变分专题

时序预测|变分模态分解-双向时域卷积-双向门控单元-注意力机制多变量时间序列预测VMD-BiTCN-BiGRU-Attention
时序预测|变分模态分解-双向时域卷积-双向门控单元-注意力机制多变量时间序列预测VMD-BiTCN-BiGRU-Attention 文章目录 一、基本原理1. 变分模态分解(VMD)2. 双向时域卷积(BiTCN)3. 双向门控单元(BiGRU)4. 注意力机制(Attention)总结流程 二、实验结果三、核心代码四、代码获取五、总结 时序预测|变分模态分解-双向时域卷积

ML17_变分推断Variational Inference
1. KL散度 KL散度(Kullback-Leibler divergence),也称为相对熵(relative entropy),是由Solomon Kullback和Richard Leibler在1951年引入的一种衡量两个概率分布之间差异的方法。KL散度不是一种距离度量,因为它不满足距离度量的对称性和三角不等式的要求。但是,它仍然被广泛用于量化两个概率分布之间的“接近程度”。 在

平均场变分推断:以混合高斯模型为例
文章目录 一、贝叶斯推断的工作流二、一个业务例子三、变分推断四、平均场理论五、业务CASE的平均场变分推断求解六、代码实现 一、贝叶斯推断的工作流 在贝叶斯推断方法中,工作流可以总结为: 根据观察者的知识,做出合理假设,假设数据是如何被生成的将数据的生成模型转化为数学模型根据数据通过数学方法,求解模型参数对新的数据做出预测 在整个pipeline中,第1点数据的生成过程

深度学习-生成模型:Generation(Tranform Vector To Object with RNN)【PixelRNN、VAE(变分自编码器)、GAN(生成对抗网络)】
深度学习-生成模型:Generation(Tranform Vector To Object with RNN)【PixelRNN、VAE(变分自编码器)、GAN(生成对抗网络)】 一、Generator的分类二、Native Generator (AutoEncoder's Decoder)三、PixelRNN1、生成句子序列2、生成图片3、生成音频:WaveNet4、生成视频:Video

变分自编码器(Variational Autoencoder, VAE):深入理解与应用
变分自编码器(Variational Autoencoder, VAE):深入理解与应用 在深度学习的广阔领域中,生成模型一直是研究的热点之一。其中,VAE(变分自编码器)作为AE(自编码器)的一种扩展,以其独特的优势在生成任务中展现了卓越的性能。本文将深入探讨VAE相对于AE的改进之处,并解析这些改进如何提升模型的生成能力和泛化性能。 一、引言 自编码器(Autoencoder, AE

【自由能系列(中级)】自由能与变分自由能——从状态到配置的效益最大化
自由能与变分自由能——从状态到配置的效益最大化 关键词提炼 #自由能 #变分自由能 #状态函数 #配置函数 #效益最大化 #物理系统 #优化问题 第一节:自由能与变分自由能的类比与核心概念 1.1 自由能与变分自由能的类比 自由能和变分自由能可以被视为物理系统的“效益计算器”。 自由能衡量了系统在一个给定状态下的“效益”,而变分自由能则进一步考虑了系统配置的变化对效益的影响。 就像企业
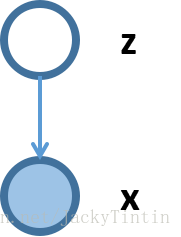
Autoencorder理解(5):VAE(Variational Auto-Encoder,变分自编码器)
reference: http://blog.csdn.net/jackytintin/article/details/53641885 近年,随着有监督学习的低枝果实被采摘的所剩无几,无监督学习成为了研究热点。VAE(Variational Auto-Encoder,变分自编码器)[1,2] 和 GAN(Generative Adversarial Networks) 等模型,受到越来越多的关

变分自编码器(VAE)与生成对抗网络(GAN)在TensorFlow中实现
变分自编码器(VAE)与生成对抗网络(GAN)是复杂分布上无监督学习最具前景的两类方法。本文中,作者在MNIST上对这两类生成模型的性能进行了对比测试。 本项目总结了使用变分自编码器(Variational Autoencode,VAE)和生成对抗网络(GAN)对给定数据分布进行建模,并且对比了这些模型的性能。你可能会问:我们已经有了数百万张图像,为什么还要从给定数据分布中生成图像呢?正

