残差专题

Resnet图像识别入门——残差结构
桃树、杏树、梨树,你不让我,我不让你,都开满了花赶趟儿。红的像火,粉的像霞,白的像雪。花里带着甜味儿;闭了眼,树上仿佛已经满是桃儿、杏儿、梨儿。花下成千成百的蜜蜂嗡嗡地闹着,大小的蝴蝶飞来飞去。野花遍地是:杂样儿,有名字的,没名字的,散在草丛里,像眼睛,像星星,还眨呀眨的。 朱自清在写《春》的时候,或许也没有完全认清春天的所有花,以至于写出了“有名字的,没名字的,散在草丛中”这样的句子。

【ShuQiHere】从残差思想到 ResNet:深度学习的突破性创新
【ShuQiHere】引言 在深度学习的迅速发展中,卷积神经网络(CNN)凭借其在计算机视觉领域的出色表现,已经成为一种主流的神经网络架构。然而,随着网络层数的增加,研究人员逐渐发现了一个关键问题:梯度消失 😖 和 梯度爆炸 💥,这使得训练非常深的网络变得极其困难。为了解决这一问题,残差思想 💡 被提出,并在 2015 年由 Kaiming He 等人正式引入 ResNet 中。这一创新不

CV-CNN-2016:GoogleNet-V4【用ResNet模型的残差连接(Residual Connection)思想改进GoogleNet-V3的结构】
Inception V4研究了Inception模块与残差连接的结合。 ResNet结构大大地加深了网络深度,还极大地提升了训练速度,同时性能也有提升。 Inception V4主要利用残差连接(Residual Connection)来改进V3结构,得到Inception-ResNet-v1,Inception-ResNet-v2,Inception-v4网络。 ResNet的残差结构如下

秃姐学AI系列之:残差网络 ResNet
目录 残差网络——ResNet 残差块思想 ResNet块细节 ResNet架构 总结 代码实现 残差块 两种 ResNet 块的情况 ResNet 模型 QA 由上图发现,只有当较复杂的函数类包含较小的函数类时,才能确保提高它们的性能。 对于深度神经网络,如果我们能将新添加的层训练成恒等映射(identity function)f(x)=x,新模型和原模型将同样
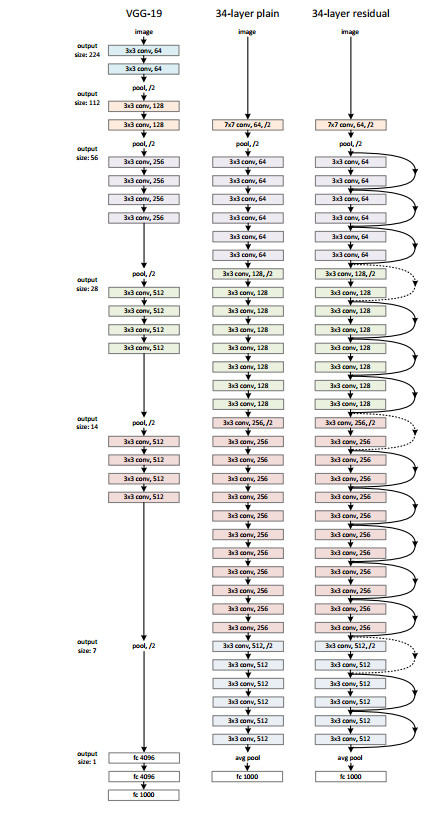
深度残差网络(ResNet)浅析
第一次写博客,欢迎大家来拍砖。 网络层数深了,会面临梯度消失的问题。深度大了为什么会出现梯度消失问题?在于假设网络的输入和输出和网络参数的分布取值大约[-1,1],为什么这样说,想想数据预处理(RGB值0-256抓化为0-1或-1到1),网络参数初始化服从高斯分布,batch normalization(把数据转化为正态分布),sigmoid function的输出范围。BP算法中链式求导的法

