概率分布专题

Weibull概率分布纸(EXCEL VBA实现)
在学习Weibull分布理论的时候,希望有一张Weibull概率纸,用来学习图解法。但是在度娘上没有找到的Weibull概率纸的电子版。在书上看到的Weibull概率纸,只能复印下来使用。于是萌生了自己制作Weibull概率纸的想法,帮助自己更好地学习。 本人擅长使用各种计算机语言,C,C++,Matlab,Scilab等等,但是始终钟爱与VBA,认为VBA可以实现一切你想要的东西,由于在企业里不

概率论(三)-多维随机变量及其分布:n维随机变量、概率分布函数F(x1,x2,..xn)、联合分布律、联合概率密度、边缘分布律、边缘概率密度、条件分布律、条件概率密度、β函数、Γ函数、max{X,Y}
1 二维随机变量 2 边缘分布 3 条件分布 4 相互独立的随机变量 5 两个随机变量的函数的分布

如何理解概率分布函数和概率密度函数?
我的理解: 当是离散型时,概率函数为pi=P(X=ai)(i=1,2,3,4,5,6),每次只能取一个点的概率;把所有可能的离散型随机变量的值分布和值的概率都列举出来那就是概率分布;概率分布函数就是在某一个区间内概率发生的情况,也就是概率函数取值的累加结果,例如F(X)=P(X<=a) =X取值小于等于a时的概率和。 当是连续性时,概率密度函数(对应于离散型的概率函数)有具体的意义,但是不能直接
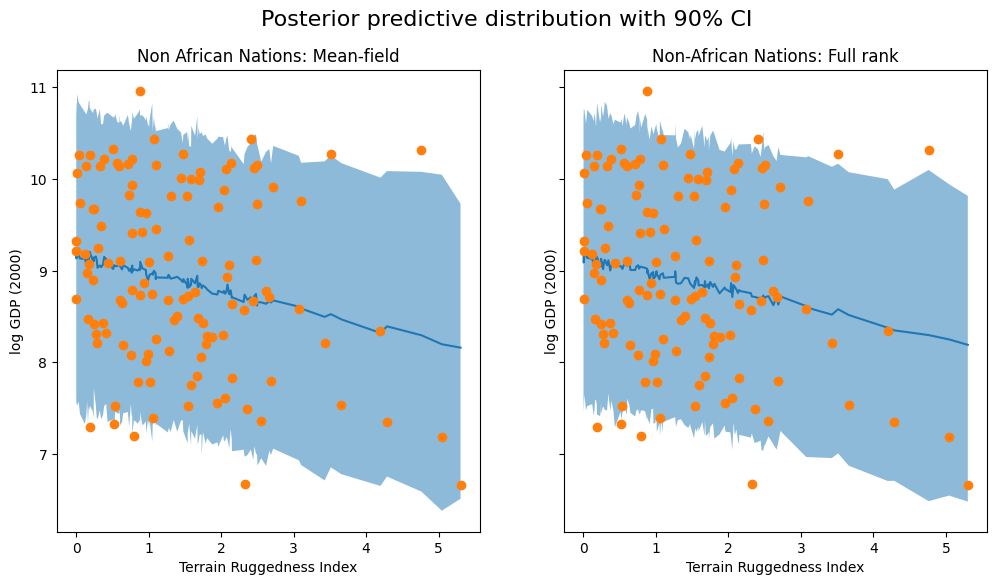
Pyro简介 贝叶斯神经网络bnn , 隐马尔可夫模型 人工智能python python 概率分布程序包的使用教程
Pyro简介 镜像GitCode - 全球开发者的开源社区,开源代码托管平台 gitcode.com/gh_mirrors/py/pyro/blob/dev/tutorial/source/bayesian_regression_ii.ipynb Introduction to Pyro — Pyro Tutorials 1.9.1 documentation pyro.ai/examples
Generalized Focal Loss:Focal loss魔改以及预测框概率分布,保涨点 | NeurIPS 2020
为了高效地学习准确的预测框及其分布,论文对Focal loss进行拓展,提出了能够优化连续值目标的Generalized Focal loss,包含Quality Focal loss和Distribution Focal loss两种具体形式。QFL用于学习更好的分类分数和定位质量的联合表示,DFL通过对预测框位置进行general分布建模来提供更多的信息以及准确的预测。从实验结果来看,GF
KL距离(衡量两个概率分布的差异情况)
KL距离,是Kullback-Leibler差异(Kullback-Leibler Divergence)的简称,也叫做相对熵(Relative Entropy)。它衡量的是相同事件空间里的两个概率分布的差异情况。 KL距离全称为Kullback-Leibler Divergence,也被称为相对熵。公式为: 感性的理解,KL距离可以解释为在相同的事件空间P(x)中两个概率P(x)和Q(x)分
max与min函数的概率分布思考
max与min函数的概率分布思考 @(概率论) 给定一样本序列则: max(X1,X2,...,Xn)≤a⟺X1≤a,X2≤a,...,Xn≤a max(X_1,X_2,...,X_n) \leq a \Longleftrightarrow X_1\leq a, X_2\leq a,...,X_n \leq a min(X1,X2,...,Xn)≥a⟺X1≥a,X2≥a,...,Xn≥

