前程无忧专题
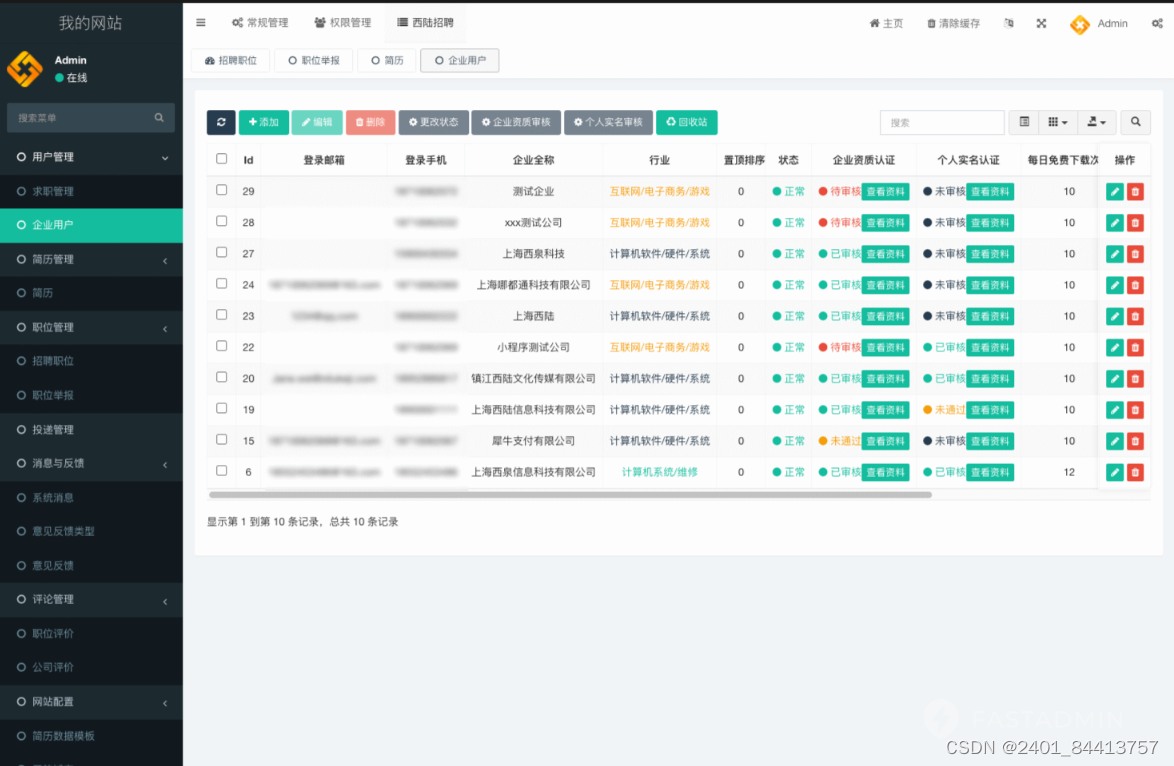
【全开源】同城招聘SAAS信息前程无忧直聘达小程序
招聘SAAS:数字化转型中的招聘新助力 基于ThinkPHP和原生微信小程序开发的招聘平台系统,包含微信小程序求职者端、微信小程序企业招聘端、PC企业招聘端、PC管理平台端 🌟 一、招聘SAAS简介 在人力资源领域,数字化转型已成为不可逆转的趋势。招聘SAAS(软件即服务)作为一种新型的招聘解决方案,正以其高效、便捷的特性,助力企业优化招聘流程,提升招聘效率。 🎯 二、招聘SAAS的
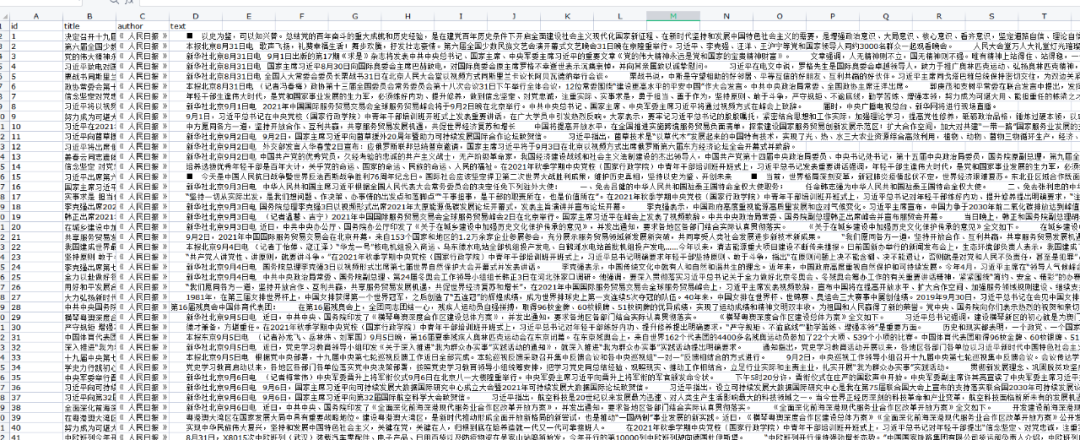
【从零开始学爬虫】采集前程无忧招聘数据
l 采集网站 【场景描述】采集前程无忧招聘信息。 【源网站介绍】 前程无忧(NASDAQ:JOBS)是中国具有广泛影响力的人力资源服务供应商,在美国上市的中国人力资源服务企业,创立了网站+猎头+RPO+校园招聘+管理软件的全方位招聘方案。 【使用工具】前嗅ForeSpider数据采集系统,点击下方链接可免费下载 ForeSpider免费版本下载地址 【入口网址】https://sear
阳光电源社招前程无忧智鼎题库及远程包过助攻需要重点考察什么?
阳光电源社招前程无忧智鼎题库及远程包过助攻需要重点考察什么? 结合长期服务大型国有企业校招工作的经验,我们总结出阳光电源社招笔试的典型模式:行政职业能力测试+企业应知应会测试+心理测评,综合考察候选人的政治素养、文化素养、思维素养、职业素养和心理素养。 一、能力 20分钟 核心能力 通过率60% 本部分实际是思维素养 使用的是IQCAT思维能力智鼎测评题库,题目分组计算时间,题型涉及数字推理