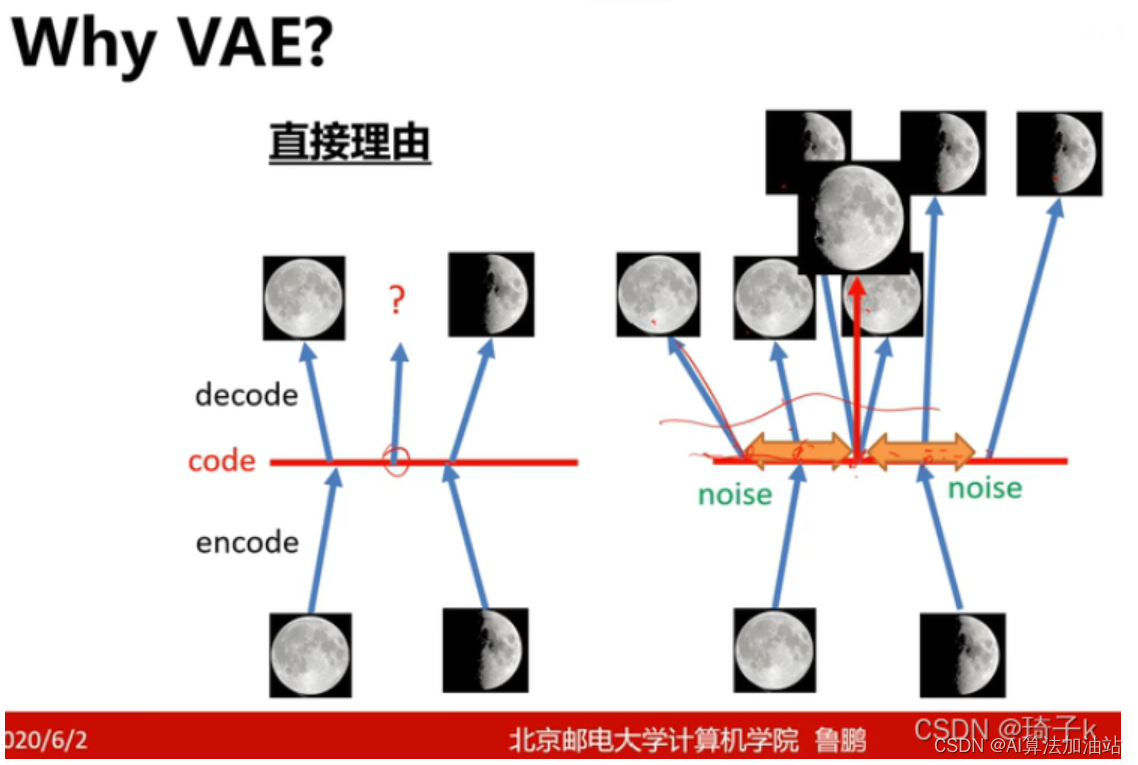
变分自编码器(Variational Autoencoder, VAE)
目录 why VAE: 关于变分自编码器,这篇文章讲的不错 1. 自编码器(Autoencoder)的基础 2. 引入概率图模型 3. 重参数化技巧 4. 损失函数 5. 应用 变分自编码器(Variational Autoencoder, VAE) why VAE: 关于变分自编码器,这篇文章讲的不错 机器学习方法—优雅的模型(一):变分自编码器(VAE

稀疏变分高斯过程【超简单,全流程解析,案例应用,简单代码】
文章目录 简介1. 定义和目标2. 协方差函数与引入点3. 变分分布4. 近似后验参数的计算5. 计算具体步骤6. 优势与应用(时间复杂度) 应用案例1. 初始化参数2. 计算核矩阵3. 计算优化变分参数4. 预测新数据点5. 结果展示 符号和参数说明 python代码 简介 稀疏变分高斯过程(Sparse Variational Gaussian Processes, SVG
使用变分编解码器实现自动图像生成
深度学习不仅仅在擅长于从现有数据中发现规律,而且它能主动运用规律创造出现实世界没有的实例来。例如给网络输入大量的人脸图片,让它识别人脸特征,然后我们可以指导网络创建出现实世界中不存在的人脸图像,把深度学习应用在创造性生成上是当前AI领域非常热门的应用。 从本节开始,我们将接触神经网络在图像生成方面的应用。有两种专门构建的网络在图像生成上能实现良好效果,一种网络叫变分编解码器,另一种叫生成型对抗性

告别互信息:跨模态人员重新识别的变分蒸馏
Farewell to Mutual Information: Variational Distillation for Cross-Modal Person Re-Identification 摘要: 信息瓶颈 (IB) 通过在最小化冗余的同时保留与预测标签相关的所有信息,为表示学习提供了信息论原理。尽管 IB 原理已应用于广泛的应用,但它的优化仍然是一个具有挑战性的问题,严重依赖于互信息的



贝叶斯深度学习——基于PyMC3的变分推理
时间 2016-06-12 10:13:38 CSDN 原文 http://geek.csdn.net/news/detail/80255 主题 深度学习 PyMC3 原文链接: Bayesian Deep Learning 作者: Thomas Wiecki ,关注贝叶斯模型与Python 译者:刘翔宇 校对:赵屹华 责编:周建丁(zhouj