深度学习----------------------残差网络ResNet
目录 ResNet加更多的层总是改进精度吗?残差块ResNet块细节不同的残差块ResNet块ResNet架构总结 ResNet代码实现残差块输入和输出形状一致增加输出通道数的同时,减半输出的高和宽ResNet模型观察ResNet中不同模块的输入形状是如何变化的训练模型 问题ResNet为什么能训练出1000层的模型?ResNet是这样解决的 问题 ResNet

从函数逼近角度理解神经网络、残差连接与激活函数
概述 最近思考激活函数的时候,突然想到神经网络中残差连接是不是和函数的泰勒展开很像,尤其是在激活函数 f ( x ) = x 2 f(x)=x^2 f(x)=x2时(这个激活函数想法来源于 f ( x ) = R e L U 2 ( x ) [ 3 ] f(x)=ReLU^2(x)[3] f(x)=ReLU2(x)[3]),所以验证了一下就顺便写下来了,本文抛砖引玉,如果有建议或更好的想法可以写
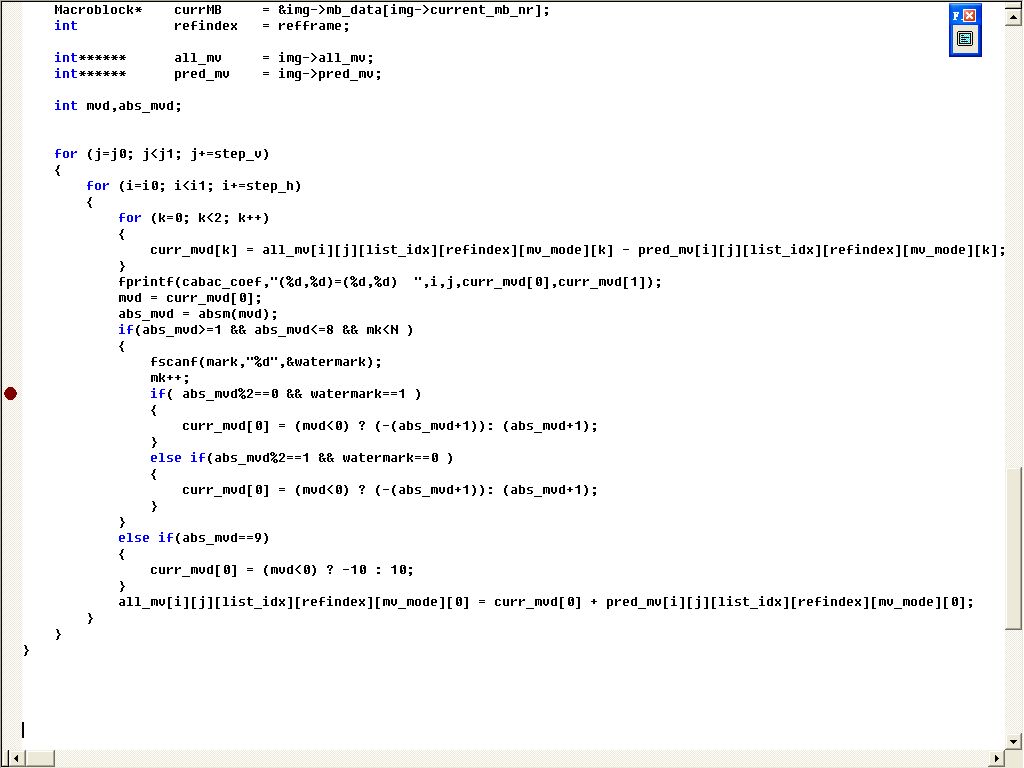
H.264中最优运动矢量残差的输出
原文转自:http://www.360doc.cn/article/1412027_118336851.html H.264中最优运动矢量残差的输出 2010-07-27 10:03 最优运动矢量的求解是在encode_one_macroblock函数里面,因此该函数执行完毕运动矢量及分割模式也就相应的确定了,这里我们对这一块作一下简要的分析。 运动矢量的写码流是在
解码 ResNet:残差块如何增强深度学习性能【数学推导】
ResNet简介 残差网络结构 残差网络(ResNet)是由何凯明等人在2015年提出的,它极大地提高了深度神经网络的训练效果,尤其是非常深的网络。ResNet的核心思想是引入“残差块”(Residual Block),通过跳跃连接(Shortcut Connection)解决深层网络的梯度消失和梯度爆炸问题。 结构示意图: 输入层一系列的卷积层(Conv Layers)残差块(Resid
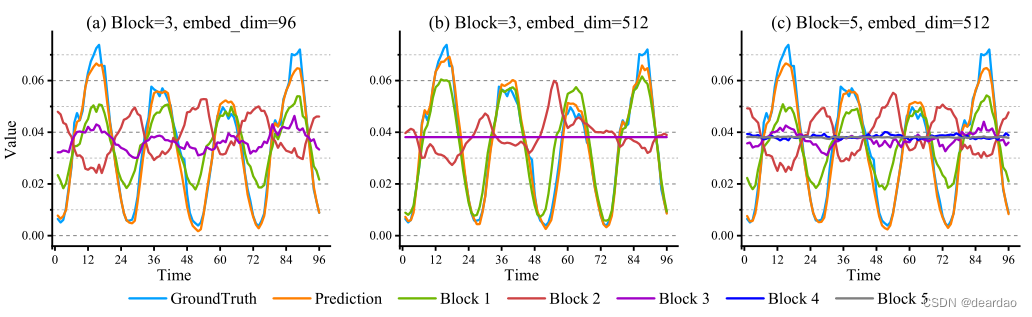
【减法网络】Minusformer:通过逐步学习残差来改进时间序列预测
摘要 本文发现泛在时间序列(TS)预测模型容易出现严重的过拟合。为了解决这个问题,我们采用了一种去冗余的方法来逐步恢复TS的真实值。具体来说,我们引入了一种双流和减法机制,这是一种深度Boosting集成学习方法。通过将信息聚合机制从加法转向减法,对普通的Transformer进行了改造。然后,我们在原始模型的每个块中加入一个辅助输出分支,构建一条通往最终预测的高速公路。该分支后续模块的输出将减

