tpu专题

AI芯片:Edge TPU(谷歌出品)【在边缘(edge)设备上运行的“专用集成芯片”】【量化操作:Edge TPU使用8 位权重进行计算,而通常使用32位权重。所以我们应该将权重从32位转换为8位】
谷歌Edge TPU的价格不足1000人民币,远低于TPU。实际上,Edge TPU基本上就是机器学习的树莓派,它是一个用TPU在边缘进行推理的设备。 一、云vs边缘 1、边缘运行没有网络延迟 Edge TPU显然是在边缘(edge)运行的,但边缘是什么呢?为什么我们不选择在云上运行所有东西呢? 在云中运行代码意味着使用的CPU、GPU和TPU都是通过浏览器提供的。边缘与云相反,即在

算力巅峰对决,一文读懂CPU、GPU、GPGPU、FPGA、DPU、TPU
通俗理解CPU、GPU、GPGPU、FPGA、DPU、TPU 每个处理器都有它的独特之处和擅长领域,它们共同构成了现代计算的多彩世界。 1. CPU - 中央处理单元 CPU,城市的市中心,精通从基础计算到复杂逻辑决策的各项任务。它高效执行操作指令,轻松应对日常任务如网页浏览和文档编辑。尽管多才多艺,面对超复杂或特定任务

TPU 和 GPU 的区别与相似点
TPU 和 GPU 的区别与相似点 TPU(Tensor Processing Unit) 概述: TPU 是谷歌专门为加速机器学习工作负载而设计的专用芯片。主要用于深度学习模型的训练和推理。 设计目标: 高效执行矩阵运算,特别是用于神经网络中的张量计算。优化了低精度计算(如 bfloat16),在不显著降低精度的情况下提高计算速度。 硬件架构: 采用了大量的矩阵乘法单元,专门用于加

FPGA第二篇,FPGA与CPU GPU APU DSP NPU TPU 之间的关系与区别
简介:首先,FPGA与CPU GPU APU NPU TPU DSP这些不同类型的处理器,可以被统称为"处理器"或者"加速器"。它们在计算机硬件系统中承担着核心的计算和处理任务,可以说是系统的"大脑"和"加速引擎"。这些处理器单元都是计算机系统中的关键组件,它们扮演着不同的角色,为计算机系统提供各种计算和处理能力。 FPGA ~ 第 2 篇 —— FPGA、CPU、GPU、AP

谷歌TPU(Tensor Processing Unit)
谷歌TPU(Tensor Processing Unit) https://cloud.google.com/tpu/docs/intro-to-tpu?hl=zh-cn CPU的工作模式和GPU工作模式的区别 CPU 最大的优点是它们的灵活性。您可以在 CPU 上为许多不同类型的应用加载任何类型的软件。对于每次计算,CPU 从内存加载值,对值执行计算,然后将结果存储回内存中。与计算速度相比,内

CPU、GPU、IPU、NPU、TPU、LPU、MCU、MPU、SOC、DSP、FPGA、ASIC、GPP、ECU、
CPU: 中央处理器(Central Processing Unit)是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。 它的功能主要是解释计算机指令以及处理计算机软件中的数据。 中央处理器主要包括运算器(算术逻辑运算单元,ALU,Arithmetic Logic Unit)和高速缓冲存储器(Cache)及实现它们之间联系的数据(Data)

