爬取专题

0基础学习爬虫系列:网页内容爬取
1.背景 今天我们来实现,监控网站最新数据爬虫。 在信息爆炸的年代,能够有一个爬虫帮你,将你感兴趣的最新消息推送给你,能够帮你节约非常多时间,同时确保不会miss重要信息。 爬虫应用场景: 应用场景主要功能数据来源示例使用目的搜索引擎优化 (SEO)分析关键词密度、外部链接质量等网站元数据、链接提升网站在搜索引擎中的排名市场研究收集竞品信息、价格比较电商网站、行业报告制定更有效的市场策略舆情

python网络爬虫(五)——爬取天气预报
1.注册高德天气key 点击高德天气,然后按照开发者文档完成key注册;作为爬虫练习项目之一。从高德地图json数据接口获取天气,可以获取某省的所有城市天气,高德地图的这个接口还能获取县城的天气。其天气查询API服务地址为https://restapi.amap.com/v3/weather/weatherInfo?parameters,若要获取某城市的天气推荐 2.安装MongoDB

【python】—— Python爬虫实战:爬取珠海市2011-2023年天气数据并保存为CSV文件
目录 目标 准备工作 爬取数据的开始时间和结束时间 爬取数据并解析 将数据转换为DataFrame并保存为CSV文件 本文将介绍如何使用Python编写一个简单的爬虫程序,以爬取珠海市2011年至2023年的天气数据,并将这些数据保存为CSV文件。我们将涉及到以下知识点: 使用requests库发送HTTP请求使用lxml库解析HTML文档使用dateti

scrapy 设置爬取深度 (七)
通过在settings.py中设置DEPTH_LIMIT的值可以限制爬取深度,这个深度是与start_urls中定义url的相对值。也就是相对url的深度。例如定义url为:http://www.domz.com/game/,DEPTH_LIMIT=1那么限制爬取的只能是此url下一级的网页。深度大于设置值的将被ignore。 如图:

scrapy自动多网页爬取CrawlSpider类(五)
一.目的。 自动多网页爬取,这里引出CrawlSpider类,使用更简单方式实现自动爬取。 二.热身。 1.CrawlSpider (1)概念与作用: 它是Spider的派生类,首先在说下Spider,它是所有爬虫的基类,对于它的设计原则是只爬取start_url列表中的网页,而从爬取的网页中获取link并继续爬取的工作CrawlSpider类更适合。


python爬取网页接口数据,以yearning为例
模拟登陆获取token,传token到对应的接口获取数据,下载到csv里面 import getpassimport osimport requestsimport timeimport csvfrom datetime import datetimeclass Yearning:def __init__(self):self.session = requests.Session()
防御网站数据爬取:策略与实践
随着互联网的发展,数据成为企业最宝贵的资产之一。然而,这种宝贵的数据也吸引着不法分子的目光,利用自动化工具(即爬虫)非法抓取网站上的数据,给企业和个人带来了严重的安全隐患。为了保护网站免受爬虫侵害,我们需要实施一系列技术和策略性的防御措施。 1. 了解爬虫的工作原理 爬虫通常按照一定的规则自动浏览互联网上的网页,抓取信息。它们通过解析HTML页面,提取所需数据,并可能进一步跟踪页面上的链接,继

一篇文章教会你用Python爬取淘宝评论数据【淘宝商品评论数据接口参数】
【一、项目简介】 本文主要目标是采集淘宝的评价,找出客户所需要的功能。统计客户评价上面夸哪个功能多,比如防水,容量大,好看等等。 【二 ·淘宝/天猫获得淘宝商品评论 API 返回值】 item_review-获得淘宝商品评论 taobao.item_review 公共参数 名称类型必须描述keyString是调用key(必须以GET方式拼接在URL中)secre