re.findall-Python字符过滤(前程无忧薪资字符过滤)
import rere.findall 过滤 万/年 '40-80万/年'if re.findall(r'(.*)\-(.*)\万\/\年', i):s = re.findall(r'(.*)\-(.*)\万\/\年', i)[0]print(s)print(s[0])('40', '80')40 前程无忧薪资字符过滤 abb = ['1-1.6万', '1.5-2万', '2-

Python3.6爬虫集合 xpath bs4 re 爬51job前程无忧招聘信息 豆瓣音乐等等
总结一下这两天自己写的爬虫,之前一直用框架爬虫,感觉有必要熟练最基础的没有框架爬虫才能让我更好理解框架,代码在链接内,代码中都有详细的注释 1. 发送邮件,这里选择发送网页邮件,其他邮件发送可以看廖雪峰老师的教程 * 邮件协议为SMTP,端口为25 * 需要模块 email(构造邮件) smtplib(发送邮件) * 代码传送门 * 无具体

【Python爬虫】招聘网站实战合集第一弹:爬取前程无忧
爬个妹子总是没过,没办法,咱们来爬爬招聘网站吧~ 本次以前程无忧为例,看看Python的工资如何。 这是今天的重点 1、爬虫的基本流程2、re正则表达式模块的简单使用3、requests模块的使用4、保存csv 使用的软件 python 3.8pycharm 2021专业版pycharm 社区版 (免费) 没有主题专业版 (需要激活码) 使用的模块 reques
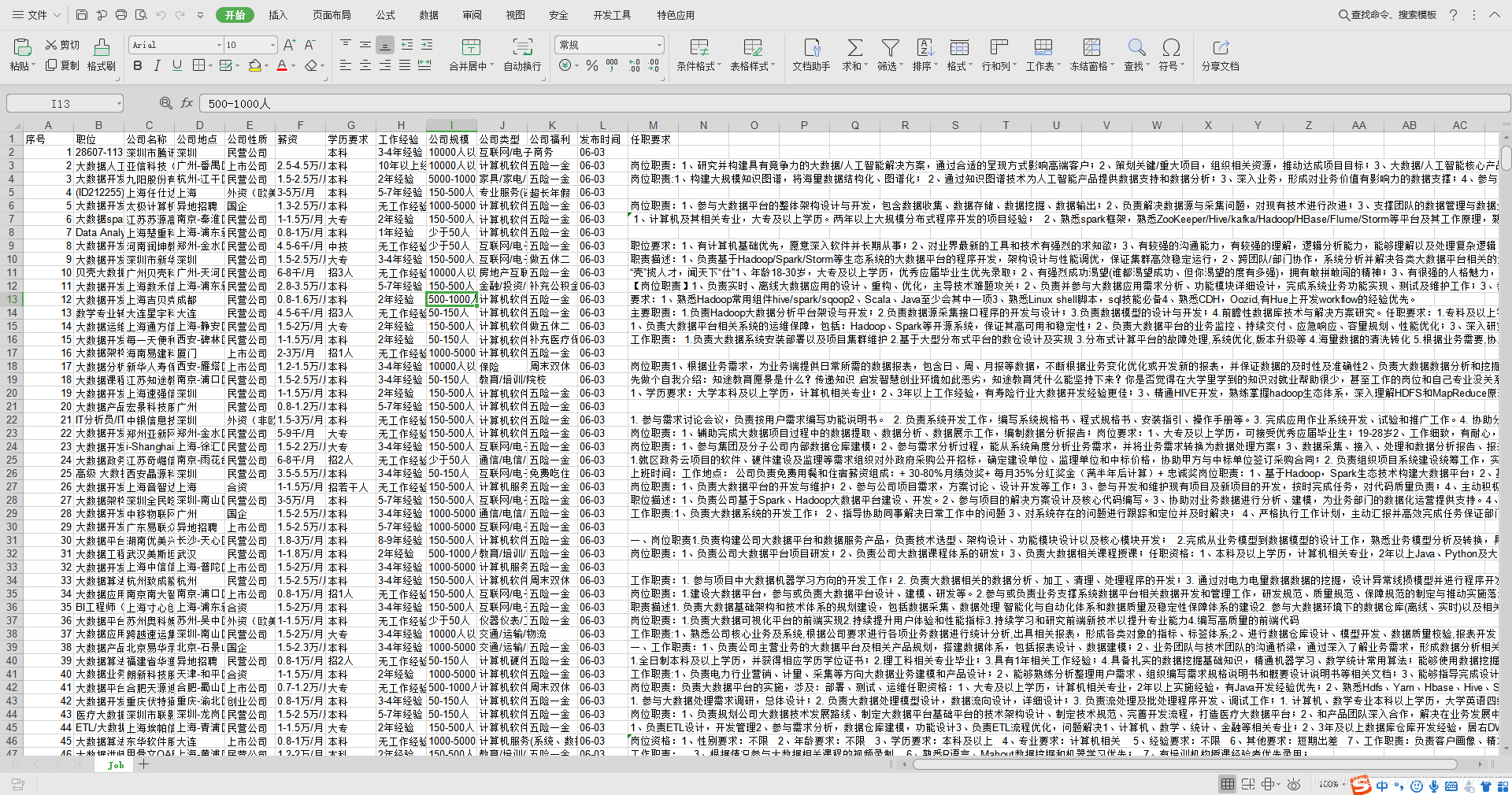
Python爬取前程无忧职位信息,保存成Excel文件
爬取网页的方式:re url="https://search.51job.com/list/000000,000000,0000,00,9,99,%25E5%25A4%25A7%25E6%2595%25B0%25E6%258D%25AE,2,1.html"a = urllib.request.urlopen(url)html = a.read().decode('gbk') reg =