概率密度函数、概率分布函数、概率质量函数
1.概率密度函数 1.1. 定义 如果对于随机变量X的分布函数F(x),存在非负函数f(x),使得对于任意实数有 则称X为连续型随机变量,其中F(x)称为X的概率密度函数,简称概率密度。(f(x)>=0,若f(x)在点x处连续则F(x)求导可得) f(x)并没有很特殊的意义,但是通过其值得相对大小得知,若f(x)越大,对于同样长度的区间,X落在这个区间的概率越大。

连续型三种典型概率分布(概率密度)
一,均匀分布 二,指数分布 三,正态分布 参考博客:https://blog.csdn.net/u010916338/article/details/81331862

AI学习指南概率论篇-概率分布
AI学习指南概率论篇-概率分布 概率分布的概述 概率分布是概率论中的一个重要概念,用于描述随机变量的取值和其对应的概率。概率分布可以帮助我们理解和预测事件发生的可能性,并在AI中扮演着重要角色。在机器学习和深度学习中,概率分布被广泛应用于模型的训练、推理和评估等方面。 概率分布在AI中的使用场景 概率分布在AI中的使用场景非常广泛。在模型的训练中,我们常常使用概率分布来拟合观测数据,并利用
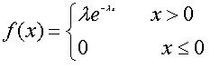
利用MATLAB理解常见概率分布
二项分布 在概率论和统计学中,二项分布(英语:Binomial distribution)是n个独立的是/非试验中成功的次数的离散概率分布,其中每次试验的成功概率为p。这样的单次成功/失败试验又称为伯努利试验。实际上,当n= 1时,二项分布就是伯努利分布。二项分布是显著性差异的二项试验的基础。 >> N=100;>> p=0.5;>> k=0:N;>>pdf=binopdf(k,
深度学习必懂的 13 种概率分布(附链接)
来源:AI开发者 本文约为1400字,建议阅读5分钟 本文为你介绍基本概率分布教程,大多数和使用 python 库进行深度学习有关。 概率分布概述 共轭意味着它有共轭分布的关系。 在贝叶斯概率论中,如果后验分布 p(θx)与先验概率分布 p(θ)在同一概率分布族中,则先验和后验称为共轭分布,先验称为似然函数的共轭先验。共轭先验维基百科在这里(https://en.wikipedia.or
【机器学习基础】概率分布之指数族分布
本系列为《模式识别与机器学习》的读书笔记。 一,指数族分布 1,指数族分布基本概念 参数为 η \boldsymbol{\eta} η 的变量 x \boldsymbol{x} x 的指数族分布定义为具有下⾯形式的概率分布的集合: p ( x ∣ η ) = h ( x ) g ( η ) exp { η T μ ( x ) } (2.106) p(\boldsymbol{x

【机器学习基础】概率分布之高斯分布
本系列为《模式识别与机器学习》的读书笔记。 一,多元高斯分布 考虑⾼斯分布的⼏何形式,⾼斯对于 x \boldsymbol{x} x 的依赖是通过下⾯形式的⼆次型: Δ 2 = ( x − μ ) T Σ − 1 ( x − μ ) (2.30) \Delta^{2} = (\boldsymbol{x} - \boldsymbol{\mu})^{T} \boldsymbol{\Sig