时序分解 | Matlab实现WOA-VMD鲸鱼算法WOA优化VMD变分模态分解
时序分解 | Matlab实现WOA-VMD鲸鱼算法WOA优化VMD变分模态分解 目录 时序分解 | Matlab实现WOA-VMD鲸鱼算法WOA优化VMD变分模态分解效果一览基本介绍程序设计参考资料 效果一览 基本介绍 Matlab实现WOA-VMD鲸鱼算法WOA优化VMD变分模态分解(完整源码和数据) 1.利用鲸鱼优化算法优化vmd中的参数k、a,分解
指数族分布和变分推断
指数族分布 指数族分布的pdf / pmf可以表示成: p ( x ∣ η ) = h ( x ) e x p ( T ( x ) T η − A ( η ) ) p(x| \eta)=h(x)exp(T(x)^T \eta - A(\eta)) p(x∣η)=h(x)exp(T(x)Tη−A(η)) 其中, 、 T ( x ) 、 h ( x ) 、T(x)、h(x) 、T(x)、h(x
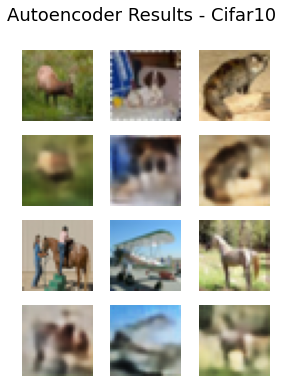
【信号处理】基于变分自编码器(VAE)的图片典型增强方法实现
关于 深度学习中,经常面临图片数据量较小的问题,此时,对数据进行增强,显得比较重要。传统的图片增强方法包括剪切,增加噪声,改变对比度等等方法,但是,对于后端任务的性能提升有限。所以,变分自编码器被用来实现深度数据增强。 变分自编码器的主要缺点在于生成图像过于平滑和模糊,图像细节重建不足。 常见的图像增强方法:https://www.tensorflow.org/tutorials/image

variational approximation posterior distribution (变分近似)
变分近似是一种数学方法,用来近似复杂系统中难以精确计算的概率分布。在统计和机器学习领域,我们经常会遇到需要估计后验分布的情况,后验分布是指在给定观测数据后,我们对未知量(比如模型的参数)的不确定性的概率描述。 想象你有一堆数据,你想根据这些数据来猜测某些你不知道的量(比如一个事件发生的概率)。在贝叶斯统计中,你会用到后验分布来表达你的猜测。但问题在于,对于很多复杂的模型,这个后验分布非常难以直接

EI级!高创新原创未发表!VMD-TCN-BiGRU-MATT变分模态分解卷积神经网络双向门控循环单元融合多头注意力机制多变量时间序列预测(Matlab)
EI级!高创新原创未发表!VMD-TCN-BiGRU-MATT变分模态分解卷积神经网络双向门控循环单元融合多头注意力机制多变量时间序列预测(Matlab) 目录 EI级!高创新原创未发表!VMD-TCN-BiGRU-MATT变分模态分解卷积神经网络双向门控循环单元融合多头注意力机制多变量时间序列预测(Matlab)预测效果基本介绍程序设计参考资料 预测效果

多维时序 | Matlab实现VMD-CNN-GRU变分模态分解结合卷积神经网络门控循环单元多变量时间序列预测
多维时序 | Matlab实现VMD-CNN-GRU变分模态分解结合卷积神经网络门控循环单元多变量时间序列预测 目录 多维时序 | Matlab实现VMD-CNN-GRU变分模态分解结合卷积神经网络门控循环单元多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现VMD-CNN-GRU变分模态分解结合卷积神经网络门控

多维时序 | Matlab实现VMD-CNN-BiLSTM变分模态分解结合卷积神经网络结合双向长短期记忆神经网络多变量时间序列预测
多维时序 | Matlab实现VMD-CNN-BiLSTM变分模态分解结合卷积神经网络结合双向长短期记忆神经网络多变量时间序列预测 目录 多维时序 | Matlab实现VMD-CNN-BiLSTM变分模态分解结合卷积神经网络结合双向长短期记忆神经网络多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现VMD-CNN

多维时序 | Matlab实现VMD-CNN-LSTM变分模态分解结合卷积神经网络结合长短期记忆神经网络多变量时间序列预测
多维时序 | Matlab实现VMD-CNN-LSTM变分模态分解结合卷积神经网络结合长短期记忆神经网络多变量时间序列预测 目录 多维时序 | Matlab实现VMD-CNN-LSTM变分模态分解结合卷积神经网络结合长短期记忆神经网络多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现VMD-CNN-LSTM变分模