6.13.1 使用残差神经网络堆叠集成进行乳腺肿块分类和诊断的综合框架
计算机辅助诊断 (CAD) 系统需要将肿瘤检测、分割和分类的自动化阶段按顺序集成到一个框架中,以协助放射科医生做出最终诊断决定。 介绍了使用堆叠的残差神经网络 (ResNet) 模型(即 ResNet50V2、ResNet101V2 和 ResNet152V2)进行乳腺肿块分类和诊断的最后步骤。这项工作提出了将检测到和分割的乳腺肿块分类为恶性或良性的任务,并诊断乳腺影像报告和数据系统 (BI-R


DeepSORT(目标跟踪算法)中的解三角方程计算标准化残差(解线性方程组)
DeepSORT(目标跟踪算法)中的解三角方程计算标准化残差(解线性方程组) flyfish 《DeepSORT(目标跟踪算法)中的计算观测值与状态估计的马氏距离》这篇文章介绍了Cholesky 分解。Cholesky 分解将协方差矩阵分解成下三角矩阵,使得求解过程可以高效进行。这篇是利用 solve_triangular 函数,我们可以高效地解这些线性方程组,从而得到标准化残差和更新后的状态
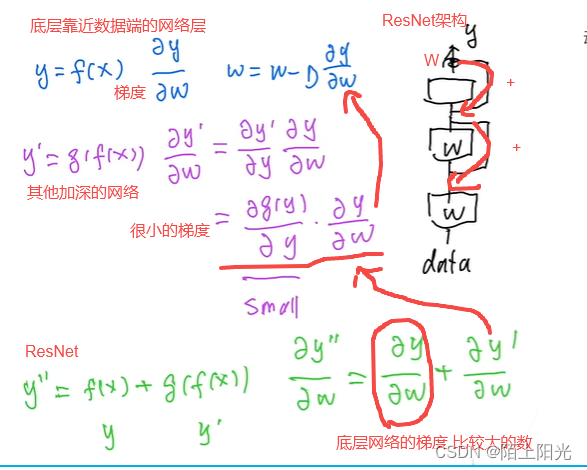
动手学深度学习29 残差网络ResNet
动手学深度学习29 残差网络ResNet ResNet代码ReLU的两种调用1. 使用 `torch.nn.ReLU` 模块2. 使用 `torch.nn.functional.relu` 函数总结 QA29.2 ResNet 为什么能训练处1000层的模型ResNet的梯度计算怎么处理梯度消失的 QA ResNet 更复杂模型包含小模型,不一定改进,但是加更深的层更复杂的

