本文主要是介绍【大厂AI课学习笔记NO.71】AI算力芯片GPU/TPU等,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
AI算力芯片的发展历程
人工智能(AI)算力芯片的发展历程紧密地跟随着AI技术的发展脚步。从早期的基于传统中央处理器(CPU)的计算,到图形处理器(GPU)的广泛应用,再到专门为AI设计的处理器如神经处理单元(NPU)和张量处理单元(TPU)的出现,AI算力芯片不断演进,以满足日益增长的计算需求。
一、早期基于CPU的计算
在AI技术发展的初期,大部分的计算任务都是由CPU来完成的。CPU是计算机的核心部件,负责执行程序的指令,进行数据的处理和存储。然而,CPU的设计初衷是为了处理通用的计算任务,而不是针对AI中大量并行的矩阵运算进行优化。因此,在使用CPU进行AI计算时,往往会遇到计算效率低下的问题。
二、GPU的崛起
随着AI技术的快速发展,尤其是深度学习的兴起,对计算能力的需求急剧增加。GPU由于其并行处理的能力,逐渐在AI计算领域崭露头角。GPU最初是为了加速图形渲染而设计的,但其高度并行的架构也非常适合进行大规模的矩阵运算,这使得GPU成为深度学习训练的首选硬件。
三、专门为AI设计的处理器
尽管GPU在AI计算中表现出色,但人们仍在探索更加高效、更加专用的AI算力芯片。于是,NPU和TPU等专门为AI设计的处理器应运而生。
NPU(神经处理单元)是一种专门为神经网络计算设计的处理器。它通过对神经网络算法进行硬件级别的优化,实现了更高的计算效率和更低的功耗。NPU的出现极大地推动了边缘计算和移动设备上AI应用的发展。
TPU(张量处理单元)则是谷歌开发的一种专门为深度学习设计的定制芯片。TPU通过优化深度学习中常见的张量运算,实现了比传统硬件更高的计算性能和能效比。TPU在谷歌的云服务中得到了广泛应用,为大规模深度学习训练提供了强大的支持。
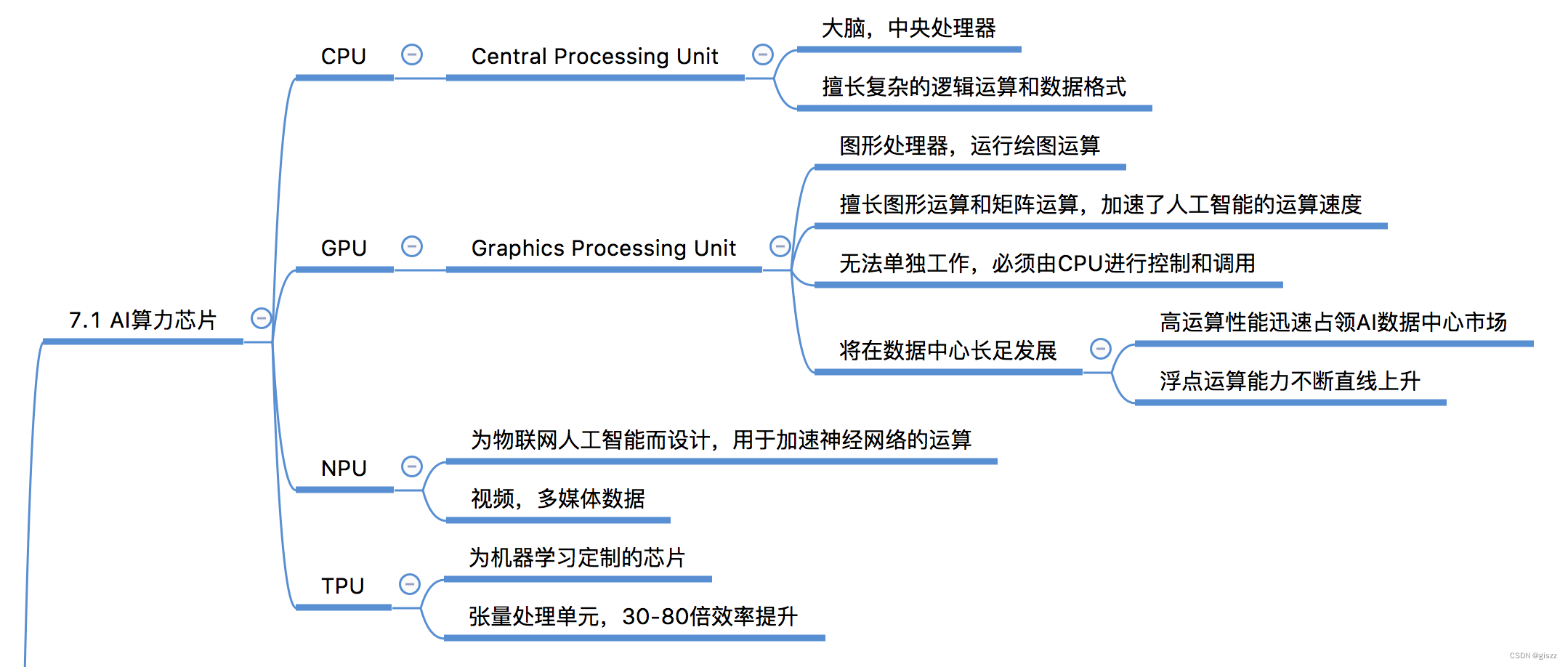
CPU、GPU、NPU、TPU的定义、原理、特性、优势、场景及异同点
1. CPU(中央处理器)
定义:CPU是电子计算机的主要设备之一,是计算机中的核心配件。其功能主要是解释计算机指令以及处理计算机软件中的数据。
原理:CPU从存储器或高速缓冲存储器中取出指令,放入指令寄存器,并对指令译码。它把指令分解成一系列的微操作,然后发出各种控制命令,执行微操作系列,从而完成一条指令的执行。
特性:通用性强,能执行多种类型的计算任务;但并行处理能力相对较弱。
优势:适用于复杂的逻辑控制和通用计算任务。
场景:日常办公、网页浏览等通用计算场景。
2. GPU(图形处理器)
定义:GPU是一种专门在个人电脑、工作站、游戏机和一些移动设备上进行图像运算工作的微处理器。
原理:GPU采用并行架构,拥有成百上千个核心,可以同时处理多个任务。它特别适合于处理大量的浮点运算和并行数据。
特性:并行处理能力强,适合进行大规模矩阵运算;功耗相对较高。
优势:在深度学习训练、游戏图形渲染等需要大量并行计算的场景中表现出色。
场景:深度学习训练、游戏、图形渲染等。
3. NPU(神经处理单元)
