本文主要是介绍python爬取前程无忧职位信息并保存到数据库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目标:
爬取前程无忧的职位信息,包括职位名、公司名、地址、薪资、发布日期这5个项目(本博客为爬取python、位置为深圳、薪资不限、发布日期不限),并保存到mysql数据库
思想:
1,获取完整数据:
先分析url,找出python筛选出你想要的职位的url,由于每个网页显示的内容为50条,这里我们对url进行格式化,让它循环进行爬取下一页的内容,url如下:
url = "https://search.51job.com/list/040000,000000,0000,00,9,99,python,2,{}.html".format(i+1)
然后用request进行网页的爬取,不多说,获取数据的函数如下:
def get_data(i):t = Falseheaders = {'User_Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}url = "https://search.51job.com/list/040000,000000,0000,00,9,99,python,2,{}.html".format(i+1)req = request.Request(url,headers=headers)response = request.urlopen(req)if response.getcode() == 200:data = response.read() #读取响应的数据,byte类型data = str(data,encoding='gbk')with open('index.html',mode='w+',encoding='utf-8') as f:f.write(data)t = Truereturn t
2,解析数据
解析获取到的完整数据,使用beautifulsoup,找到原始数据中我们需要的数据的位置,并取出,保存到列表,返回这个列表,函数如下:
def parse_data():with open('index.html', mode='r', encoding='utf-8') as f:html = f.read()bs =BeautifulSoup(html,'html.parser') #使用指定html解析器parserdivs = bs.select('#resultList .el') # #:代表Id, .:代表class或spanresult = [] for div in divs[1:]:title = div.select('.t1')[0].get_text(strip=True)company = div.select('.t2')[0].get_text(strip=True)addr = div.select('.t3')[0].get_text(strip=True)salary = div.select('.t4')[0].get_text(strip=True)pubdata = div.select('.t5')[0].get_text(strip=True)row = {'title': str(title),'company': str(company),'addr': str(addr),'salary': str(salary),'pubdata': str(pubdata)}result.append(row)#print(type(result[1].values()))return result
3,保存到数据库
def sava_to_mysql(data):config = {'host': '127.0.0.1','port': 3306,'user': 'root','password': '','database': 'python_test','charset': 'utf8'}conn = pymysql.connect(**config)cursor = conn.cursor()sql = '''insert into t_job(title, company, addr, salary, pubdata)values (%(title)s,%(company)s,%(addr)s,%(salary)s,%(pubdata)s)'''cursor.executemany(sql,data) #excutemany 自动进行循环,遍历列表中的数据conn.commit()cursor.close()conn.close()
4,新建数据库
先创建数据库,如何运行python代码
数据库语句如下:
create table t_job(id int primary key auto_increment,title varchar(200),company varchar(200),addr varchar(200),salary varchar(200),pubdata varchar(200) ) engine=Innodb charset utf8;
5,完整python代码如下
from urllib import request
from bs4 import BeautifulSoup
import re
import pymysql
import time#获取数据
def get_data(i):t = Falseheaders = {'User_Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'}url = "https://search.51job.com/list/040000,000000,0000,00,9,99,python,2,{}.html".format(i+1)req = request.Request(url,headers=headers)response = request.urlopen(req)if response.getcode() == 200:data = response.read() #读取响应的数据,byte类型data = str(data,encoding='gbk')with open('index.html',mode='w+',encoding='utf-8') as f:f.write(data)t = Truereturn t#print(data)
#解析数据,提取数据def parse_data():with open('index.html', mode='r', encoding='utf-8') as f:html = f.read()bs =BeautifulSoup(html,'html.parser') #使用指定html解析器parserdivs = bs.select('#resultList .el') # #:代表Id, .:代表class或spanresult = [] for div in divs[1:]:title = div.select('.t1')[0].get_text(strip=True)company = div.select('.t2')[0].get_text(strip=True)addr = div.select('.t3')[0].get_text(strip=True)salary = div.select('.t4')[0].get_text(strip=True)pubdata = div.select('.t5')[0].get_text(strip=True)row = {'title': str(title),'company': str(company),'addr': str(addr),'salary': str(salary),'pubdata': str(pubdata)}result.append(row)#print(type(result[1].values()))return result#存储数据到mysql
def sava_to_mysql(data):config = {'host': '127.0.0.1','port': 3306,'user': 'root','password': '','database': 'python_test','charset': 'utf8'}conn = pymysql.connect(**config)cursor = conn.cursor()sql = '''insert into t_job(title, company, addr, salary, pubdata)values (%(title)s,%(company)s,%(addr)s,%(salary)s,%(pubdata)s)'''cursor.executemany(sql,data) #excutemany 自动进行循环,遍历列表中的数据conn.commit()cursor.close()conn.close()if __name__ == '__main__':for i in range(10):get_data(i+1)print(get_data(i+1))if get_data(i+1) == True:sava_to_mysql(parse_data())
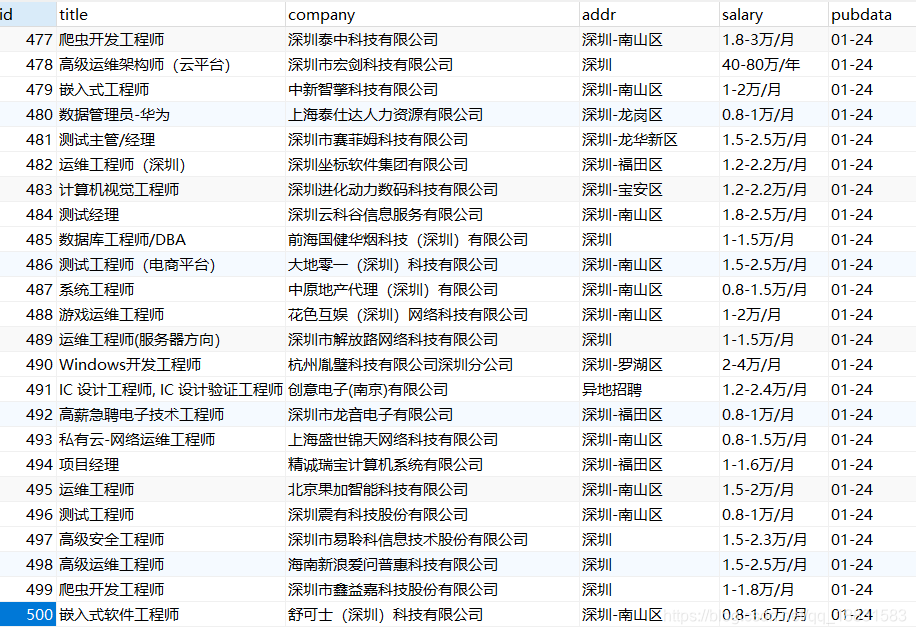
6,运行之后查看数据库
如下,由于我们循环了10次,而每个网页只有50条数据,所以数据库中只有500条数据
这篇关于python爬取前程无忧职位信息并保存到数据库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