Extropic.AI:终结GPU/TPU的热力学未来Chip?
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/ Extropic团队最近发布了一份激动人心的消息,宣布他们正在开发一个全
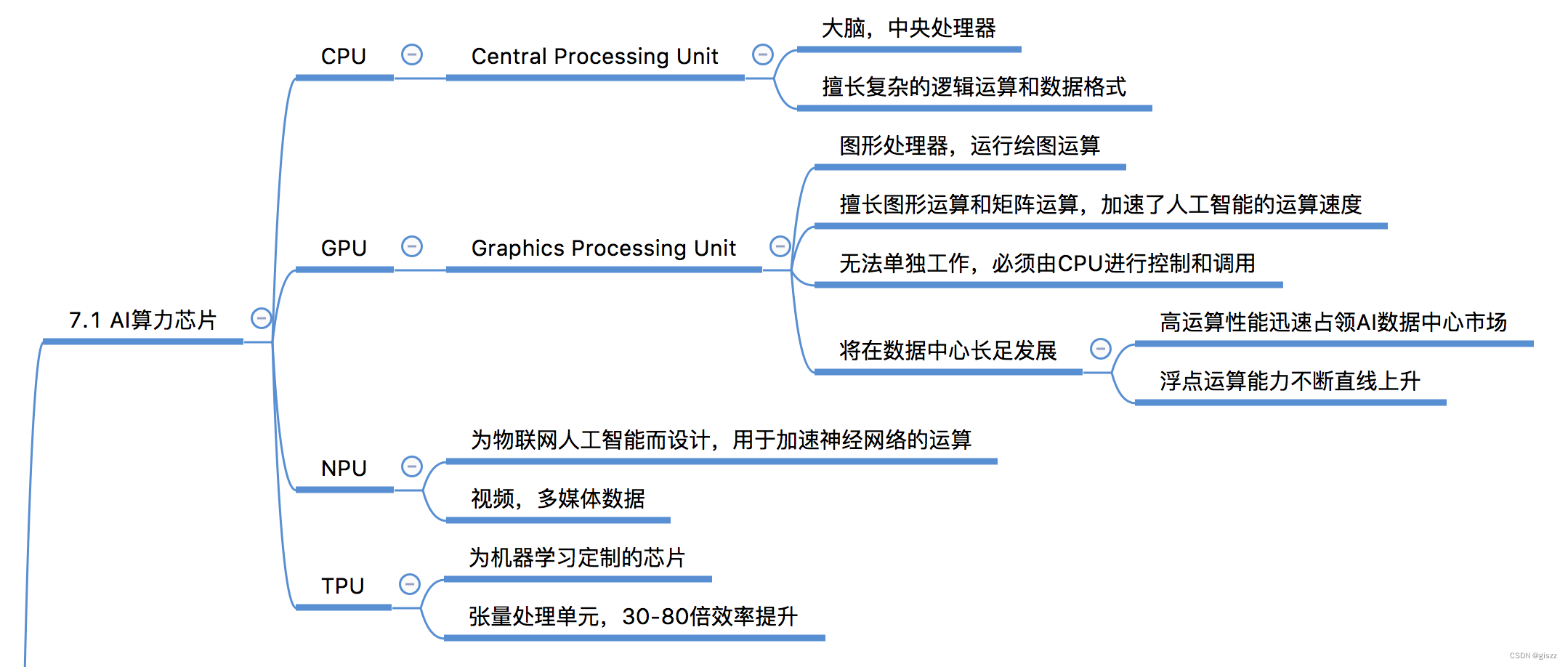
【大厂AI课学习笔记NO.71】AI算力芯片GPU/TPU等
AI算力芯片的发展历程 人工智能(AI)算力芯片的发展历程紧密地跟随着AI技术的发展脚步。从早期的基于传统中央处理器(CPU)的计算,到图形处理器(GPU)的广泛应用,再到专门为AI设计的处理器如神经处理单元(NPU)和张量处理单元(TPU)的出现,AI算力芯片不断演进,以满足日益增长的计算需求。 一、早期基于CPU的计算 在AI技术发展的初期,大部分的计算任务都是由CPU来完成的。