通过scrapy爬取前程无忧招聘数据
创建项目: scrapy startproject ScrapyDemocd ScrapyDemoscrapy genspider bigqcwy msearch.51job.com items.py文件添加爬取信息: class ScrapydemoItem(scrapy.Item):# define the fields for your item here like:# name
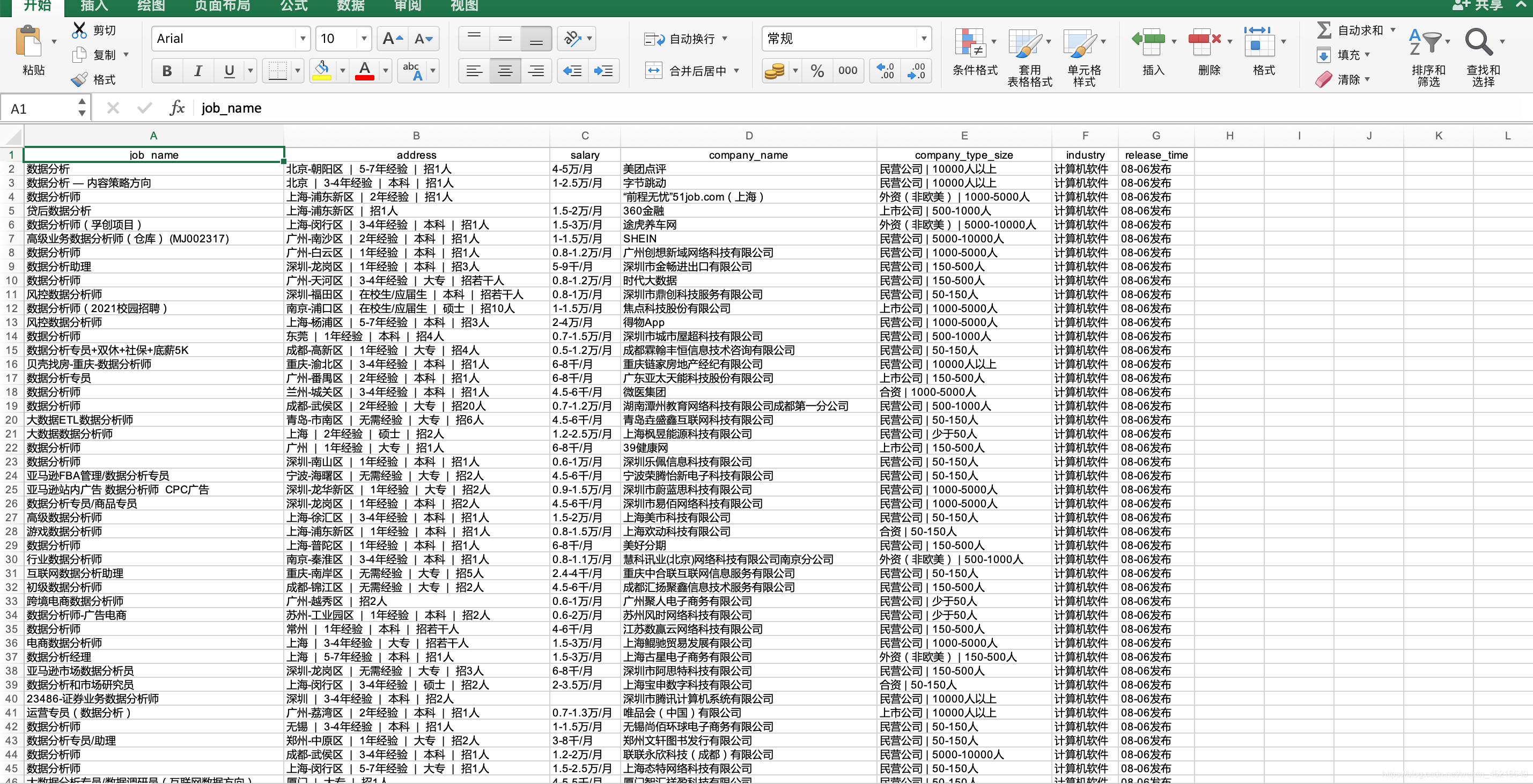
最新 Python3 爬取前程无忧招聘网 mysql和excel 保存数据
Python 爬虫目录 1、最新 Python3 爬取前程无忧招聘网 lxml+xpath 2、Python3 Mysql保存爬取的数据 