vae专题

基于VAE和流模型的AIGC技术
哇哦,VAE(变分自编码器)和流模型在AI生成内容(AIGC)领域可真是大放异彩呢!🚀🌟 它们就像魔法师一样,能够创造出各种各样、高质量的数据,从图像到音频,再到文本,简直无所不能!🎨🎶📚 来,让我们用更轻松活泼的方式,探索一下VAE和流模型的奇妙世界吧! 🌈 VAE:数据表示的魔法师 🌈 设计哲学:VAE的目标是学习输入数据的有效表示,这样它就能像变魔术一样重构输入数据。和标

深度学习-生成模型:Generation(Tranform Vector To Object with RNN)【PixelRNN、VAE(变分自编码器)、GAN(生成对抗网络)】
深度学习-生成模型:Generation(Tranform Vector To Object with RNN)【PixelRNN、VAE(变分自编码器)、GAN(生成对抗网络)】 一、Generator的分类二、Native Generator (AutoEncoder's Decoder)三、PixelRNN1、生成句子序列2、生成图片3、生成音频:WaveNet4、生成视频:Video

变分自编码器(Variational Autoencoder, VAE):深入理解与应用
变分自编码器(Variational Autoencoder, VAE):深入理解与应用 在深度学习的广阔领域中,生成模型一直是研究的热点之一。其中,VAE(变分自编码器)作为AE(自编码器)的一种扩展,以其独特的优势在生成任务中展现了卓越的性能。本文将深入探讨VAE相对于AE的改进之处,并解析这些改进如何提升模型的生成能力和泛化性能。 一、引言 自编码器(Autoencoder, AE

comfyUI使用flux模型报错got promptUsing pytorch attention in VAE,
使用的flux模型如下,应该下载的模型都已经下载好放在正确位置 但是执行之后报错如下 got prompt Using pytorch attention in VAE Using pytorch attention in VAE 然后comfyUI的命令行就强制退出了。 解决方法: 改虚拟内存为系统管理的大小即可

vae vqvae 学习笔记
目录 这个概念讲的不错 VAE+Classifier 入门例子 这个概念讲的不错 为什么vae效果不好,但vae+diffusion效果就好了? 综上,可以理解为VQ-VAE或者是VQ-GAN都提供了一个有效的图片表征方法,即通过一个压缩后的latent feature就能够在RGB空间上对应一张图。扩散模型中,DDPM已经证明了通过大量的算力资源训练一个diffusio

Autoencoder(AE)、Variational Autoencoder(VAE)和Diffusion Models(DM)了解
Autoencoder (AE) 工作原理: Autoencoder就像一个数据压缩机器。它由两部分组成: 编码器:将输入数据压缩成一个小小的代码。解码器:将这个小代码还原成尽可能接近原始输入的数据。 优点和应用: 简单易懂:用于学习数据的特征和去除噪声。应用场景:例如可以用来缩小图像的大小但保留关键特征,或者去除文本数据中的错误。 挑战: 数据损坏:如果输入数据太乱,编码器可能无法有

生成模型的两大代表:VAE和GAN
生成模型 给定数据集,希望生成模型产生与训练集同分布的新样本。对于训练数据服从\(p_{data}(x)\);对于产生样本服从\(p_{model}(x)\)。希望学到一个模型\(p_{model}(x)\)与\(p_{data}(x)\)尽可能接近。 这也是无监督学习中的一个核心问题——密度估计问题。有两种典型的思路: 显式的密度估计:显式得定义并求解分布\(p_{model}(x)\),
【第9章】“基础工作流”怎么用?(图生图/局部重绘/VAE/更多基础工作流)ComfyUI基础入门教程
🎁引言 学到这里,大家是不是会比较纠结,好像还在持续学习新的东西,未来还有多少基础的东西要学习,才能正常使用ComfyUI呢? 这其实需要转变一个心态。 AI绘画还处于一个快速迭代的过程,隔三岔五的就会有很多新技术、新模型出现,ComfyUI目前同样处于一个快速更新的阶段,从更新记录上也可以看到,几乎每一两天都会更新新版本。 同样,生态的各种自定义节点也在持续更新。 所以,不可能有
Autoencorder理解(5):VAE(Variational Auto-Encoder,变分自编码器)
reference: http://blog.csdn.net/jackytintin/article/details/53641885 近年,随着有监督学习的低枝果实被采摘的所剩无几,无监督学习成为了研究热点。VAE(Variational Auto-Encoder,变分自编码器)[1,2] 和 GAN(Generative Adversarial Networks) 等模型,受到越来越多的关