TPU-MLIR的环境搭建和使用
1、开发环境配置 Linux开发环境 一台安装了Ubuntu16.04/18.04/20.04的x86主机,运行内存建议12GB以上下载SophonSDK开发包(v23.03.01) (1)解压缩SDK包 sudo apt-get install p7zipsudo apt-get install p7zip-full7z x Release_<date>-public.zipc
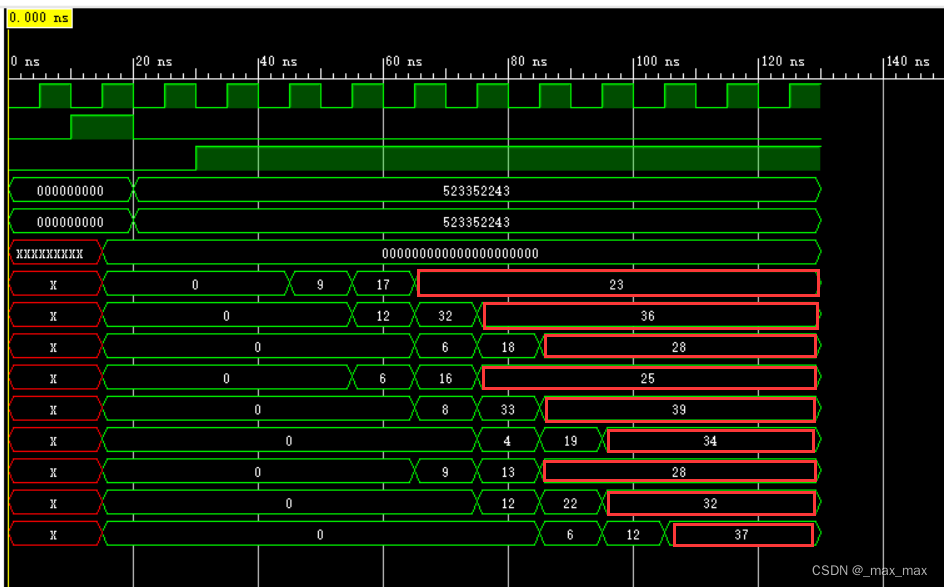
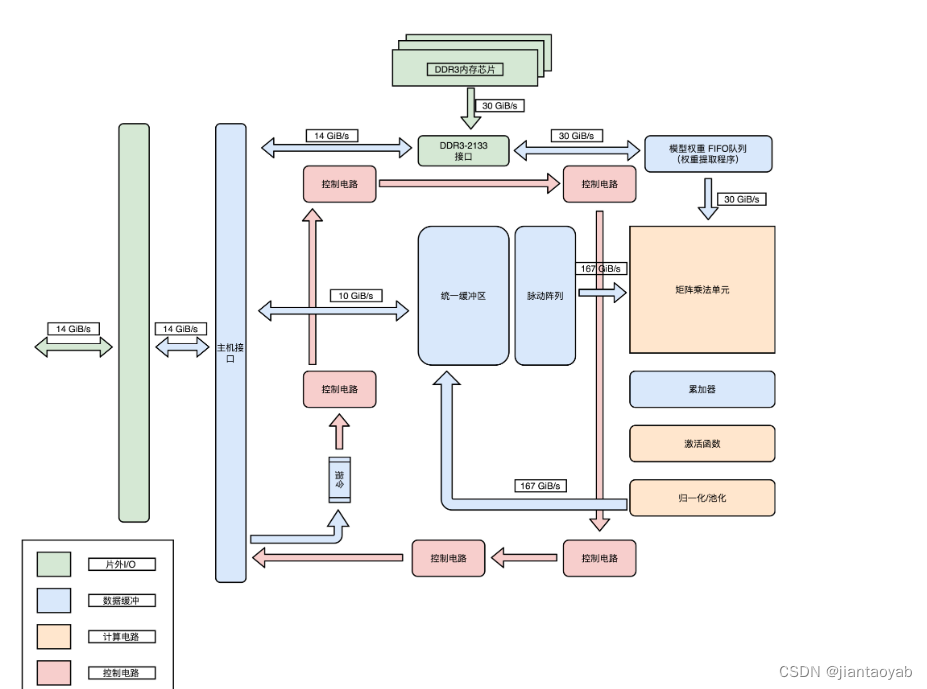
谷歌TPU_脉动阵列实现矩阵乘法(附完整Verilog代码)
谷歌TPU_脉动阵列实现矩阵乘法(附完整Verilog代码) 一、谷歌TPU介绍TPU计算核心的硬件架构 二、矩阵乘法单元硬件架构三、脉动阵列实现矩阵乘法原理四、Verilog实现PE单元顶层文件Testbench文件仿真结果 一、谷歌TPU介绍 谷歌的 TPU(张量处理单元)是一种专门为机器学习工作负载优化的定制硬件加速器。TPU 通过高效地执行矩阵乘法、卷积运算和其他常

