = 0.99)
123 features required for cumulative importance of 0.99 after one hot encoding.
116 features do not contribute to cumulative importance of 0.99.基于累积重要性图和这些信息,梯度提升机认为许多特征与学习无关。同样,这种方法的结果将在每次训练运行时发生变化。
要查看dataframe中的所有重要特征:
fs.feature_importances.head(10)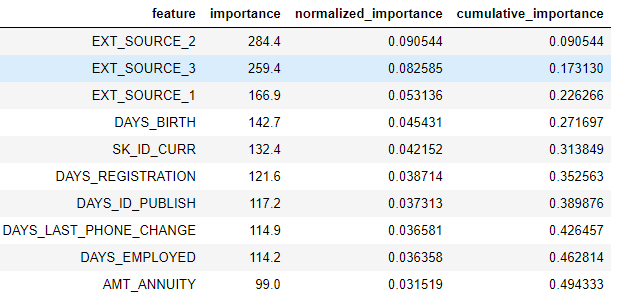
low_importance方法借鉴了使用主成分分析(PCA)的一种方法,这种方法通常只保留需要保留一定百分比的方差(如95%)的PC。占总重要性的百分比是基于相同的思想。
基于特征重要性的方法只有在我们使用基于树的模型进行预测时才真正适用。除了随机性之外,基于重要性的方法是一种黑盒方法,因为我们不知道为什么模型认为这些特征是无关的。如果使用这些方法,请多次运行它们以查看结果的变化,也许还可以创建具有不同参数的多个数据集进行测试!
单一唯一值的特征
最后一个方法是相当基本的:找到任何只有一个惟一值的列。只有一个惟一值的特征对机器学习没有用处,因为这个特征的方差为零。例如,基于树的模型永远不能对只有一个值的特征进行分割(因为没有分组来划分观察结果)。
这里没有参数选择,不像其他方法:
fs.identify_single_unique()
4 features with a single unique value.我们可以绘制每个类别中唯一值的数量直方图:
fs.plot_unique()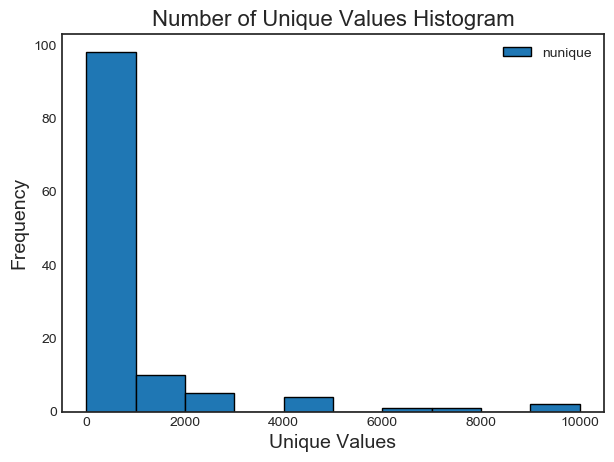
需要记住的一点是,在默认情况下计算panda中的惟一值之前先删除 NaNs 。
去除特征
一旦我们确定了要丢弃的特征,我们有两个选项来删除它们。所有要删除的特征都存储在 FeatureSelector的 ops字典中,我们可以使用列表手动删除特征。另一个选项是使用“remove”内置函数。
对于这个方法,我们传入用于删除特征的 方法。如果我们想使用所有实现的方法,我们只需传入 methods='all'。
# Remove the features from all methods (returns a df)
train_removed = fs.remove(methods = 'all')
['missing', 'single_unique', 'collinear', 'zero_importance', 'low_importance'] methods have been run
Removed 140 features.此方法返回一个删除了特征的dataframe。还可以删除机器学习过程中创建的独热编码特征:
train_removed_all = fs.remove(methods = 'all', keep_one_hot=False)
Removed 187 features including one-hot features.在继续操作之前,检查将被删除的特征可能是一个好主意!原始数据集存储在 FeatureSelector的 data 属性中作为备份!
一次运行所有方法
我们可以使用 identify_all而不是单独使用这些方法。这需要每个方法的参数字典:
fs.identify_all(selection_params = {'missing_threshold': 0.6, 'correlation_threshold': 0.98, 'task': 'classification', 'eval_metric': 'auc', 'cumulative_importance': 0.99})
151 total features out of 255 identified for removal after one-hot encoding.请注意,由于我们重新运行了模型,总特征的数量将发生变化。然后可以调用“remove”函数来删除这些特征。
总结
在训练机器学习模型之前,Feature Selector类实现了几个常见的删除特征的操作。它提供了识别要删除的特征以及可视化功能。方法可以单独运行,也可以一次全部运行,以实现高效的工作流。
missing、 collinear和 single_unique方法是确定的,而基于特征重要性的方法将随着每次运行而改变。特征选择,就像机器学习领域,很大程度上是经验主义的,需要测试多个组合来找到最佳答案。在pipeline中尝试几种配置是最佳实践,特征选择器提供了一种快速评估特征选择参数的方法。
 — END—
— END— 英文原文:https://towardsdatascience.com/a-feature-selection-tool-for-machine-learning-in-python-b64dd23710f0

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()
这篇关于一个可以进行机器学习特征选择的python工具的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