变分自编码器(VAE)与生成对抗网络(GAN)在TensorFlow中实现
变分自编码器(VAE)与生成对抗网络(GAN)是复杂分布上无监督学习最具前景的两类方法。本文中,作者在MNIST上对这两类生成模型的性能进行了对比测试。 本项目总结了使用变分自编码器(Variational Autoencode,VAE)和生成对抗网络(GAN)对给定数据分布进行建模,并且对比了这些模型的性能。你可能会问:我们已经有了数百万张图像,为什么还要从给定数据分布中生成图像呢?正
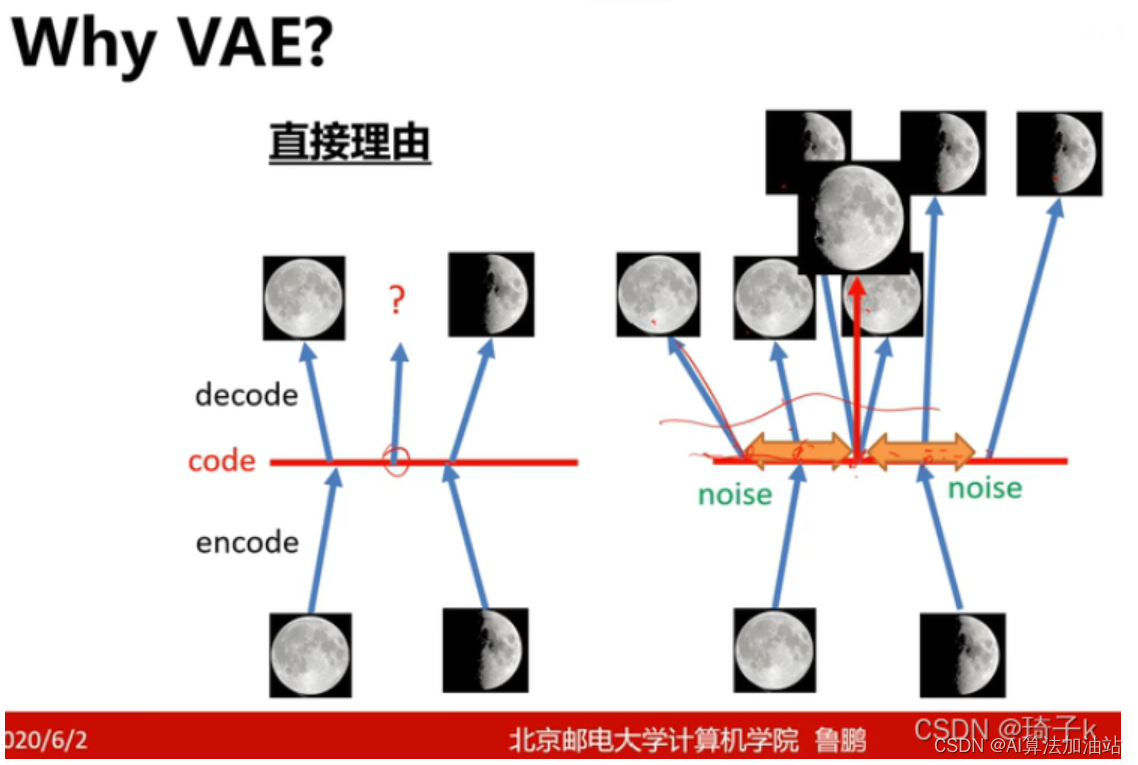
变分自编码器(Variational Autoencoder, VAE)
目录 why VAE: 关于变分自编码器,这篇文章讲的不错 1. 自编码器(Autoencoder)的基础 2. 引入概率图模型 3. 重参数化技巧 4. 损失函数 5. 应用 变分自编码器(Variational Autoencoder, VAE) why VAE: 关于变分自编码器,这篇文章讲的不错 机器学习方法—优雅的模型(一):变分自编码器(VAE