正则 3、Python3 用requests 库 和 bs4 库 最新爬豆瓣电影Top250 4、Python Scrapy 爬取 前程无忧招聘网 5、Python
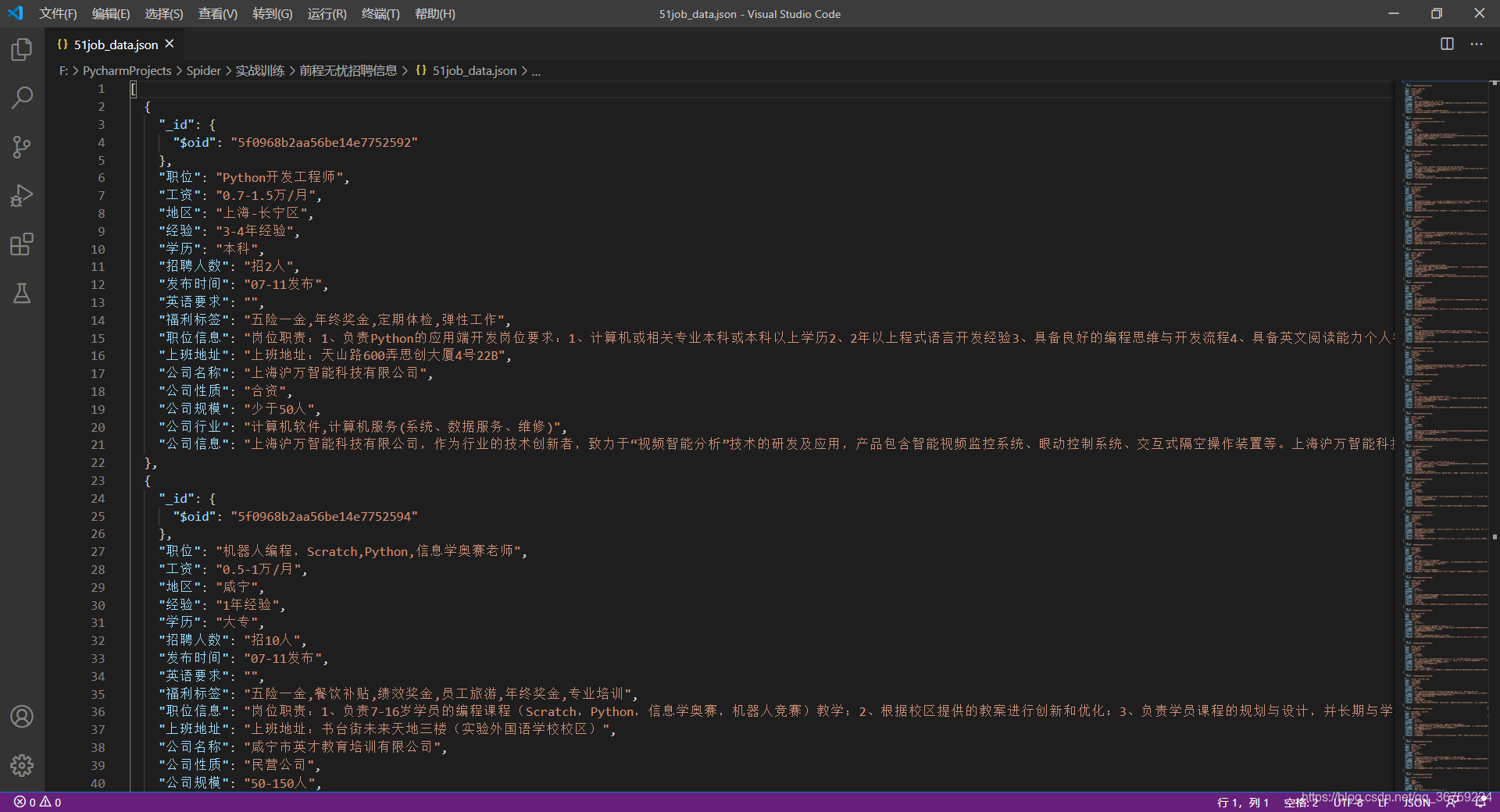
Python3 爬虫实战 — 前程无忧招聘信息爬取 + 数据可视化
爬取时间:2020-07-11(2020年10月测试,增加了反爬,此代码已失效!!!)实现目标:根据用户输入的关键字爬取相关职位信息存入 MongoDB,读取数据进行可视化展示。涉及知识:请求库 requests、Xpath 语法、数据库 MongoDB、数据处理 Numpy、Pandas、数据可视化 Matplotlib。完整代码:https://github.com/TRHX/Python