PyTorch——利用Accelerate轻松控制多个CPU/GPU/TPU加速计算
PyTorch——利用Accelerate轻松控制多个CPU/GPU/TPU加速计算 前言官方示例单个程序内控制多个CPU/GPU/TPU简单说一下设备环境导包加载数据 FashionMNIST创建一个简单的CNN模型训练函数-只包含训练训练函数-包含训练和验证训练 多个服务器、多个程序间控制多个CPU/GPU/TPU参考链接 前言 CPU?GPU?TPU? 计算设备太多,很混

CoLab设置使用GPU和TPU
##tf2.4.0from tensorflow.python.keras.callbacks import EarlyStoppingfrom tensorflow.python.keras.layers import Embedding, SpatialDropout1D, LSTM, Densefrom tensorflow.python.keras.models import S
8、TPU开发板上编译OPENCV
参考往网上一共有两种方法在ARM上编译opencv: 一种是在PC端使用cmake-gui进行cmake make之后,进行ARM进行编译,这样的前提图像化界面配置一目了然,但是需要配置交叉编译环境 另一种方法是直接在ARM上进行编译,但是似乎python 无法使用cv2.so,主要原因是CMAKE后面的-D参数不正确,然后本人摸索出一个完成的CMAKE 参数列表; 注意问题: 在开发板上

TPU编程竞赛系列|第九届 “互联网+”大学生创新创业大赛产业命题赛道,算能6项命题入选!
近日,第九届中国国际“ 互联a网 +” 大学生创新创业大赛产业命题正式公布,算能提交的六 项企业命题成功入选正式赛题。算能六项赛题主要围绕国产 TPU 芯片的边缘计算系统和 RISC-V 架构处理器来设计,且为参赛选手提供了超强算力开发板等硬件资源,欢迎各大 高校学生 们积极报名参与! 赛事介绍 “ 第九届中国国际“ 互联网+” 大学生创新创业大赛” 是由教育部等12 个中央部

超越GPU:TPU能成为接班人吗?
在计算机的世界里,硬件技术的发展一直在快速推进。今天,我们要谈论的就是一种特殊的处理器:TPU,全称是Tensor Processing Unit。在我们开始深入探讨TPU之前,先了解一下两个重要的芯片技术,FPGA和ASIC。 FPGA和ASIC Altera是一家FPGA巨头 FPGA,全称为现场可编程门阵列,这是一种特殊的处理器,我们可以通过程序代码来控制其中的电路连线,从而实

【2023 CCF 大数据与计算智能大赛】基于TPU平台实现超分辨率重建模型部署 基于Real-ESRGAN的TPU超分模型部署
2023 CCF 大数据与计算智能大赛 《基于TPU平台实现超分辨率重建模型部署》 洋洋很棒 李鹏飞 算法工程师 中国-烟台 2155477673@qq.com 团队简介 本人从事工业、互联网场景传统图像算法及深度学习算法开发、部署工作。其中端侧算法开发及部署工作5年时间。 摘要 本文是《基于TPU平台实现超分辨率重建模型部署》方案中算法方案的说明。本作品算法模型选用的是Rea
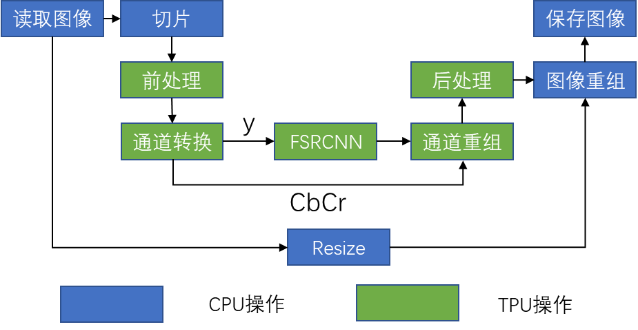
【2023 CCF 大数据与计算智能大赛】基于TPU平台实现超分辨率重建模型部署 基于FSRCNN的TPU平台超分辨率模型部署方案
2023 CCF 大数据与计算智能大赛 基于TPU平台实现超分辨率重建模型部署 基于FSRCNN的TPU平台超分辨率模型部署方案 WELL 刘渝 人工智能 研一 西安交通大学 中国-西安 1461003622@qq.com 史政立 网络空间安全 研一 西安交通大学 中国-西安 1170774291@qq.com 崔琳、张长昊、郭金伟 软件工程等 研一 北京大学软微学