定义:NPU是一种专门为神经网络计算设计的处理器,通过对神经网络算法进行硬件级别的优化来实现高效计算。
原理:NPU采用针对神经网络优化的架构和指令集,能够高效执行神经网络中的各种运算,如卷积、池化等。
特性:高度优化神经网络计算,低功耗,适合移动设备和边缘计算场景。
优势:在神经网络推理任务中提供极高的性能和能效比。
场景:智能手机、无人机、自动驾驶汽车等边缘计算场景。
4. TPU(张量处理单元)
定义:TPU是一种专门为深度学习设计的定制芯片,通过优化深度学习中常见的张量运算来实现高性能计算。
原理:TPU采用针对张量运算优化的架构和指令集,能够高效执行深度学习中的矩阵乘法和卷积等运算。
特性:专门为深度学习优化,高性能和高能效比;但通用性相对较弱。
优势:在大规模深度学习训练和推理任务中提供卓越的性能。
场景:云服务、数据中心等需要进行大规模深度学习计算的场景。
异同点:
- 相同点:CPU、GPU、NPU和TPU都是用于计算的处理器,它们都能执行计算任务,只是优化的方向和适用的场景不同。
- 不同点:CPU是通用处理器,适用于各种计算任务;GPU擅长并行处理,适合大规模矩阵运算;NPU专门为神经网络优化,适合神经网络推理任务;TPU则专门为深度学习优化,适合大规模深度学习训练和推理。在性能和功耗方面,CPU通常性能较低但功耗较高;GPU性能较高但功耗也相对较高;NPU和TPU则针对特定任务进行了优化,实现了高性能和低功耗的平衡。
总结一下,就是:
- 算力:
- CPU:算力相对较低,因为其设计初衷是为了处理通用的计算任务,而不是针对AI中大量并行的矩阵运算进行优化。
- GPU:算力较高,由于其并行处理的能力,使得它在大规模矩阵运算方面表现出色,适用于深度学习训练等计算密集型任务。
- NPU:专门为神经网络计算设计的处理器,通过对神经网络算法进行硬件级别的优化,实现了更高的计算效率。
- TPU:专门为深度学习设计的定制芯片,通过优化深度学习中常见的张量运算,实现了比传统硬件更高的计算性能。
- 功耗:
- CPU:功耗相对较高,因为其需要处理各种复杂的逻辑控制和通用计算任务。
- GPU:功耗也相对较高,尤其在进行大规模并行计算时,需要消耗大量的电力。
- NPU:功耗较低,因为它专门针对神经网络进行了优化,实现了更高的能效比。
- TPU:功耗相对较低,因为它是专门为深度学习设计的,能够在保证性能的同时降低功耗。
由于不同芯片在设计和制造上的差异,以及任务类型的不同,很难给出一个具体的倍数关系来描述它们之间算力和功耗的对比。但是一般来说,在相同任务下,专门为AI设计的处理器(如NPU和TPU)往往能够在保证性能的同时实现更低的功耗。而CPU和GPU则可能在某些任务下表现出更高的功耗。
这里要注意的是:(考点)
GPU无法单独工作,必须由CPU进行控制和调用。
CPU擅长复杂的逻辑运算和数据格式,GPU浮点运算能力不断直线上升。
NPU视频,多媒体数据。
TPU张量处理单元,30-80倍效率提升。
这篇关于【大厂AI课学习笔记NO.71】AI算力芯片GPU/TPU等的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