scrapy爬虫进阶案例--爬取前程无忧招聘信息
上一次我们进行了scrapy的入门案例讲解,相信大家对此也有了一定的了解,详见新手入门的Scrapy爬虫操作–超详细案例带你入门。接下来我们再来一个案例来对scrapy操作进行巩固。 一、爬取的网站 这里我选择的是杭州数据分析的岗位,网址如下:https://search.51job.com/list/080200,000000,0000,32,9,99,%25E6%2595%25B0%25E
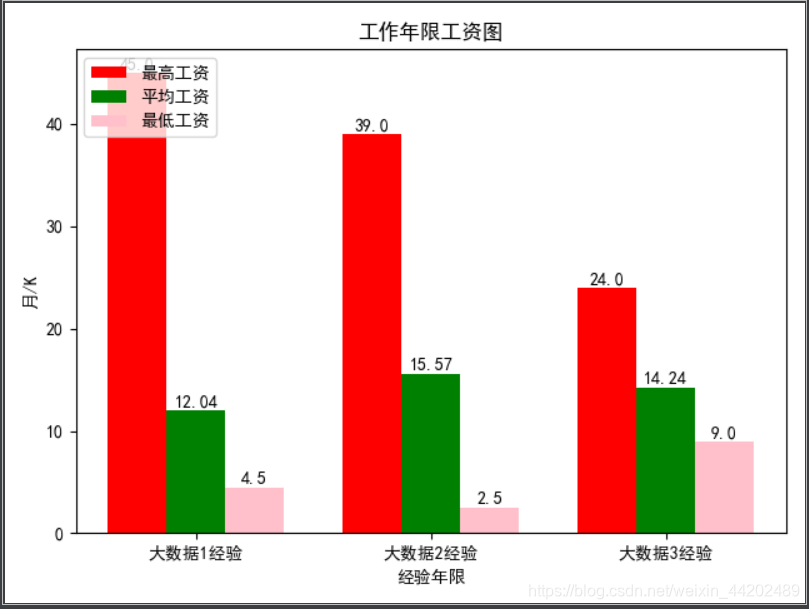
python爬取前程无忧招聘用Hive做数据分析Sqoop存储到Mysql并可视化
一、导出数据 导出为zh_all2.txt文件 二、上传数据 三、使用Flume传入HDFS (1)编写conf文件 在flume的conf目录下新建文件 a1.sources=r1a1.channels=c1a1.sinks=s1a1.sources.r1.type=execa1.sources.r1.command=tail -F /opt/module/flume