【技术科普】CPU、GPU、TPU、NPU分别是什么?哪个最强?
技术日新月异,物联网、人工智能、深度学习等遍地开花,各类芯片名词CPU,GPU, TPU, NPU层出不穷…它们都是什么?又有着什么千丝万缕的关系和区别? 接下来,统一介绍一下: 01 CPU CPU最早用于计算机的控制单元和运算单元,随着计算机技术的发展,CPU逐渐成为了计算机系统中最重要的部分,担负着整个计算机系统的核心任务。 CPU由多个结构组成,其中包括运算器(ALU, Arith
![[RPI.CM4] Coral TPU Accelerator](https://img-blog.csdnimg.cn/2c92753c99de4869bdbfd742a1881144.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA6bud6buR55qE54Gr5pif5Lq6,size_18,color_FFFFFF,t_70,g_se,x_16)
[RPI.CM4] Coral TPU Accelerator
官网链接:https://coral.ai/products/accelerator/ 1. Edge TPU runtime A. Add Debian package repository to system: echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /

树莓派使用Google Edge TPU加速模型推理(Coral USB Accelerator)
树莓派使用Google Edge TPU加速模型推理(Coral USB Accelerator) 第一部分 树莓派网络环境配置 略 第二部分 安装Edge TPU 库 2.1 安装Edge TPU runtime 增加Debian包仓库 echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable mai

谷歌发布Coral平台,边缘TPU芯片超过树莓派?
Google 在美国时间 3 月 6 日公布推出名为 Coral (beta) 的平台,让大家可以构建具备本地 AI 的物联网终端装置,并同时发表了五款硬件装置。 所谓「本地 AI ( local AI )」或称为「 On-device AI 」,是指不经过云端,而是在本地端装置(边缘装置)上进行 AI 处理, Coral 平台就提供了完整的本地 AI 工具,让开发者将想法从原型化为产品。它

基于算能的国产AI边缘计算盒子,内置强悍TPU | 32TOPS INT8算力
边缘计算盒子 内置强悍TPU | 32TOPS INT8算力 ● 支持浮点运算的TPU平台盒子,支持32TOPS@INT8,16TFLOPS@FP16,2TFLOPS@FP32高算力 ● 单芯片最高支持32路H.264 & H.265的实时解码能力 ● 支持国产算法框架Paddle飞桨,适配Caffe/TensorFlow/MxNet/PyTorch/ONNX等主流深度学习框架 ● 支持
CPU/GPU/TPU/NPU解释
Author:skatexg Time:2022/03/06 一、CPU CPU的结构主要包括运算器(ALU, Arithmetic and Logic Unit)、控制单元(CU, Control Unit)、寄存器(Register)、高速缓存器(Cache)和它们之间通讯的数据、控制及状态的总线。 简单来说就是:计算单元、控制单元和存储单元,架构如下图所示: 从字面上

TPU (灵魂三问 WHAT? WHY? HOW?)
本文长度为 5986 字,45 图表截屏 建议阅读 30 分钟 0引言 从 2018 年 10 月到 2019 年 6 月,NLP 三大模型横空出世,分别是 Google 的 BERT,OpenAI 的 GPT-2 和 CMU 和 Google 联手的 XLNet。 除了模型强大,我们从新闻里看到最多的是就是训练时间长,而且费用惊人的贵。 BERT-large 模型在 16 个 Clou