Python爬虫案例四:爬取某个博主的所有文章保存成PDF格式
引入(将图片保存成PDF格式): 测试链接:https://zq.bookan.com.cn/?t=detail&id=21088&ct=1&is=31042341&rid=4658(图书馆图片保存PDF),前提是装库,pip install img2pdf具体步骤:import requests, img2pdf url_list = [ 'http://img1-qn.booka

【综合小项目】—— 爬取数据、数据处理、建立模型训练、自定义数据进行测试
文章目录 一、项目内容二、各步骤的代码实现1、爬取数据2、数据处理3、建立模型训练4、自定义数据进行预测 一、项目内容 1、爬取数据 本次项目的数据是某购物平台中某个产品的优质评价内容和差评内容采用爬虫的 selenium 方法进行爬取数据内容,并将爬取的内容分别存放在两个文本文件中 2、数据处理 分别读取存放数据的两个文本文件分别对优质评价和差评的内容进行分词导入停用词库,对
python 天气与股票的关系--第一部分,爬取数据
起因 电影 点球成金 (Moneyball 2011) 此电影中, 彼得·布兰德(Peter Brand), 就是那个胖子, 他作为一名数据分析专家, 他建立自己的数学公式 (数学模型), 然后用实际的情况, 来验证。 那么,我的一个想法是: 天气情况与股票走势有什么关系。 爬点数据,验证一下。 爬取 上海历史天气数据 2022 + 2023 这里使用的是 scrapy, 很久之前写的,

Python实战项目:天气数据爬取+数据可视化(完整代码)_python爬虫实战
一、选题的背景 随着人们对天气的关注逐渐增加,天气预报数据的获取与可视化成为了当今的热门话题,天气预报我们每天都会关注,天气情况会影响到我们日常的增减衣物、出行安排等。每天的气温、相对湿度、降水量以及风向风速是关注的焦点。通过Python网络爬虫爬取天气预报让我们快速获取和分析大量的天气数据,并通过可视化手段展示其特征和规律。这将有助于人们更好地理解和应用天气数据,从而做出更准确的决策和

《机器学习》【项目】 爬虫爬取数据、数据分词、贝叶斯算法、判断分类 <完整实战详解> (全篇完结)
目录 一、回顾爬虫 1、什么是爬虫 2、实操爬虫 1)寻找标签位置 2)爬取苏某某购产品好评数据 运行代码: 3)爬取差评内容 二、数据分词 1、将获取到的好评和差评数据进行初步分词 1)初步分词 2)内容如下: 2、导入停用词词库 1)导入停用词库后对上述词组进行处理 2)得到除去了停用词的词组 三、词向量转化 1、建立训练集、测试集数据 运行结果为: 2、导

爬取数据时,如何避免违法问题
目录 如何判断一个网站是否有明确禁止爬取数据? 如何处理爬取到的个人隐私数据以符合数据保护法规? 在爬取数据时,如何避免给目标网站带来过多的流量压力? 思维导图 在爬取数据时,避免违法问题的关键在于确保遵守相关法律法规、网站的服务条款以及尊重数据的版权和隐私权。以下是一些具体的法律合规要点: 合法目的:确保数据爬取的目的是合法的,不应用于实质性替代被爬网站点提供的产品或服务。