VideoGPT:Video Generation using VQ-VAE and Transformers
1.introduction 对于视频展示,选择哪种模型比较好?基于似然->transformers自回归。在没有空间和时间溶于的降维潜在空间中进行自回归建模是否优于在所有空间和时间像素级别上的建模?选择前者:自然图像和视频包括了大量的空间和时间冗余,这些冗余可以通过学习高分辨率输入的去噪降维编码来消除,例如,空间和时间维度上的4倍降采样会导致64倍的分辨率降低,在潜在空间建模,不是像素空间,可
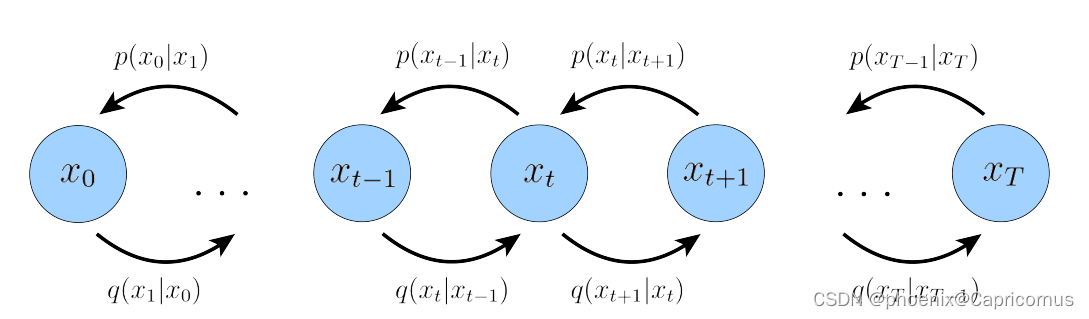
四大生成式模型的比较——GAN、VAE、归一化流和扩散模型
比较四大模型的本质 four modern deep generative models: generative adversarial networks, variational autoencoders, normalizing flows, and diffusion models 待写
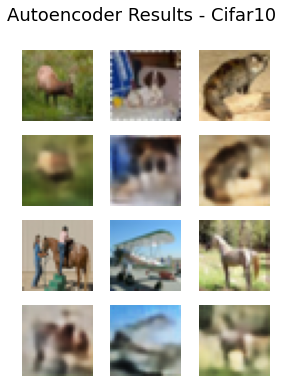
【信号处理】基于变分自编码器(VAE)的图片典型增强方法实现
关于 深度学习中,经常面临图片数据量较小的问题,此时,对数据进行增强,显得比较重要。传统的图片增强方法包括剪切,增加噪声,改变对比度等等方法,但是,对于后端任务的性能提升有限。所以,变分自编码器被用来实现深度数据增强。 变分自编码器的主要缺点在于生成图像过于平滑和模糊,图像细节重建不足。 常见的图像增强方法:https://www.tensorflow.org/tutorials/image
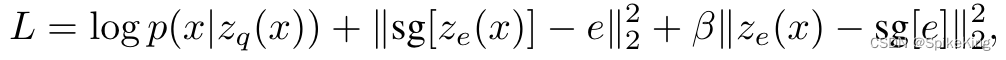
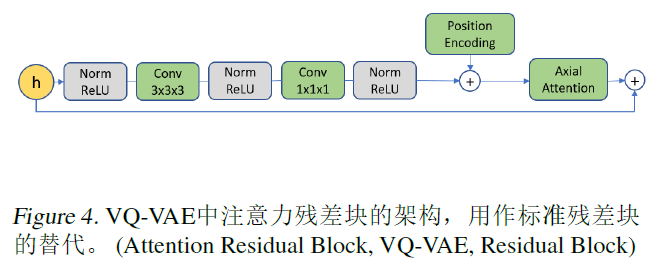
Paper - Neural Discrete Representation Learning (VQ-VAE) 论文简读
欢迎关注我的CSDN:https://spike.blog.csdn.net/ 本文地址:https://spike.blog.csdn.net/article/details/133992971 问题1:训练完成之后,如何判断 VQ-VAE 的效果? 输入一张训练样本之外的图像,经过编码器,与EmbeddingTable计算最近邻的向量,再把向量输入解码器中,获得重构之后的图像,判断图像
顶级会议ICLR论文解读丨语法制导翻译VAE如何回答一代宗师叶问
原创作者:谭婧 美编:陈泓宇 -随堂测验- 俗话说,南拳北腿。 咏春拳作为经典的南派功夫,讲究贴身近击、连消带打与攻守合一。咏春高手的双手知觉灵敏且变化多端,防守时密不透风、滴水不漏,进攻时犹如水银泻地、插缝即入。初看斯文冷静、再看后发先至、以疾如风的速度、爆发出雷霆之力对敌。 叶问VS生成模型。 一代宗师叶问先生笑意慈祥,摆出咏春拳的标志性——问路手, 说道:“咏春,叶问。” 见此状后