Scrapy抓取前程无忧招聘信息(静态页面)
前言,为了了解重庆各区招聘软件测试的情况,需要抓取前程无忧中搜索到的招聘信息,并把信息写到数据库,再分析数据。 1. 创建Scrapy项目: scrapy startproject counter 2. 生成Spider: cd counter scrapy genspider cqtester www.51jo
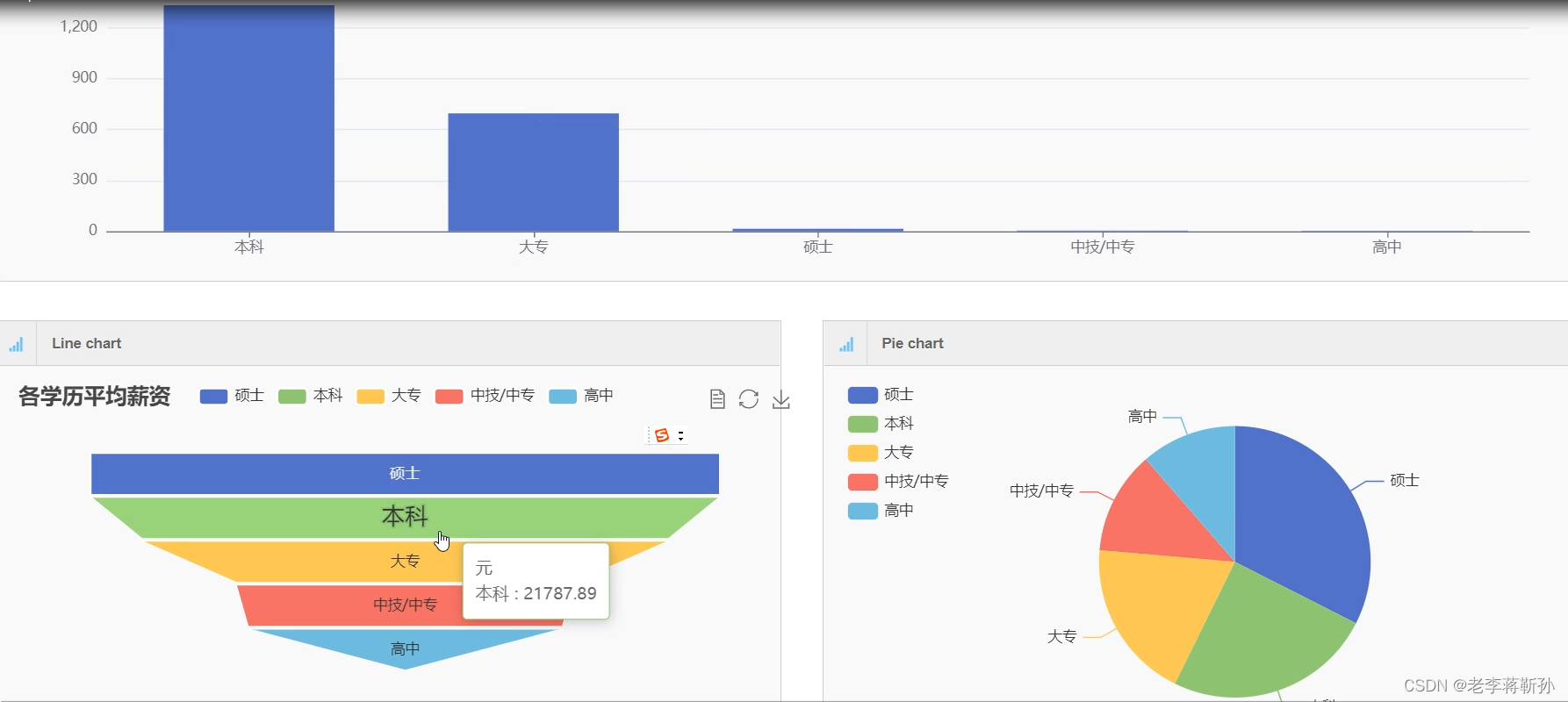
spark+前程无忧
spark+前程无忧,此系统有详细的录屏,下面只是部分截图,需要看完整录屏联系博主 系统开发语言python,框架为django,数据库mysql,分为爬虫和可视化分析