Python3爬取淘宝商品列表信息(免登录)
概述 结果展示系统环境配置安装依赖代码示例 1.爬取结果展示 2.系统环境配置 mac系统 需要打开safari浏览器的远程自动化开关,如下: windows系统 安装chrome浏览器 3.创建虚拟环境及安装相关依赖 当前使用的python版本为3.12.5,python3以上的应该都没问题 python -m venv py3_env # 在当前路径下
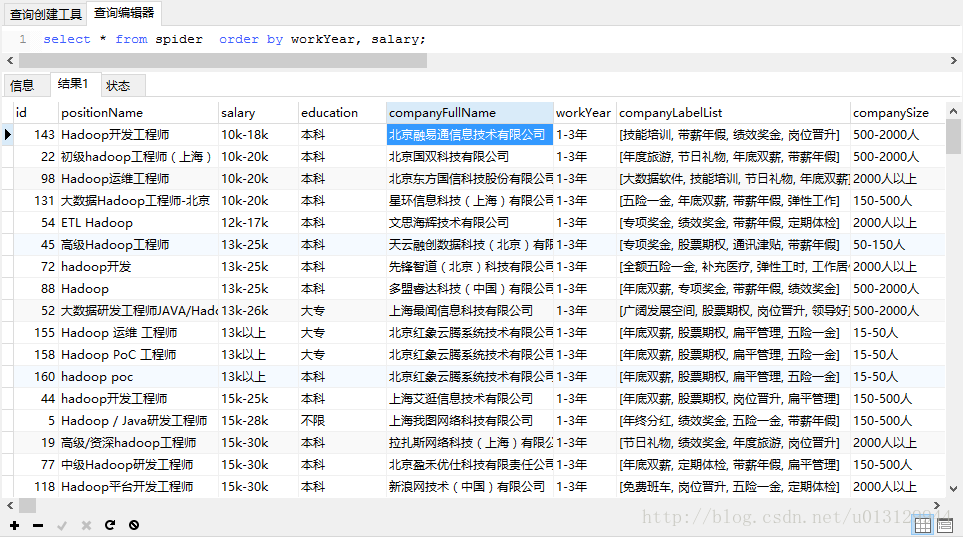
python爬取拉勾网数据保存到mysql数据库
环境:python3 相关包:requests , json , pymysql 思路:1.通过chrome F12找到拉钩请求接口,分析request的各项参数 2.模拟浏览器请求拉钩接口 3.默认返回的json不是标准格式 , 对返回的json数据进行处理转换为标准格式 4.利用pymysql模块进行db操作 #coding:utf-8import randomimpor
关于爬虫爬取图片被防盗链的解决
由于一些不可描述的原因,在使用jsoup爬取图片时被防盗链了。 解决办法是 URL url = new URL("");// 获得连接URLConnection connection = url.openConnection();connection.setRequestProperty("Referer", "http://www.xxx.com"); 因为一些网站在解决盗链问题时是根据R

真话有危险,测评需谨慎!一个家最大的内耗:谁都在抱怨,没人肯改变——早读(逆天打工人爬取热门微信文章解读)
现在都这么完了吗? 引言Python 代码第一篇 洞见 一个家最大的内耗:谁都在抱怨,没人肯改变第二篇 故事风云录结尾 引言 慢慢调整时间 一是现在有点忙 做那个传播声音的研究实验实在是有点没有头绪 没有头绪的事情你就不知道怎么安排时间 也就不知道做什么大概需要多久才合适 当然摸Y也就是一种迷茫的不确定的状态 我在慢慢调整 主要晚上回去老是偷懒 上班的时候也没有合理的规划
![[Python]使用Scrapy爬虫框架简单爬取图片并保存本地](https://img-blog.csdn.net/20160911232144257)
[Python]使用Scrapy爬虫框架简单爬取图片并保存本地
初学Scrapy,实现爬取网络图片并保存本地功能 一、先看最终效果 保存在F:\pics文件夹下 二、安装scrapy 1、python的安装就不说了,我用的python2.7,执行命令pip install scrapy,或者使用easy_install 命令都可以 2、可能会报如下错误 ****************************************

Python 爬虫爬取豆瓣电影列表信息,爬虫的原理,应用领域介绍学习
1. 什么是Python 爬虫 定义:爬虫是一种自动化程序,能够遍历互联网上的各个网页,并根据预设的规则和算法来解析和收集感兴趣的信息。这些信息可以包括网页的文本内容、图片、链接、视频等。 功能:爬虫可以自动化执行重复、繁琐的任务,如定时抓取和更新网站上的信息、自动化监测网站的性能和稳定性、自动化测试网站功能等,从而提高工作效率和质量。 2.爬取原理 选择起始网页:爬虫首先选择