顶级会议ICLR论文解读,语法制导翻译VAE如何回答一代宗师叶问
原创作者:谭婧 美编:陈泓宇 -随堂测验- 俗话说,南拳北腿。 咏春拳作为经典的南派功夫,讲究贴身近击、连消带打与攻守合一。咏春高手的双手知觉灵敏且变化多端,防守时密不透风、滴水不漏,进攻时犹如水银泻地、插缝即入。初看斯文冷静、再看后发先至、以疾如风的速度、爆发出雷霆之力对敌。 叶问VS生成模型。 一代宗师叶问先生笑意慈祥,摆出咏春拳的标志性——问路手, 说道:“咏春,叶
图像生成发展起源:从VAE、扩散模型DDPM、DETR到ViT、Swin transformer
前言 2018年我写过一篇博客,叫:《一文读懂目标检测:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD》,该文相当于梳理了2019年之前CV领域的典型视觉模型,比如 2014 R-CNN2015 Fast R-CNN、Faster R-CNN2016 YOLO、SSD2017 Mask R-CNN、YOLOv22018 YOLOv3 随着2019 CenterN

论文Deep Autoencoder的框架(由CNN组成的VAE)
autoencoder可以用于数据压缩、降维,预训练神经网络,生成数据等等。 autoencoder的架构 autoencoder的架构是这样的: 需要分别训练一个Encoder和一个Decoder。 比如,一张数字图片784维,放入Encoder进行压缩,编程code,通常要小于原来的784维; 然后可以将压缩后的code,放入Decoder进行reconsturct,产生和原来相

Tensorflow下VAE(变分自动编码器)在MNIST数据集下的实验
首先简单介绍一下AE和VAE然后在完成代码实践 一、什么是自编码器(Auto-encoder) 自动编码器是一种数据的压缩算法,其中数据的压缩和解压缩函数是数据相关的、有损的、从样本中自动学习的。在大部分提到自动编码器的场合,压缩和解压缩的函数是通过神经网络实现的。 这种算法的大致思想是:将神经网络的隐含层看成是一个编码器和解码器,输入数据经过隐含层的编码和解码,到达输出层时
【PyTorch][chapter 18][李宏毅深度学习]【无监督学习][ VAE]
前言: VAE——Variational Auto-Encoder,变分自编码器,是由 Kingma 等人于 2014 年提出的基于变分贝叶斯(Variational Bayes,VB)推断的生成式网络结构。与传统的自编码器通过数值的方式描述潜在空间不同,它以概率的方式描述对潜在空间的观察,在数据生成方面表现出了巨大的应用价值。VAE一经提出就迅速获得了深度生成模型领域广

AIGC:使用变分自编码器VAE实现MINIST手写数字生成
1 变分自编码器介绍 变分自编码器(Variational Autoencoders,VAE)是一种生成模型,用于学习数据的分布并生成与输入数据相似的新样本。它是一种自编码器(Autoencoder)的扩展,自编码器是一种用于将输入数据压缩为低维表示并再次解压缩的神经网络结构。VAE的独特之处在于它不仅可以生成新样本,还可以学习数据的概率分布。 VAE的关键思想是将输入数据视为从潜在空间中采样

Aloha 机械臂的学习记录4——act:detr_vae.py的代码部分
detr_vae.py的原始代码如下: # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved"""DETR model and criterion classes."""import torchfrom torch import nnfrom torch.autograd import Varia
理解 Stable Diffusion、模型检查点(ckpt)和变分自编码器(VAE)
前言 在探索深度学习和人工智能领域的旅途中,理解Stable Diffusion、模型检查点(ckpt)以及变分自编码器(VAE)之间的关系至关重要。这些组件共同构成了当下一些最先进图像生成系统的基础。本文将为初学者提供一个详细的概述,帮助您理解这些概念以及它们是如何协同工作的。 Stable Diffusion 模型简介 Stable Diffu