基于Python的前程无忧、51job、智联招聘等招聘网站数据获取及数据分析可视化大全【代码+演示】
需要本项目的可以私信博主,获取,或者文末卡片获取 import pandas as pdimport globimport warningswarnings.filterwarnings("ignore")# 指定目录directory = './data/'# 使用glob来获取所有.xlsx文件excel_files = glob.glob(directory + '*.xls

pyecharts安装和爬取前程无忧招聘网站数据分析(二)
目录 一、安装pyecharts 1. 安装pyecharts 2. 生成方式 (1)生成html文件 (2) 直接生成图片 二、实际操作 1. 生成工作地图 2. 生成全国python平均薪资分布图 当我第一次看见pye

换坑季-51Job前程无忧 Python爬虫
写了个简易的Python爬虫,实现对目的工作的分析。 说明,只用了正则re库进行数据处理,requests进行请求,开了4个简易的函数线程。 url是以下界面的url: 主要实现了以下CSV功能: 全部代码: import requestsimport reimport csvfrom threading import Threaddef req(i):count = 1try:for

Python网络爬虫(一):爬取51job前程无忧网数据并保存至MongoDB数据库
Python网络爬虫(一):爬取51job前程无忧网数据并保存至MongoDB数据库 前言 参考博客: link.Python爬虫(7):多进程抓取拉钩网十万数据: 版本:Python3.7 编辑器:PyCharm 数据库:MongoDB 整体思路: 1.网页解析,查找所需信息的位置 2.开始网页爬取 3.爬取结果存入MongoDB数据库 爬虫 1.网页解析 打开网页后发现共有四大类
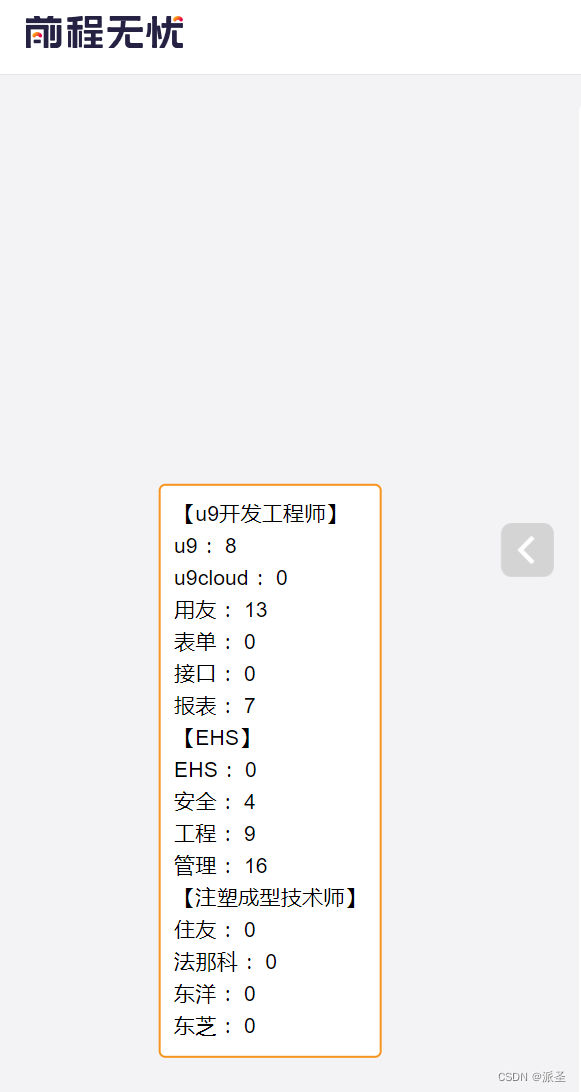
HR的油猴脚本:前程无忧简历关键词统计
介绍 近年来,求职市场变得愈加竞争激烈,雇主和招聘人员需要花费大量的时间来筛选简历,以找到合适的候选人。这个Tampermonkey脚本“HR帮手”为前程无忧(51job)的HR提供了一种强大的工具,帮助他们快速筛选简历。这个脚本不仅可以计算简历中特定关键词的数量,还可以将这些关键词高亮显示,使招聘人员能够更轻松地识别符合要求的候选人。 脚本功能 功能概述 计算关键词数量: 脚本会在51j

python爬取前程无忧岗位详信息
这是之前写的一个爬虫,现在分享一下。这次主要是使用BeautifulSoup,这个是最简单的一种方法。但是这次使用了lambda匿名函数,该函数是python中的一种表达式,lambda函数格式为:冒号前是参数,冒号的右边为表达式。lambda返回值函数的地址,也就是函数对象。还是一步步分析: 匹配到新的URL地址,然后获取新的URL的地址下的内容。 #设置访问头headers={'User

大数据实训(爬取前程无忧利用hive、sqoop分析)
一、总体要求 利用python编写爬虫程序,从招聘网站上爬取数据,将数据存入到MongoDB数据库中,将存入的数据作一定的数据清洗后做数据分析,最后将分析的结果做数据可视化。 二、环境 hadoop:https://editor.csdn.net/md/?articleId=106674836 hive:链接:https://pan.baidu.com/s/1dBVZN1iOB8Okqv8
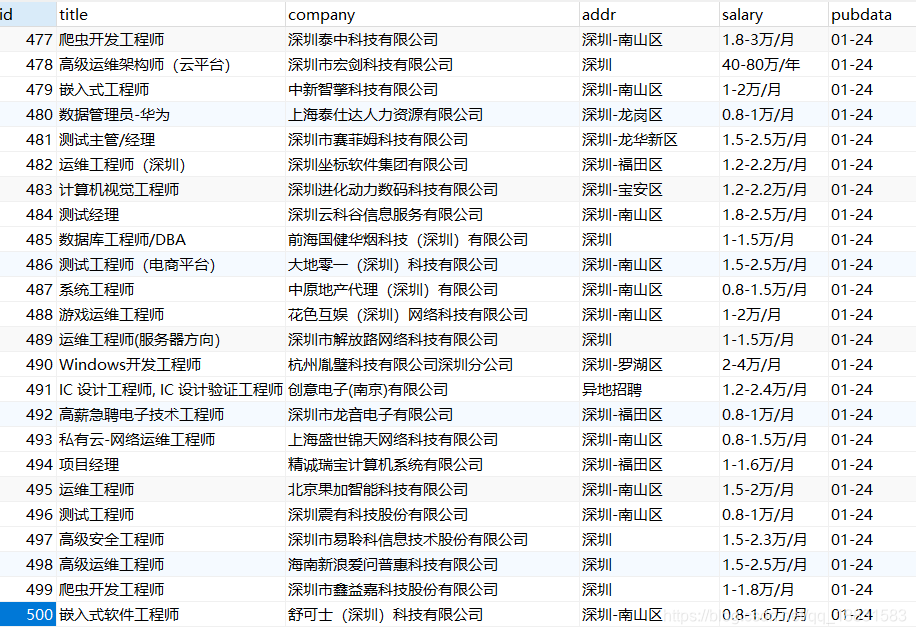
python爬取前程无忧职位信息并保存到数据库
目标: 爬取前程无忧的职位信息,包括职位名、公司名、地址、薪资、发布日期这5个项目(本博客为爬取python、位置为深圳、薪资不限、发布日期不限),并保存到mysql数据库 思想: 1,获取完整数据: 先分析url,找出python筛选出你想要的职位的url,由于每个网页显示的内容为50条,这里我们对url进行格式化,让它循环进行爬取下一页的内容,url如下: url = "ht