Meta Llama 3 残差结构
Meta Llama 3 残差结构 flyfish 在Transformer架构中,残差结构(Residual Connections)是一个关键组件,它在模型的性能和训练稳定性上起到了重要作用。残差结构最早由He et al.在ResNet中提出,并被广泛应用于各种深度学习模型中。 残差结构的定义 残差结构通过将输入直接与通过一个或多个变换后的输出相加来形成。具体来说,如果输入为 x,经过
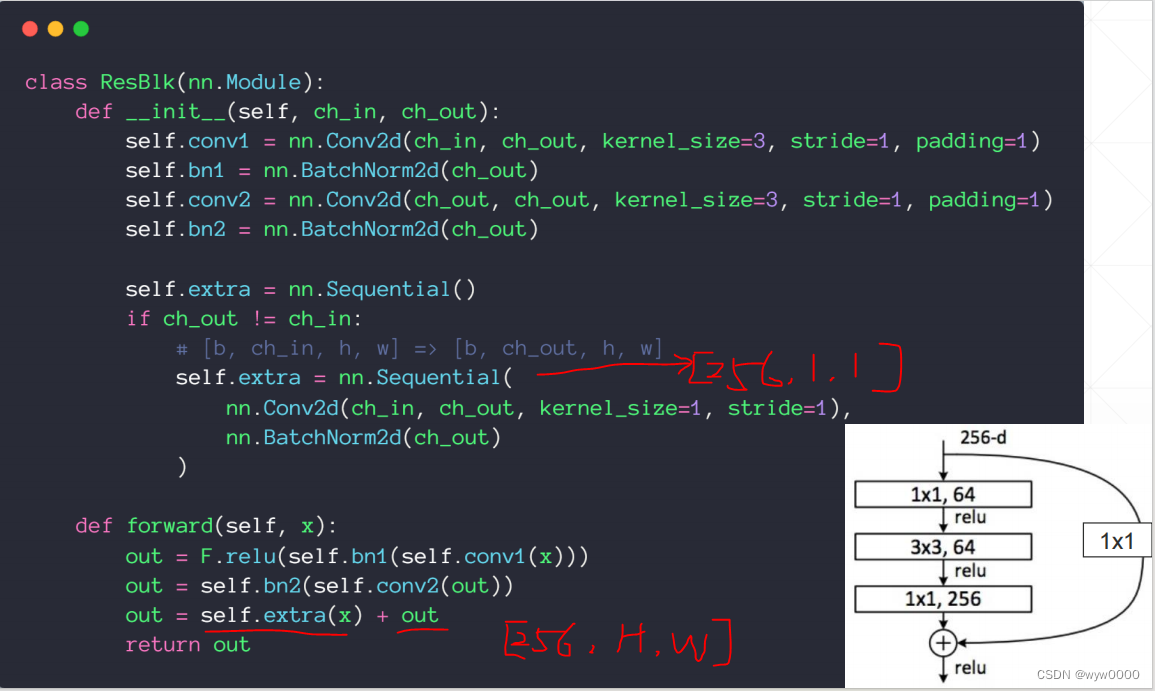
pytorch-深度残差网络resnet
目录 1. ResNet的由来2. ResNet pytorch实现 1. ResNet的由来 2014年网络层次达到了22层以后,随着层数的增多,反而性能会越来越差,其原因是ΔE对ΔWij的导数依赖于上一层的δ,由于δ误差不断积累,导致出现梯度弥散的问题。 假设网络有30层,为了保证在22层基础上增加8层后,至少不会比22层差,那么就跳过8层网络,增加一个shortcut短路
【TensorFlow深度学习】卷积层变种与深度残差网络原理
卷积层变种与深度残差网络原理 卷积层变种与深度残差网络:探究卷积神经网络的进化与优化策略卷积层:深度学习的基石变种与卷积层变种深差网络:深度网络的优化策略实战代码示例:ResNet模块实现结语 卷积层变种与深度残差网络:探究卷积神经网络的进化与优化策略 在深度学习的浩瀚海中,卷积神经网络(CNN)犹如一座灯塔,而深度残差网络(ResNet)则是在这座塔尖的明珠。本文将深入浅
残差平方和(RSS)、均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)
残差平方和(RSS) 等同于SSE(误差项平方和) 实际值与预测值之间差的平方之和。 MSE: Mean Squared Error 均方误差是RSS的期望值(或均值); MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。 RMSE 均方根误差:均方根误差是均方误差的算术平方根 MAE :Mean Absolute Error 平均绝对误差是绝对