【机器学习基础】概率分布之变量
本系列为《模式识别与机器学习》的读书笔记。 一,二元变量 1,二项分布 考虑⼀个⼆元随机变量 x ∈ { 0 , 1 } x \in \{0, 1\} x∈{0,1}。 例如, x x x 可能描述了扔硬币的结果, x = 1 x = 1 x=1 表⽰“正⾯”, x = 0 x = 0 x=0 表⽰反⾯。我们可以假设有⼀个损坏的硬币,这枚硬币正⾯朝上的概率未必等于反⾯朝上的概率。 x
概率统计——讲透最经典的三种概率分布
本文始发于个人公众号:TechFlow 这一讲当中我们来探讨三种经典的概率分布,分别是伯努利分布、二项分布以及多项分布。 在我们正式开始之前,我们先来明确一个概念,我们这里说的分布究竟是什么? 无论是在理论还是实际的实验当中,一个事件都有可能有若干个结果。每一个结果可能出现也可能不出现,对于每个事件而言出现的可能性就是概率。而分布,就是衡量一个概率有多大。 伯努利分布 明确了分布

《统计学简易速速上手小册》第3章:概率分布与抽样技术(2024 最新版)
文章目录 3.1 重要的概率分布3.1.1 基础知识3.1.2 主要案例:顾客到访分析3.1.3 拓展案例 1:产品缺陷率分析3.1.4 拓展案例 2:日销售额预测 3.2 抽样方法与推断3.2.1 基础知识3.2.2 主要案例:顾客满意度调查3.2.2 拓展案例 1:新产品测试3.2.4 拓展案例 2:员工满意度调查 3.3 应用抽样技术3.3.1 基础知识3.3.2 主要案例:用户体

已知高维高斯联合概率分布求边缘概率分布以及条件概率分布
博主最近在看卡尔曼滤波算法,个人认为在卡尔曼滤波算法中最核心的部分莫过于高维高斯联合概率分布的性质,因此打算将这些性质整理成博客记录下来方便自己今后的学习,如果有哪里不对,欢迎各位读者指正。 一 引理 这里我引入一个定理,这个定理不在本博客证明,因为它很直观,便于理解。 假设随机变量 X X X服从均值为 μ \mu μ,协方差矩阵为 Σ \Sigma Σ的高斯分布(为了更具有一般性,

《SPSS统计学基础与实证研究应用精解》视频讲解:SPSS中用到的概率分布
《SPSS统计学基础与实证研究应用精解》2.2 视频讲解 视频为《SPSS统计学基础与实证研究应用精解》张甜 杨维忠著 清华大学出版社 一书的随书赠送视频讲解2.2节内容。本书已正式出版上市,当当、京东、淘宝等平台热销中,搜索书名即可。本书旨在手把手教会使用SPSS撰写实证研究类论文或开展数据分析。常用统计学原理、实证研究的套路、调查问卷设计、信度分析、效度分析、T检验、ANOVA分析、

机器学习:李宏毅:概率分布生成概率模型
1.概率分布 由于前面学习的是回归,因此我们通过回归的方法来查看概率分布 分类是class 1 的时候结果是1 分类为class 2的时候结果是-1; 测试时,如果结果接近1的是class1 ,如果结果接近-1的是class2。 但是呢,这只是看起来很美丽,但是如果当结果远远大于1的时候,他的分类应该是class1还是class2呢? 我们为了降低整体误差,需要调整已经找到的分类函数,这样会导

学习中的多种概率分布
概率分布是随机变量所有可能结果及其相应概率的列表。 概率分布的目的:反向推演出某一个事态(随机变量)发生的概率,为决策提供依据,掌控事态变化的关键。 下图是多种概率分布的联系。 其中共轭(conjugate)表示的是互为共轭的概率分布; Multi-Class 表示随机变量多于 2 个; N Times 表示我们还会考虑先验分布 P(X)。 共轭的意思

Camshift原理 camshift利用目标的颜色直方图模型将图像转换为颜色概率分布图,初始化一个搜索窗的大小和位置,并根据上一帧得到的结果自适应调整搜索窗口的位置和大小,从而定位出当前图像中目标的
Camshift原理 camshift利用目标的颜色直方图模型将图像转换为颜色概率分布图,初始化一个搜索窗的大小和位置,并根据上一帧得到的结果自适应调整搜索窗口的位置和大小,从而定位出当前图像中目标的中心位置。 分为三个部分: 1--色彩投影图(反向投影): (1).RGB颜色空间对光照亮度变化较为敏感,为了减少此变化对跟踪效果的影响,首先将图像从RGB空间转换到HSV空间。(2).然后对其中