抓取前程无忧51job岗位数据,实现数据可视化——心得体会
最近找工作,经常浏览51job,刚好学了python一段时间了,所以有了一个想法:为什么不将我需要的岗位信息给爬出来呢? 在51job网站搜索“数据分析师”,查看源代码,发现每一个招聘公告包含岗位、公司、薪资、地区等信息。所以可以实现如下几个目的: 1.根据关键词抓取招聘信息; 2.连接mysql,创建表格,并插入数据; 3.初步清洗数据,实现可视化 一、网页抓取函数 https:

入门小远学爬虫(二)(一)简单GET型网页爬虫实战——“前程无忧”爬虫岗位信息的爬取之网页分析
文章目录 前程无忧网站Step1:找准自己需要什么东西Step2:进行网页分析Step3:利用XPath Helper插件写出所需信息的大致Xpath路径小结 前程无忧网站 小远想知道全国各地的爬虫开发工程师的招聘要求,并进行横向比较和分析。大型招聘网站(比如前程无忧)上的岗位需求都是成百上千条,显然,网上的招聘信息太多,自己点开太过繁琐和复杂,手动完成不现实。 所以, 上爬

使用Python爬取前程无忧上南京地区Python职位以及对应工资
获取原始数据 最近在学习Python,做了一个爬虫程序练练手,前程无忧这个网站页面布局还是挺简单的,适合我这种新手。使用requests+bs4爬取 不多说了,先来看看页面布局吧。 这是前程无忧上的职位列表,看上去还是很清楚的 然后再来看看页面布局,使用Google浏览器打开前程无忧网页,然后按下F12 每一个class为el的div就代表一个招聘信息 然后再来看看div里面是怎么布
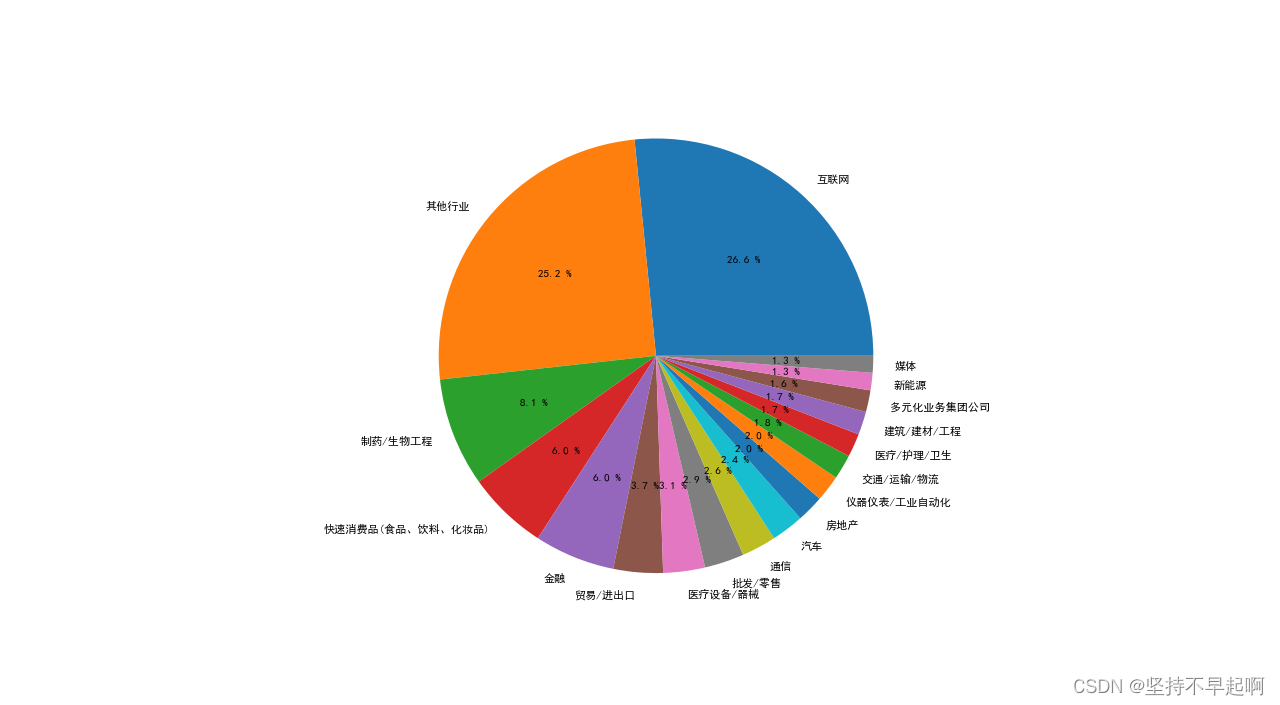
2022.3.25-2022.3.27前程无忧—数据分析求职需求分析
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport warningsfrom scipy.stats import norm,modeimport replt.rcParams['font.sans-serif']=['SimHei'] # 用来设置字体样式以正常显示中文标签plt.rc