ResNet残差网络的学习【概念+翻译】
基于何明凯前辈论文的学习 1.主要内容(背景) 1、首先提了一个base:神经网络的深度越深,越难以训练。 2、原因:因为随着神经网络层数的增加,通常会遇到梯度消失或梯度爆炸等问题,这会导致训练变得更加困难。梯度消失指的是:在反向传播过程中,梯度逐渐变得非常小,以至于无法有效地更新网络参数。梯度爆炸则是相反的情况,梯度变得非常大,导致参数更新过大,甚至使网络变得不稳定。 3、目前基于我已知的方

自适应感兴趣区域的级联多尺度残差注意力CNN用于自动脑肿瘤分割| 文献速递-深度学习肿瘤自动分割
Title 题目 Cascade multiscale residual attention CNNs with adaptive ROI for automatic brain tumor segmentation 自适应感兴趣区域的级联多尺度残差注意力CNN用于自动脑肿瘤分割 01 文献速递介绍 脑肿瘤是大脑细胞异常和不受控制的增长,被认为是神经系统中最具威胁性的疾病之一。

Transformer详解(4)-前馈层残差连接层归一化
1、前馈层 前馈层接收自注意力层的输出作为输入。 from torch import nnimport torch.nn.functional as Fclass FeedForward(nn.Module):def __init__(self, d_model=512, d_ff=2048, dropout=0.1):super().__init__()# d_ff 默认设置为2048s
大话深度残差网络(DRN)ResNet
论文地址:Deep Residual Learning for Image Recognition 一、引言 深度残差网络(Deep residual network, ResNet)的提出是CNN图像史上的一件里程碑事件,让我们先看一下ResNet在ILSVRC和COCO 2015上的战绩: ResNet取得了5项第一,并又一次刷新了CNN模型在ImageNet上的历史: Res
GBDT中残差和梯度的关系
采用Square loss为损失函数时,负梯度和残差相等。不过,当我们采用Absolute loss/Huber loss等其它损失函数时,负梯度只是残差的近似。 转自 http://aandds.com/blog/ensemble-gbdt.html

注意力机制篇 | YOLOv8改进之在C2f模块引入反向残差注意力模块iRMB | CVPR 2023
前言:Hello大家好,我是小哥谈。反向残差注意力模块iRMB是一种用于图像分类和目标检测的深度学习模块。它结合了反向残差和注意力机制的优点,能够有效地提高模型的性能。在iRMB中,反向残差指的是将原始的残差块进行反转,即将卷积操作和批量归一化操作放在了后面。这样做的好处是,可以提高模型的非线性表达能力,同时减少了参数量。🌈 目录

AI笔记: 关于回归、线性回归、预测残差、残差平方和
关于回归 这里给出了一个典型的回归任务,假设我们要根据商品在线广告的费用来预测每月电子商务的销售量通常的做法是会收集到很多历史数据,然后假设某个商品他在线广告的费用是1.7的时候,每月电子商务的销售量是368广告费用是1.5的时候,销售达成340等等,有了这些数据之后,我们希望能学习到在线广告费用,对电子商务的销售量的一个影响给一个新的数据,我们只知道在线广告的费用假设是2.8的时候,