本文主要是介绍【2023 CCF 大数据与计算智能大赛】基于TPU平台实现超分辨率重建模型部署 基于Real-ESRGAN的TPU超分模型部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
2023 CCF 大数据与计算智能大赛
《基于TPU平台实现超分辨率重建模型部署》
洋洋很棒
李鹏飞
算法工程师
中国-烟台
2155477673@qq.com
团队简介
本人从事工业、互联网场景传统图像算法及深度学习算法开发、部署工作。其中端侧算法开发及部署工作5年时间。
摘要
本文是《基于TPU平台实现超分辨率重建模型部署》方案中算法方案的说明。本作品算法模型选用的是Real-ESRGAN。Real-ESRGAN是基于ESRGAN(Enhanced Super-Resolution Generative Adversarial Networks)模型的改进版本。ESRGAN是一种生成对抗网络(GAN)架构,在图像超分辨率重建工作中取得了很好的效果。Real-ESRGAN在ESRGAN的基础上主要进行了两个方面的改进:一是引入了真实图像的训练集,二是优化了网络结构。
具体来说,Real-ESRGAN[1]的网络结构分为两个部分:生成器和判别器。生成器负责将低分辨率图像转换成高分辨率图像,判别器则用于评估生成器产生的图像与真实图像之间的相似度。通过对生成器和判别器进行交替训练,Real-ESRGAN可以不断优化生成器的性能,十七生成的高分辨率图像更加逼真。
Real-ESRGAN是在 ESRGAN的基础上使用纯合成数据来进行训练的,基本上就是通过模拟高分辨率图像变低分辩率过程中的各种退化,然后再通过低清图倒推出它的高清图。
本算法的模型部署方案包括模型转换和模型推理两个部分。其中模型转换使用了官方提供的tpu-mlir工具进行FP16和INT8模型转换和量化。模型部署使用的是算能提供的C++版本的 SophonSDK中的bmcv等加速库进行图像加载、数据前处理、模型推理、数据后处理等操作。
关键词
Real-ESRGAN,超分辨率,tpu-mlir,bmcv
1 超分算法原理
作为基本的low-level视觉问题,单图像超分辨率 (SISR) 越来越受到人们的关注。SISR的目标是从其低分辨率观测中重建高分辨率图像。目前已经提出了基于深度学习的方法的多种网络架构和超分网络的训练策略来改善 SISR的性能。顾名思义,SISR任务需要两张图片,一张高分辨率的 HR图和一张低分辨率的 LR图。超分模型的目的是根据后者生成前者,而退化模型的目的是根据前者生成后者。经典超分任务 SISR认为:低分辨率的LR图是由高分辨率的 HR图经过某种退化作用得到的,这种退化核预设为一个双三次下采样的模糊核 (downsampling blur kernel)。也就是说,这个下采样的模糊核是预先定义好的。但是,在实际应用中,这种退化作用十分复杂,不但表达式未知,而且难以简单建模。 双三次下采样的训练样本和真实图像之间存在一个域差。以双三次下采样为模糊核训练得到的网络在实际应用时,这种域差距将导致比较糟糕的性能。这种退化核未知的超分任务我们称之为盲超分任务 (Blind Super Resolution)。
令x和y分别代表HR和LR图片,退化模型为:
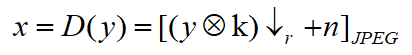
(1)
上式中, D(·)代表退化图片,ⓧ表示卷积操作,模型主要由三部分组成:模糊核k,下采样操作↓R和附加噪声n。[·]JPEG代表JPEG压缩,这种操作一般用于真实世界场景图片。盲图超分任务就是从LR图片恢复HR图片的过程。
2 模型部署方案
SophonSDK是算能科技基于其自主研发的 AI芯片所定制的深度学习 SDK,涵盖了神经网络推理阶段所需的模型优化、高效运行支持等能力,为深度学习应用开发和部署提供易用、高效的全栈式解决方案。
SophonSDK既兼容第三代BM1684芯片,也支持第四代BM1684X芯片。
2.1 模型转换
2.1.1 MLIR模型生成
首先将原始的Pytorch模型导出为onnx格式文件。然后使用官方提供的tpu-mlir工具链,对模型进行转换和量化。

图1模型转换命令
如图1所示,使用官方提供的脚本文件对导出的onnx模型进行转换。包括指定模型输出名字、模型输入名字、模型输入图像尺寸、图片类型、通道类型等参数。详细参数可以查询官方文档[2]。
2.1.2 生成量化校准表
转INT8模型前需要跑calibration, 得到校准表; 输入数据的数量根据情况准备100~1000张左右。然后用校准表, 生成对称或非对称bmodel。如果对称符合需求, 一般不建议用非对称, 因为 非对称的性能会略差于对称模型。

图2校准表生成命令
如图2所示,使用官方提供的脚本文件对转换后的mlir模型使用校准数据进行校准,生成对应的量化校准表。
2.1.3 编译为INT8量化模型
使用如下图所示的命令对模型进行INT8量化。

图3 INT8量化命令
编译完成后,会生成对应的量化模型文件。
2.2 模型部署
模型部署使用的是算能提供的C++版本的 SophonSDK中的bmcv等加速库进行图像加载、数据前处理、模型推理、数据后处理等操作[3]。
模型部署阶段参考官方的C++接口和python接口运行程序,使用的模型为量化后的INT8模型。查看统计前处理时间、推理时间、后处理时间。对应的batch size均为1。如下表所示:
| 测试平台 | 测试程序 | 前处理 | 推理 | 后处理 |
|---|---|---|---|---|
| BM1684X PCIe | Python | 16.49ms | 28.84ms | 95.35ms |
| BM1684X PCIe | C++ | 0.64ms | 26.33ms | 38.60ms |
表1 推理耗时对比
致谢
感谢DataFountain数联众创、算能提供的比赛平台给予从事AI行业的从业人员锻炼提升自己的机会。感谢大赛组委会的专业评判。感谢赛题交流群中各位老师的指导和帮助。
参考
[1] Wang X , Xie L , Dong C ,et al.Real-ESRGAN: Training Real-World Blind Super-Resolution with Pure Synthetic Data[J]. 2021.DOI:10.48550/arXiv.2107.10833.
[2] https://doc.sophgo.com/sdk-docs/v23.07.01/docs_latest_release/docs/SophonSDK_doc/zh/html/model_trans/3_mlir_fp32.html
[3] https://doc.sophgo.com/sdk-docs/v23.07.01/docs_latest_release/docs/bmcv/reference/html/bm_image/bm_image.html
这篇关于【2023 CCF 大数据与计算智能大赛】基于TPU平台实现超分辨率重建模型部署 基于Real-ESRGAN的TPU超分模型部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






